Redis Cluster in Ubuntu
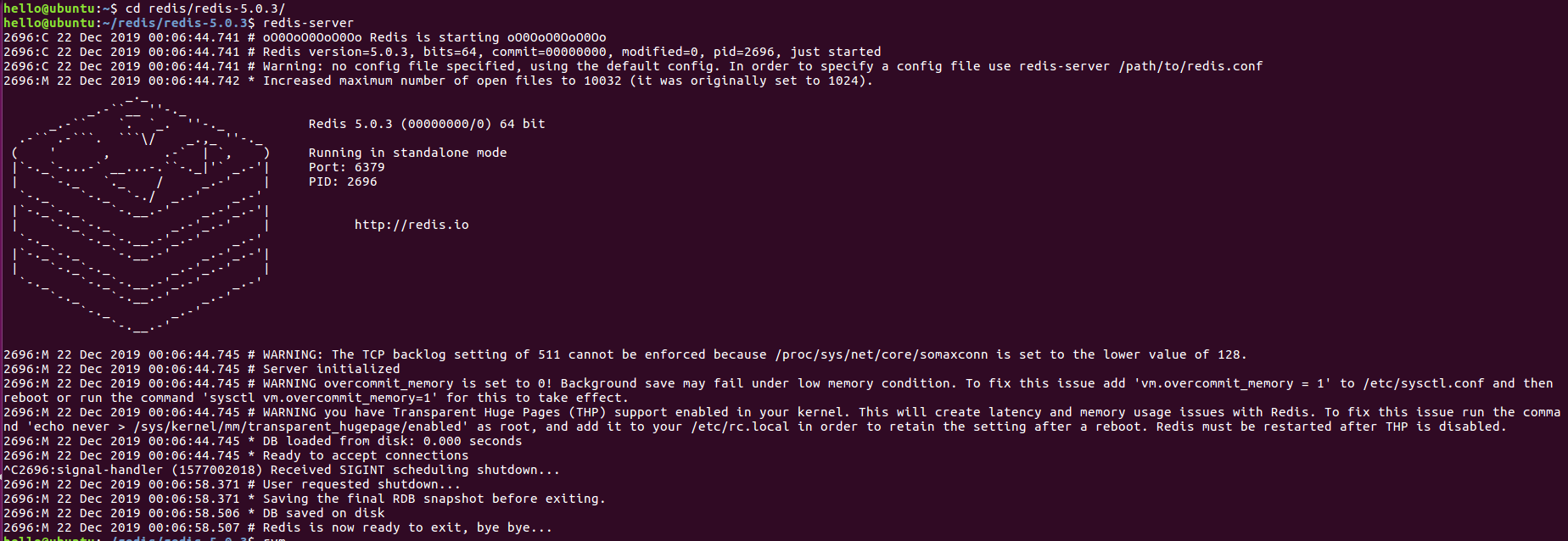
1. 首先,进到Redis-server 的位置,确认 Redis server 可以正常启动
2. 在 redis-5.0.3 目录下创建文件夹 redisCluster_Demo_byMe,并在 redisCluster_Demo_byMe 目录下创建名为 8001 - 8006 的 6 个文件夹


3. 复制 redis.conf 文件到 redisCluster_Demo_byMe 目录下名为 8001 - 8006 的 6 个文件夹内

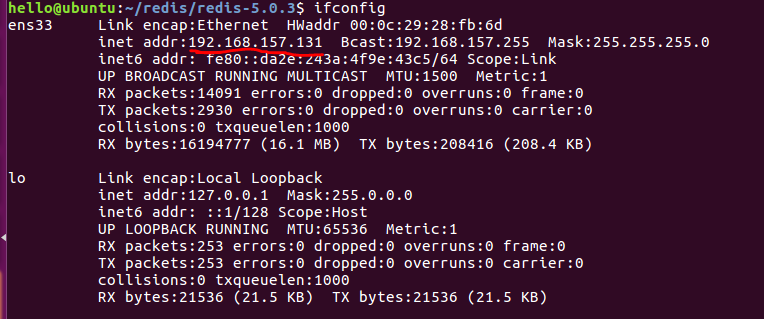
4. 查看IP地址
5. 修改redisCluster_Demo_byMe 目录下名为 8001 - 8006 的 6 个文件夹内的redis.conf 配置文件,注意端口的变化
如果文件夹名为8001 则 port / pidfile / cluster-config-file 中的端口则改为对应的8001,其他文件夹下的配置文件以此修改。
port 8001 //端口8002,8003,8004,8005,8006
bind 本机ip (通过ifconfig 查出的IP地址 //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群
daemonize yes //redis后台运行
pidfile /var/run/redis_8001.pid //pidfile文件对应8002,8003,8004,8005,8006
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_8001.conf //集群的配置 配置文件首次启动自动生成 8001,8003,8004,8005,8006
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
6. 依次启动 6 个节点



