knn原理及借助电影分类实现knn算法
KNN最近邻算法原理
import pandas as pd
import numpy as np def distance(v1, v2):
"""
距离计算
:param v1:点1
:param v2: 点2
:return: 距离
"""
dist = np.sqrt(np.sum(np.power((v1 - v2), )))
return dist # 加载数据
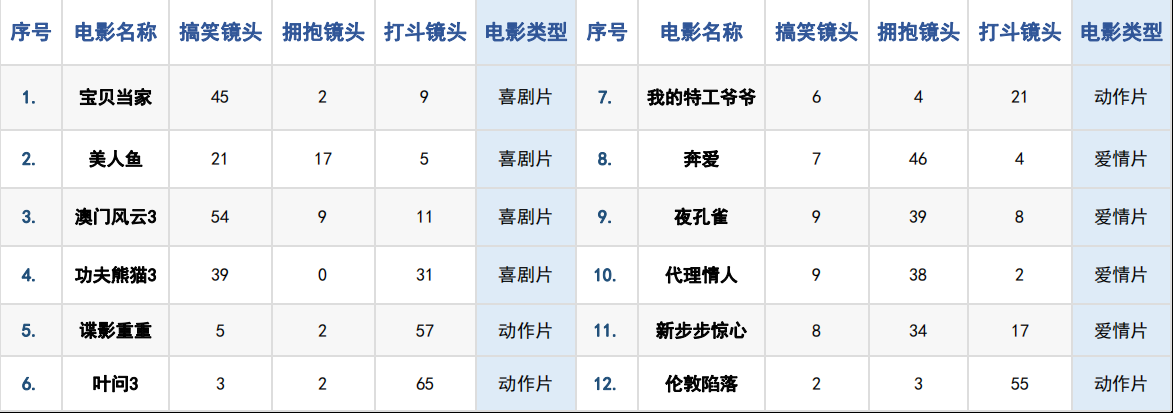
data = pd.read_excel("./电影分类数据.xlsx")
print("data:\n", data)
print("*" * )
# 获取训练集
train = data.iloc[:, :]
print("train:\n", train)
# 获取训练集的特征值 与目标值
train_x = train.iloc[:, :-]
train_y = train.iloc[:, -]
# 获取测试集
print("*" * )
test = data.columns[-:]
print("test:\n", test) # 进行计算距离
# 循环计算训练集每一个样本与测试集的距离
for i in range(train.shape[]): # 计算距离
dist = distance(train_x.iloc[i,:],test[:]) train.loc[i,'dist'] = dist print(train)
# 对距离按照升序进行排序
train.sort_values(by='dist',inplace=True)
print("*" * )
print("排序后的train:\n",train) # 确定K 值 k值不同结果不同
k =
res = train.loc[:,'电影类型'][:k].mode()[]
print("*" * )
print(res)
knn原理及借助电影分类实现knn算法的更多相关文章
- 机器学习实战1-1 KNN电影分类遇到的问题
为什么电脑排版效果和手机排版效果不一样~ 目前只学习了python的基础语法,有些东西理解的不透彻,希望能一边看<机器学习实战>,一边加深对python的理解,所以写的内容很浅显,也许还会 ...
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- kNN(K-Nearest Neighbor)最近的分类规则
KNN最近的规则,主要的应用领域是未知的鉴定,这一推断未知的哪一类,这样做是为了推断.基于欧几里得定理,已知推断未知什么样的特点和最亲密的事情特性: K最近的邻居(k-Nearest Neighbor ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 【数据挖掘】分类之kNN(转载)
[数据挖掘]分类之kNN 1.算法简介 kNN的思想很简单:计算待分类的数据点与训练集所有样本点,取距离最近的k个样本:统计这k个样本的类别数量:根据多数表决方案,取数量最多的那一类作为待测样本的类别 ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
随机推荐
- python实现不同条件下单据体的颜色不一样,比如直接成本分析表中关闭的细目显示为黄色
#引入clr运行库 import clr #添加对cloud插件开发的常用组件的引用 clr.AddReference('Kingdee.BOS') clr.AddReference('Kingdee ...
- 谈谈CS英文论文写作
作为一个CS的研究生,发篇文章是你毕业的必要条件.现如今,学校对于文章的要求也越来越高,一般来说,还是国外的期刊或者会议更加受到认可,这样对于毕业也有好处.因此,以我自己的感受来说,论文的写作以及表达 ...
- CtfStudying之SSH私钥泄露
8/23/19 SSH私钥泄露 对于只是给定一个对应ip地址的靶场机器,我们需要对其进行扫描,探测其开放服务.我原来理解的渗透就是找到目标的漏洞,然后利用这些(这种)漏洞,最后拿到机器的最高权限:其实 ...
- SVG 学学就会了。
SVG 随便学学就会了 这两天闲来没事把 Echart 换成 Rechart 感觉世界都清爽了.因为 rechart 使用 svg 来渲染,所以顺带学了下 SVG 感觉很轻松哦. 概念 SVG 是 w ...
- java调用sqlldr报错:Message 2100 not found
java调用Oracle的sqlldr命令报错:Message 2100 not found; No message file for product=RDBMS, facility=ULMessag ...
- 动态规划—triangle
题目: Given a triangle, find the minimum path sum from top to bottom. Each step you may move to adjace ...
- Vue 组件间的传值(通讯)
组件之间的通讯分为三种 父给子传 子给父传 兄弟组件之间的通讯 1 父组件给子组件传值 子组件嵌套在父组件内部,父组件给子组件传递一个标识,在子组件内部用props接收,子组件在模板里可以通过{{}} ...
- springboot logback 配置 通配符不行就这样
<?xml version="1.0" encoding="UTF-8"?><configuration> <property n ...
- OC+RAC(六) 核心方法bind
-(void)_test6{ RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id<RACSubscriber> ...
- 全文检索 使用最新lucene3.0.3+最新盘古分词 pangu2.4 .net 实例
开发环境 vs2015 winform 程序 1 首先需要下载对应的DLL 文章后面统一提供程序下载地址 里面都有 2 配置pangu的参数 也可以不配置 采用默认的即可 3 创建索引,将索引存放到本 ...