scrapy实战--爬取最新美剧
现在写一个利用scrapy爬虫框架爬取最新美剧的项目。
准备工作:
目标地址:http://www.meijutt.com/new100.html
爬取项目:美剧名称、状态、电视台、更新时间
1、创建工程目录
mkdir scrapyProject
cd scrapyProject
2、创建工程项目
scrapy startproject meiju100
cd meiju100
scrapy genspider meiju meijutt.com
3、查看目录结构
4、设置爬取项目(items.py)
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Meiju100Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
storyName = scrapy.Field()
storyState = scrapy.Field()
tvStation = scrapy.Field()
updateTime = scrapy.Field()
5、编写爬取脚本(meiju.py)
# -*- coding: utf-8 -*-
import scrapy
from meiju100.items import Meiju100Item class MeijuSpider(scrapy.Spider):
name = "meiju"
allowed_domains = ["meijutt.com"]
start_urls = ['http://www.meijutt.com/new100.html'] def parse(self, response):
items = []
subSelector = response.xpath('//ul[@class="top-list fn-clear"]/li')
for sub in subSelector:
item = Meiju100Item()
item['storyName'] = sub.xpath('./h5/a/text()').extract()
item['storyState'] = sub.xpath('./span[1]/font/text()').extract()
if item['storyState']:
pass
else:
item['storyState'] = sub.xpath('./span[1]/text()').extract()
item['tvStation'] = sub.xpath('./span[2]/text()').extract()
if item['tvStation']:
pass
else:
item['tvStation'] = [u'未知']
item['updateTime'] = sub.xpath('./div[2]/text()').extract()
if item['updateTime']:
pass
else:
item['updateTime'] = sub.xpath('./div[2]/font/text()').extract()
items.append(item)
return items
6、对爬取结果的处理
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import sys
reload(sys)
sys.setdefaultencoding('utf8') class Meiju100Pipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
fileName = today + 'movie.txt'
with open(fileName,'a') as fp:
fp.write(item['storyName'][0].encode("utf8") + '\t' + item['storyState'][0].encode("utf8") + '\t' + item['tvStation'][0] + '\t' + item['updateTime'][0] + '\n')
return item
7、设置settings.py
……
ITEM_PIPELINES = {'meiju100.pipelines.Meiju100Pipeline':1}
8、启动爬虫
scrapy crawl meiju
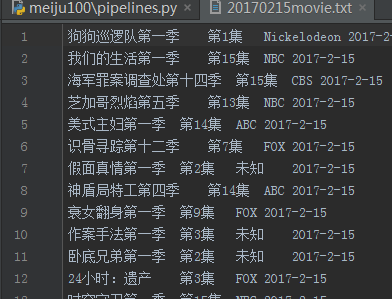
9、结果
10、代码下载
http://files.cnblogs.com/files/kongzhagen/meiju100.zip
scrapy实战--爬取最新美剧的更多相关文章
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- 如何提高scrapy的爬取效率
提高scrapy的爬取效率 增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置 ...
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
随机推荐
- Delphi基础语法
1.LowerCase(const s:string):string.UpperCase(const s:string):string 2.CompareStr(const s1,s2:string) ...
- springboot-8- 日志配置
1, logback配置 springboot 默认支持logback, 自动加载classpath:logback-spring.xml <!-- logback多文件输出 --> &l ...
- springboot-3-其他配置
1, 热部署: 有jrebel的话, 不用了, 不如jre好用 原理: 使用两个classLoad, 一个加载不改变的jar, 另一个加载可更改的jar, 发生改变后, 舍弃可更改的jar重新rest ...
- java的PreparedStatement中使用like时的问题
SQL:select * from students where name like '%tommy%'; 正常的sql如上,是可以直接执行的, 那放到java的P热怕热的Statement中就应该是 ...
- Ceph 块设备 - 命令,快照,镜像
目录 一.Ceph 块设备 二.块设备 rbd 命令 三.操作内核模块 四.快照基础 rbd snap 五.分层快照 六.镜像 rbd mirror 七.QEMU 八.libvirt 九.Openst ...
- Linux中终端和控制台的一些不成熟的理解
首先声明,这仅仅是在下一些不成熟的想法.是通过看网上的一些资料和自己实践的一些心得,应该都是些很不成熟甚至是不太正确的想法.但是我还是想记录下来,算是一个心路历程吧.等以后成熟了,再来修改. 首先说一 ...
- linux下软、硬链接的创建和删除
linux下软.硬链接的创建和删除 在Linux系统中,内核为每一个新创建的文件分配一个Inode(索引结点),每个文件都有一个惟一的inode号.文件属性保存在索引结点里,在访问文件时,索引结点被复 ...
- eclipse 中文件引用报错不能编译,但引用文件确实存在
方法1:clean工程 方法2: 检查.classpath文件中该引用文件是否被排除在外.
- Percona-mysql server 5.5升级5.6
http://blog.csdn.net/lqx0405/article/details/50162557 系统环境: 操作系统:CentOS_6.5(64) My ...
- 实现Vue 的 markdown 文档可以在线运行(vue-markdown-run)
闲暇时间我用Vue框架写了一个博客,编辑器是用的markdown文本的形式,介绍性+描述完全能满足我的需求,但是,如果想在线运行我markdown文本中的Vue组件代码,则无法实现了, 于是我就自己写 ...