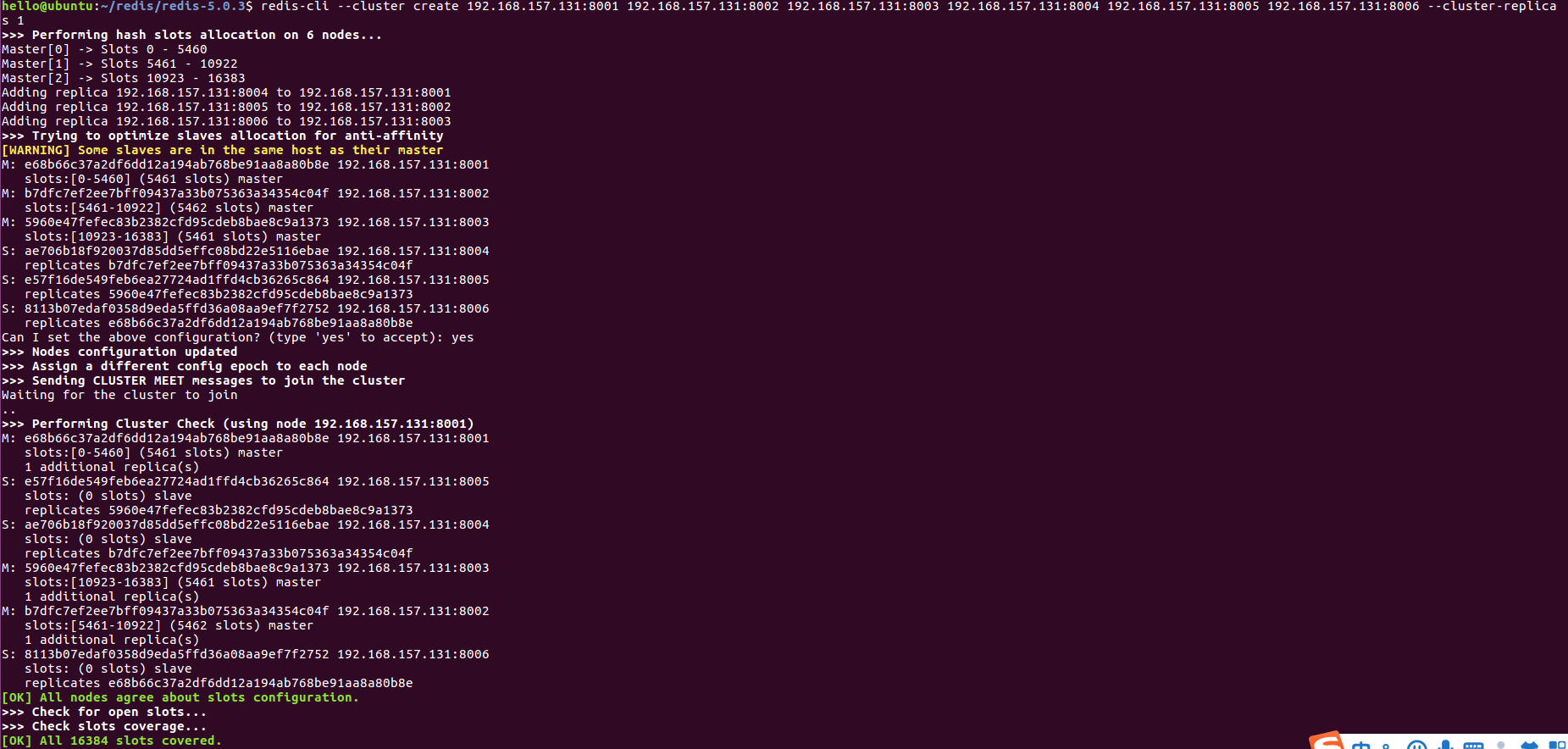
7. 使用命令创建Redis集群
redis-cli --cluster create 192.168.157.131:8001 192.168.157.131:8002 192.168.157.131:8003 192.168.157.131:8004 192.168.157.131:8005 192.168.157.131:8006 --cluster-replicas 1
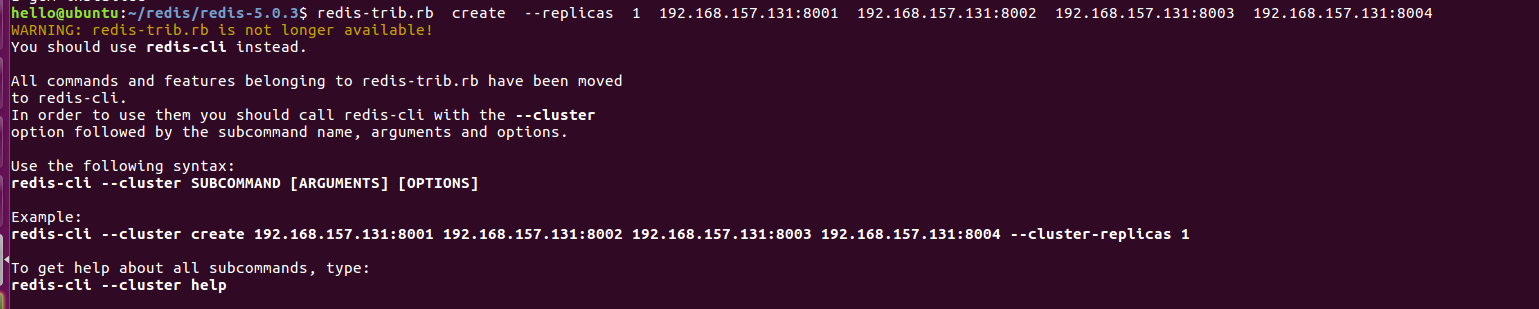
注意,创建集群的时候,不需要使用 redis-trib.rb,请看如下提示
并且创建集群的时候至少需要 6 个节点,请看如下提示

