hadoop2.7.2完全分布式环境搭建

<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop/tmp/</value>
<description> Abase for other temporary directories</description> </property> <property>
<name>fs.defaultFS</name>
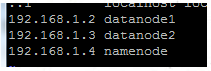
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>namenode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>namenode:50090</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/hadoop/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>namenode:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>namenode:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>namenode:19888</value>
</property>
<property>
<!--see job-->
<name>mapred.job.tracker</name>
<value>namenode:9001</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux.services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>namenode:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>namenode:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>namenode:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>namenode:8033</value>
</property>
<property>
<name>yarn.resourcemanager.web.address</name>
<value>namenode:8088</value>
</property>
</configuration>
hadoop2.7.2完全分布式环境搭建的更多相关文章
- Hadoop-2.4.1完全分布式环境搭建
Hadoop-2.4.1完全分布式环境搭建 Hadoop-2.4.1完全分布式环境搭建 一.配置步骤如下: 主机环境搭建,这里是使用了5台虚拟机,在ubuntu 13系统上进行搭建hadoop ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hadoop2.4.1伪分布式环境搭建
注意:所有的安装用普通哟用户安装,所以首先使普通用户可以以sudo执行一些命令: 0.虚拟机中前期的网络配置参考: http://www.cnblogs.com/qlqwjy/p/7783253.ht ...
- Hadoop2.8.1完全分布式环境搭建
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三 ...
- 32位Ubuntu12.04搭建Hadoop2.5.1完全分布式环境
准备工作 1.准备安装环境: 4台PC,均安装32位Ubuntu12.04操作系统,统一用户名和密码 交换机1台 网线5根,4根分别用于PC与交换机相连,1根网线连接交换机和实验室网口 2.使用ifc ...
- hadoop学习(三)----hadoop2.x完全分布式环境搭建
今天我们来完成hadoop2.x的完全分布式环境搭建,话说学习本来是一件很快乐的事情,可是一到了搭环境就怎么都让人快乐不起来啊,搭环境的时间比学习的时间还多.都是泪.话不多说,走起. 1 准备工作 开 ...
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
随机推荐
- Oracle11G 在线重定义
create tablespace tbs1 datafile '/opt/oracle/oradata/haier/tbs1.dbf' size 500m autoextend on maxsize ...
- iOS oc和swift中协议的使用
创建一个空的工程 在工程中我们新建一个类 继承与NSObject 定义一个协议‘ @protocol UpdateAlertDelegate <NSObject> //这里的红色字体就是我 ...
- python访问sqlserver
#coding=utf-8 #!/usr/bin/env python#---------------------------------------------------------------- ...
- NodeJS异步I/O解析
在现在的项目开发中,任何一个大型项目绝对不是简简单单的采用一个种语言和一种框架,因为每种语言和框架各有优势,与其死守一个,不与取各家之所长,依次得到一个高性能.搞扩展的产品. 对于一个.NET开发者, ...
- Bootstrap入门(二十五)JS插件2:过渡效果
Bootstrap入门(二十五)JS插件2:过渡效果 对于简单的过渡效果,只需将 transition.js 和其它 JS 文件一起引入即可.如果你使用的是编译(或压缩)版的bootstrap.js ...
- easyui datagrid的json格式
easyui datagrid的json格式: {"columns":[[{"field":"one","title": ...
- 在C语言中以编程的方式获取函数名
仅仅为了获取函数名,就在函数体中嵌入硬编码的字符串,这种方法单调乏味还易导致错误,不如看一下怎样使用新的C99特性,在程序运行时获取函数名吧. 对象反射库.调试工具及代码分析器,经常会需要在运行时访问 ...
- oracle_plseq客户端中文乱码
1.登陆plsql,执行sql语句,输出的中文标题显示成问号????:条件包含中文,则无数据输出 输入sql语句select * from V$NLS_PARAMETERS查看字符集,查看第一行val ...
- db2_merge
DB2 MERGE INTO语句的使用 DB2中的Merge语句可以将一个表中的数据合并到另一个表中,在合并的同时可以根据条件进行插入.删除.更新等操作,功能非常强大. 语法如下:www.2c ...
- git命令实战之血泪记录
注意: 本文章所写所有命令均在Git命令行窗口执行!非cmd窗口! 打开git命令行窗口步骤为:到项目根目录下执行bash命令行操作:右键点击Git Bash Here菜单,打开git命令窗口,不是c ...