scrapy实战--爬取最新美剧
现在写一个利用scrapy爬虫框架爬取最新美剧的项目。
准备工作:
目标地址:http://www.meijutt.com/new100.html
爬取项目:美剧名称、状态、电视台、更新时间
1、创建工程目录
mkdir scrapyProject
cd scrapyProject
2、创建工程项目
scrapy startproject meiju100
cd meiju100
scrapy genspider meiju meijutt.com
3、查看目录结构
4、设置爬取项目(items.py)
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Meiju100Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
storyName = scrapy.Field()
storyState = scrapy.Field()
tvStation = scrapy.Field()
updateTime = scrapy.Field()
5、编写爬取脚本(meiju.py)
# -*- coding: utf-8 -*-
import scrapy
from meiju100.items import Meiju100Item class MeijuSpider(scrapy.Spider):
name = "meiju"
allowed_domains = ["meijutt.com"]
start_urls = ['http://www.meijutt.com/new100.html'] def parse(self, response):
items = []
subSelector = response.xpath('//ul[@class="top-list fn-clear"]/li')
for sub in subSelector:
item = Meiju100Item()
item['storyName'] = sub.xpath('./h5/a/text()').extract()
item['storyState'] = sub.xpath('./span[1]/font/text()').extract()
if item['storyState']:
pass
else:
item['storyState'] = sub.xpath('./span[1]/text()').extract()
item['tvStation'] = sub.xpath('./span[2]/text()').extract()
if item['tvStation']:
pass
else:
item['tvStation'] = [u'未知']
item['updateTime'] = sub.xpath('./div[2]/text()').extract()
if item['updateTime']:
pass
else:
item['updateTime'] = sub.xpath('./div[2]/font/text()').extract()
items.append(item)
return items
6、对爬取结果的处理
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import sys
reload(sys)
sys.setdefaultencoding('utf8') class Meiju100Pipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
fileName = today + 'movie.txt'
with open(fileName,'a') as fp:
fp.write(item['storyName'][0].encode("utf8") + '\t' + item['storyState'][0].encode("utf8") + '\t' + item['tvStation'][0] + '\t' + item['updateTime'][0] + '\n')
return item
7、设置settings.py
……
ITEM_PIPELINES = {'meiju100.pipelines.Meiju100Pipeline':1}
8、启动爬虫
scrapy crawl meiju
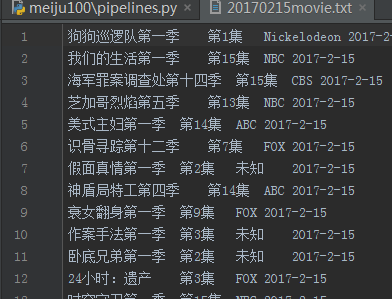
9、结果
10、代码下载
http://files.cnblogs.com/files/kongzhagen/meiju100.zip
scrapy实战--爬取最新美剧的更多相关文章
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- 如何提高scrapy的爬取效率
提高scrapy的爬取效率 增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置 ...
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
随机推荐
- Android 开发工具类 26_getFile
从网络获取可执行文件 public void getFile() throws Exception{ // 首先得到请求的路径 String urlpath = "http://ftpcnc ...
- jquery获取input的checked属性
1.经常需要判断某个按钮是否被选中. 2.基于jquery. <!DOCTYPE html> <html lang="en"> <head> & ...
- mysql 存储过程,函数,触发器
存储过程和函数 mysql> HELP CREATE PROCEDURE; Name: 'CREATE PROCEDURE' Description: Syntax: CREATE [DEFIN ...
- Redis笔记(四):Redis事务支持
Redis 事务 Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证: 批量操作在发送 EXEC 命令前被放入队列缓存. 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其 ...
- 机器学习--降维算法:PCA主成分分析
引言 当面对的数据被抽象为一组向量,那么有必要研究一些向量的数学性质.而这些数学性质将成为PCA的理论基础. 理论描述 向量运算即:内积.首先,定义两个维数相同的向量的内积为: (a1,a2,⋯,an ...
- Tomcat,JBoss与JBoss Web
最近接触到应用服务器JBoss,此外JBoss Web与Tomcat也同为web服务器,便查阅资料对三者进行比较,供大家参考. 一.Tomcat Tomcat 服务器是免费开源的Web 应用服务器.支 ...
- golang基础--func函数
函数function Go函数不支持 嵌套, 重载和默认参数 支持以下特性: 无须声明原型,不定长度长度变参,多返回值,命名返回值参数,匿名函数,闭包 定义函数使用关键字func,且左侧大括号不能另起 ...
- [codeup] 1128 出租车费
题目描述 某市出租车计价规则如下:起步4公里10元,即使你的行程没超过4公里:接下来的4公里,每公里2元:之后每公里2.4元.行程的最后一段即使不到1公里,也当作1公里计费. 一个乘客可以根据行程公里 ...
- 任务四十:UI组件之日历组件(一)
任务四十:UI组件之日历组件(一) 面向人群: 有一定基础的同学 难度: 中 重要说明 百度前端技术学院的课程任务是由百度前端工程师专为对前端不同掌握程度的同学设计.我们尽力保证课程内容的质量以及学习 ...
- [转]C#综合揭秘——Entity Framework 并发处理详解
本文转自:http://www.cnblogs.com/leslies2/archive/2012/07/30/2608784.html 引言 在软件开发过程中,并发控制是确保及时纠正由并发操作导致的 ...