8. 测试 Redis 集群
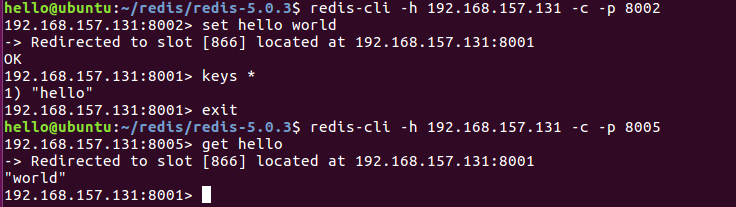

9. 为Redis集群添加 master 节点
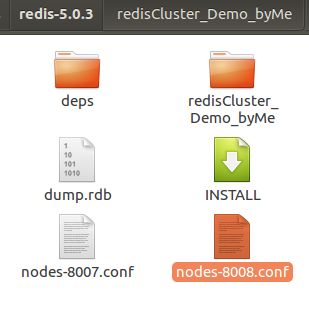
首先启动节点: redis-server redisCluster_Demo_byMe/8008/redis.conf
将启动的节点作为 master 节点添加:
redis-cli --cluster add-node 192.168.157.131:8008 192.168.157.131:8001 --cluster-master-id 8b1169eba78f649da0a6eec41485ecbeaa8daa52
8b1169eba78f649da0a6eec41485ecbeaa8daa52 该 ID可以在如下的 node-8008.conf 文件中查看。

对主节点的 slot 重新分配:
redis-cli --cluster reshard 192.168.157.131:8001
reshard 后的参数是Redis集群中的任意一个实例。
将 192.168.157.131:8001 节点的 1000 个 slot 移动到 192.168.157.131:8008 节点

