Spark使用Java读取mysql数据和保存数据到mysql
原文引自:http://blog.csdn.net/fengzhimohan/article/details/78471952
项目应用需要利用Spark读取mysql数据进行数据分析,然后将分析结果保存到mysql中。
开发环境:
java:1.8
IDEA
spark:1.6.2
一.读取mysql数据
1.创建一个mysql数据库
user_test表结构如下:
create table user_test (
id int(11) default null comment "id",
name varchar(64) default null comment "用户名",
password varchar(64) default null comment "密码",
age int(11) default null comment "年龄"
)engine=InnoDB default charset=utf-8;
2.插入数据
insert into user_test values(12, 'cassie', '123456', 25);
insert into user_test values(11, 'zhangs', '1234562', 26);
insert into user_test values(23, 'zhangs', '2321312', 27);
insert into user_test values(22, 'tom', 'asdfg', 28);
3.创建maven工程,命名为Test,添加java类SparkMysql
添加依赖包
pom文件内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>SparkSQL</groupId>
<artifactId>com.sparksql.test</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.24</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency> </dependencies> </project>
4.编写spark代码
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext; import java.util.Properties; /**
* Created by Administrator on 2017/11/6.
*/
public class SparkMysql {
public static org.apache.log4j.Logger logger = org.apache.log4j.Logger.getLogger(SparkMysql.class); public static void main(String[] args) {
JavaSparkContext sparkContext = new JavaSparkContext(new SparkConf().setAppName("SparkMysql").setMaster("local[5]"));
SQLContext sqlContext = new SQLContext(sparkContext);
//读取mysql数据
readMySQL(sqlContext); //停止SparkContext
sparkContext.stop();
}
private static void readMySQL(SQLContext sqlContext){
//jdbc.url=jdbc:mysql://localhost:3306/database
String url = "jdbc:mysql://localhost:3306/test";
//查找的表名
String table = "user_test";
//增加数据库的用户名(user)密码(password),指定test数据库的驱动(driver)
Properties connectionProperties = new Properties();
connectionProperties.put("user","root");
connectionProperties.put("password","123456");
connectionProperties.put("driver","com.mysql.jdbc.Driver"); //SparkJdbc读取Postgresql的products表内容
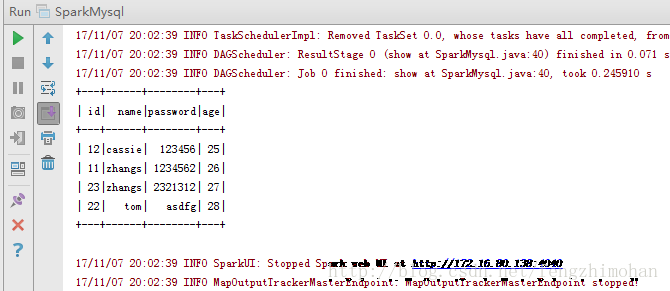
System.out.println("读取test数据库中的user_test表内容");
// 读取表中所有数据
DataFrame jdbcDF = sqlContext.read().jdbc(url,table,connectionProperties).select("*");
//显示数据
jdbcDF.show();
}
}
运行结果:
二.写入数据到mysql中
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType; import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties; /**
* Created by Administrator on 2017/11/6.
*/
public class SparkMysql {
public static org.apache.log4j.Logger logger = org.apache.log4j.Logger.getLogger(SparkMysql.class); public static void main(String[] args) {
JavaSparkContext sparkContext = new JavaSparkContext(new SparkConf().setAppName("SparkMysql").setMaster("local[5]"));
SQLContext sqlContext = new SQLContext(sparkContext);
//写入的数据内容
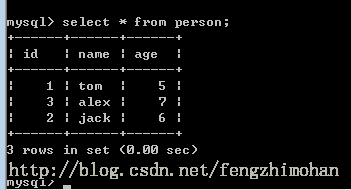
JavaRDD<String> personData = sparkContext.parallelize(Arrays.asList("1 tom 5","2 jack 6","3 alex 7"));
//数据库内容
String url = "jdbc:mysql://localhost:3306/test";
Properties connectionProperties = new Properties();
connectionProperties.put("user","root");
connectionProperties.put("password","123456");
connectionProperties.put("driver","com.mysql.jdbc.Driver");
/**
* 第一步:在RDD的基础上创建类型为Row的RDD
*/
//将RDD变成以Row为类型的RDD。Row可以简单理解为Table的一行数据
JavaRDD<Row> personsRDD = personData.map(new Function<String,Row>(){
public Row call(String line) throws Exception {
String[] splited = line.split(" ");
return RowFactory.create(Integer.valueOf(splited[0]),splited[1],Integer.valueOf(splited[2]));
}
}); /**
* 第二步:动态构造DataFrame的元数据。
*/
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true));
structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true));
structFields.add(DataTypes.createStructField("age",DataTypes.IntegerType,true)); //构建StructType,用于最后DataFrame元数据的描述
StructType structType = DataTypes.createStructType(structFields); /**
* 第三步:基于已有的元数据以及RDD<Row>来构造DataFrame
*/
DataFrame personsDF = sqlContext.createDataFrame(personsRDD,structType); /**
* 第四步:将数据写入到person表中
*/
personsDF.write().mode("append").jdbc(url,"person",connectionProperties); //停止SparkContext
sparkContext.stop();
}
}
运行结果:
Spark使用Java读取mysql数据和保存数据到mysql的更多相关文章
- Learning Spark中文版--第五章--加载保存数据(2)
SequenceFiles(序列文件) SequenceFile是Hadoop的一种由键值对小文件组成的流行的格式.SequenceFIle有同步标记,Spark可以寻找标记点,然后与记录边界重新 ...