可以看到slot 移动成功

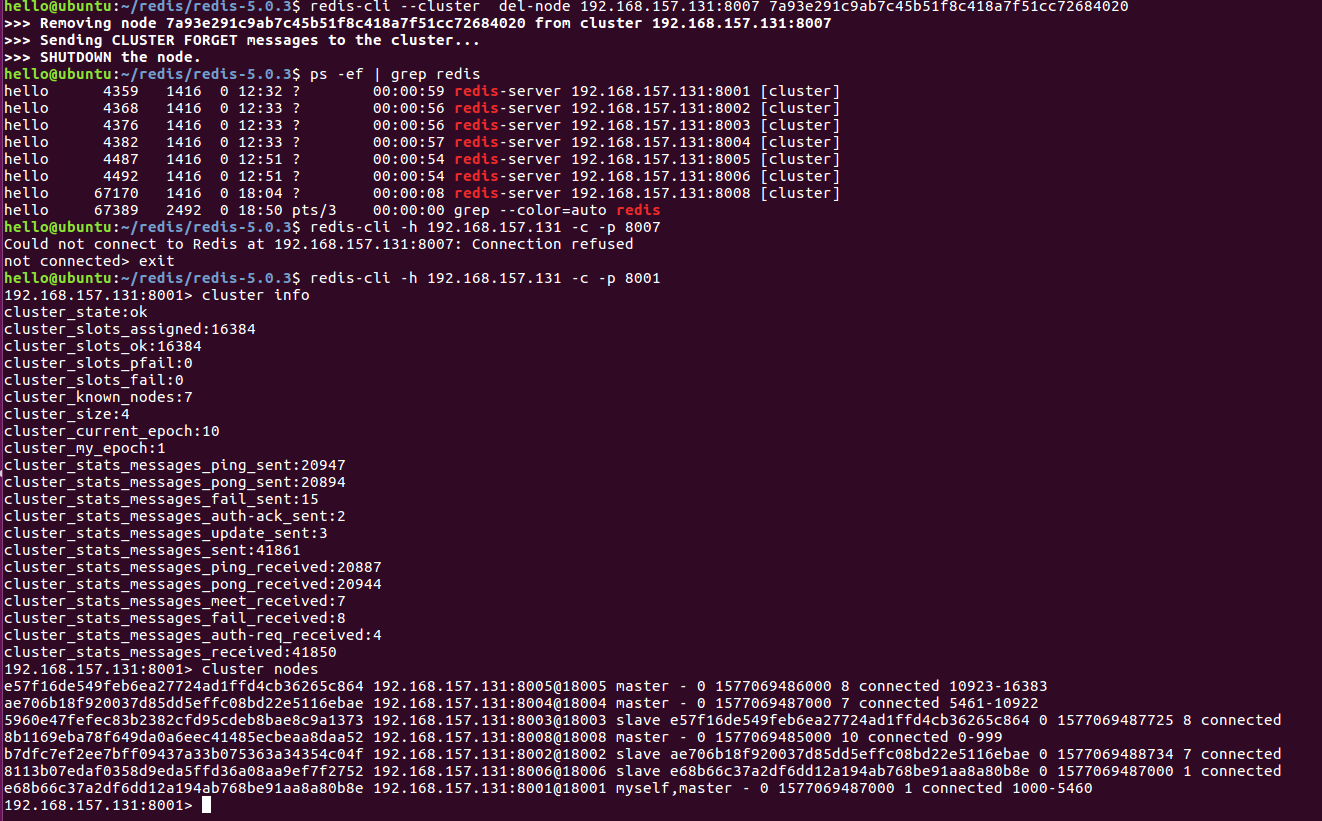
10. 演示删除 如下 slave 节点

删除 slave 节点
redis-cli --cluster del-node 192.168.157.131:8007 7a93e291c9ab7c45b51f8c418a7f51cc72684020
参考链接: https://www.cnblogs.com/xwgcxk/p/10775805.html
Redis Cluster in Ubuntu的更多相关文章
- How To Configure a Redis Cluster on Ubuntu 14.04
原文:https://www.digitalocean.com/community/tutorials/how-to-configure-a-redis-cluster-on-ubuntu-14-04 ...
- Redis Cluster with SpringBoot
前提: 按照 https://www.cnblogs.com/luffystory/p/12081074.html 配置好Redis Cluster in Ubuntu 按照如下结构搭建项目结构: P ...
- Ubuntu 15.10 下Redis Cluster使用
1 Redis Standalone安装 可以参考这篇博文:http://www.cnblogs.com/_popc/p/3684835.html 2 Redis Cluster安装 2.1 环境介绍 ...
- Ubuntu 15.10 下Scala 操作Redis Cluster
1 前言 Redis Standalone,Redis Cluster的安装在前面介绍过,地址:http://www.cnblogs.com/liuchangchun/p/5063477.html,这 ...
- Ubuntu 16.04下Redis Cluster集群搭建(官方原始方案)
前提:先安装好Redis,参考:http://www.cnblogs.com/EasonJim/p/7599941.html 说明:Redis Cluster集群模式可以做到动态增加节点和下线节点,使 ...
- Ubuntu 16.04 下Redis Cluster集群搭建
实际操作如下: 准备工作 版本:4.0.2 下载地址:https://redis.io/download 离线版本:(链接: https://pan.baidu.com/s/1bpwDtOr 密码: ...
- Redis Cluster部署、管理和测试
背景: Redis 3.0之后支持了Cluster,大大增强了Redis水平扩展的能力.Redis Cluster是Redis官方的集群实现方案,在此之前已经有第三方Redis集群解决方案,如Twen ...
- Redis Cluster集群搭建与应用
1.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper,但从redis 3.0之后版本支持redis-cluster集群,redis-cluster采用无中心结 ...
- Redis(十)集群:Redis Cluster