- spark通过JDBC读取外部数据库,过滤数据
官网链接: http://spark.apache.org/docs/latest/sql-programming-guide.html#jdbc-to-other-databases http:// ...
- Learning Spark中文版--第五章--加载保存数据(1)
开发工程师和数据科学家都会受益于本章的部分内容.工程师可能希望探索更多的输出格式,看看有没有一些适合他们下游用户的格式.数据科学家可能会更关注他们已经使用的数据格式. Motivation 我 ...
- Android开发学习---android下的数据持久化,保存数据到rom文件,android_data目录下文件访问的权限控制
一.需求 做一个类似QQ登录似的app,将数据写到ROM文件里,并对数据进行回显. 二.截图 登录界面: 文件浏览器,查看文件的保存路径:/data/data/com.amos.datasave/fi ...
- Python学习_从文件读取数据和保存数据
运用Python中的内置函数open()与文件进行交互 在HeadFirstPython网站中下载所有文件,解压后以chapter 3中的“sketch.txt”为例: 新建IDLE会话,首先导入os ...
- java读取记事本文件的部分数据添加到mysql
package com.tideway.readtxt; import java.io.BufferedReader; import java.io.FileInputStream; import j ...
- Java 读取Excel内容并保存进数据库
读取Excel中内容,并保存进数据库 步骤 建立数据库连接 读取文件内容 (fileInputStream 放进POI的对应Excel读取接口,实现Excel文件读取) 获取文件各种内容(总列数,总行 ...
- JAVA读取TXT文本中的数据
现在在Demo.txt中存在数据: ABC 需要将ABC从文本文件中读取出来 代码片: import java.io.*; class FileReaderDemo { public static v ...
- Java读取Excel指定列的数据详细教程和注意事项
本文使用jxl.jar工具类库实现读取Excel中指定列的数据. jxl.jar是通过java操作excel表格的工具类库,是由java语言开发而成的.这套API是纯Java的,并不依赖Windows ...
随机推荐
- RabbitMq--2--安装
简单说下个人的理解,mq就是一个消息代理,负责异步消息转发,可以很大程度缓解服务器压力,并且防止服务器宕机影响业务等. 安装: 环境:centos7 1).首先需要安装erlang #wget htt ...
- Using-JSONNET-for-dynamic-JSON-parsing
原文 https://weblog.west-wind.com/posts/2012/Aug/30/Using-JSONNET-for-dynamic-JSON-parsing With the re ...
- vue证明题三,vue项目的包结构和配置
用vue-cli创建的项目带有自动配置好的包结构,包结构都是固定的. 关于详细的解释,网上多得是,只说下最重要的内容 1.vue项目包结构和端口号配置 这里笔者下了个HBuilderX来写代码. 2. ...
- document.location window.location
document.location 和 window.location 取url的值的时候可以通用,但是 document是window的属性,所以不能直接用document.location =ur ...
- Vue小白篇 - Vue 的指令系统 (1) v-text、v-html
v-text:相当于innerText v-html:相当于innerHTML <div id="box"> {{ msg }} <div v-text=&quo ...
- WPFの多屏幕问题
public MainWindow(string sysName, int timeState) { InitializeComponent(); //查找当前屏幕数量 ) { Dispatcher. ...
- 链表反转&交换链表结点
leetcode链表反转链接 要求摘要: 反转一个单链表 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1-&g ...
- web storage 简单的网页留言版
html <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <ti ...
- MAT内存分析
先下载 http://www.eclipse.org/mat/downloads.php 配置环境参数 分析一个堆转储文件需要消耗很多的堆空间,为了保证分析的效率和性能,在有条件的情况下,建议分配给 ...
- PHP curl_multi_init函数
curl_multi_init — 返回一个新cURL批处理句柄 说明 resource curl_multi_init ( void ) 允许并行地处理批处理cURL句柄. 参数 此函数没有参数. ...