一.数据分布 1.数据分布理论 2.Redis数据分区 Redis Cluser采用虚拟槽分区,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot=CRC16(key)&16 ...
随机推荐
- Linux实用命令及技巧
1. 查看CPU及内存使用排行 1)查看当前CPU及内存的整体使用情况 top 2)可以使用以下命令查使用内存最多的10个进程 ps -aux | sort -k4nr | head -n 10 3 ...
- Springboot提示数据库连接问题Connection is not available
2019-05-29 11:19:51.824 WARN 854 --- [io-8080-exec-10] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL ...
- node工具之http-proxy-middleware
简介 一个轻松的配置代理服务器的中间件,让Node.js代理变得简单 url路径 foo://example.com:8042/over/there?name=ferret#nose \_/ \___ ...
- Go项目目录管理
在Go的官网文档How to Write Go Code中,已经介绍了Go的项目目录一般包含以下几个: src 包含项目的源代码文件: pkg 包含编译后生成的包/库文件: bin 包含编译后生成的可 ...
- Linux Exploit系列之七 绕过 ASLR -- 第二部分
原文地址:https://github.com/wizardforcel/sploitfun-linux-x86-exp-tut-zh/blob/master/7.md 这一节是简单暴力的一节,作者讲 ...
- 写两个线程,一个线程打印1-52,另一个线程打印A-Z,打印顺序为12A34B56C......5152Z
题目: 写两个线程,一个线程打印1-52,另一个线程打印A-Z,打印顺序为12A34B56C......5152Z.要求用线程间的通信. /** * 写两个线程,第一个线程打印1-52,第二个线程打印 ...
- 自己实现一个简化版的SpringMVC框架
废话不多说,我们进入今天的正题,在Web应用程序设计中,MVC模式已经被广泛使用.SpringMVC以DispatcherServlet为核心,负责协调和组织不同组件以完成请求处理并返回响应的工作,实 ...
- python爬去虎扑数据信息,完成可视化
首先分析虎扑页面数据 如图我们所有需要的数据都在其中所以我们获取需要的内容直接利用beaitifulsoupui4``` soup.find_all('a',class_ ...
- 关于fastJson的几个问题
1.将对象中为null的属性也给序列化出来 可以使用SerializaerFeature实现 JSON.toJSONString(gas, SerializerFeature.WriteMapNull ...
- sklearn学习小结
机器学习的一般流程: 1.获取数据 2.数据预处理 3.数据集分拆 4.搭建模型 5.模型评估 6.模型保存 7.模型优化 接下来,以Sklearn为例,一一介绍. 1.获取数据 1.1.导入数据集: ...