knn原理及借助电影分类实现knn算法
KNN最近邻算法原理
import pandas as pd
import numpy as np def distance(v1, v2):
"""
距离计算
:param v1:点1
:param v2: 点2
:return: 距离
"""
dist = np.sqrt(np.sum(np.power((v1 - v2), )))
return dist # 加载数据
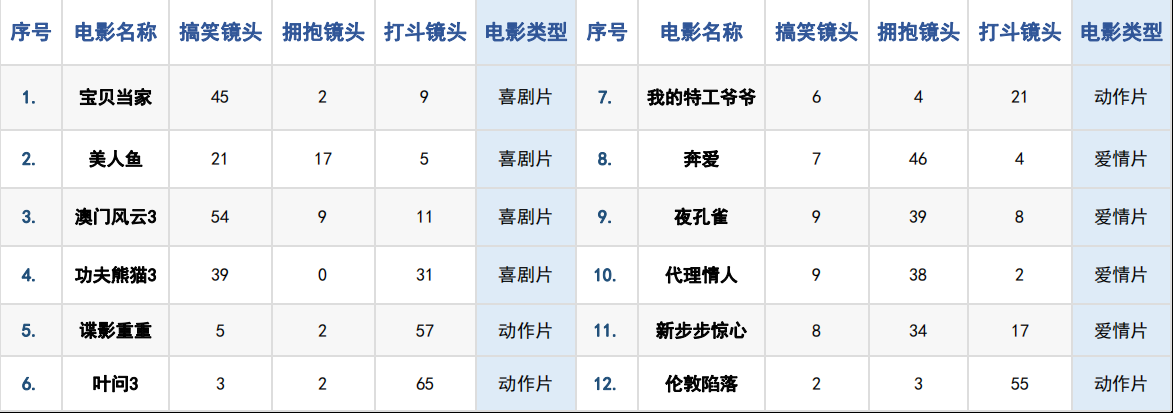
data = pd.read_excel("./电影分类数据.xlsx")
print("data:\n", data)
print("*" * )
# 获取训练集
train = data.iloc[:, :]
print("train:\n", train)
# 获取训练集的特征值 与目标值
train_x = train.iloc[:, :-]
train_y = train.iloc[:, -]
# 获取测试集
print("*" * )
test = data.columns[-:]
print("test:\n", test) # 进行计算距离
# 循环计算训练集每一个样本与测试集的距离
for i in range(train.shape[]): # 计算距离
dist = distance(train_x.iloc[i,:],test[:]) train.loc[i,'dist'] = dist print(train)
# 对距离按照升序进行排序
train.sort_values(by='dist',inplace=True)
print("*" * )
print("排序后的train:\n",train) # 确定K 值 k值不同结果不同
k =
res = train.loc[:,'电影类型'][:k].mode()[]
print("*" * )
print(res)
knn原理及借助电影分类实现knn算法的更多相关文章
- 机器学习实战1-1 KNN电影分类遇到的问题
为什么电脑排版效果和手机排版效果不一样~ 目前只学习了python的基础语法,有些东西理解的不透彻,希望能一边看<机器学习实战>,一边加深对python的理解,所以写的内容很浅显,也许还会 ...
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- kNN(K-Nearest Neighbor)最近的分类规则
KNN最近的规则,主要的应用领域是未知的鉴定,这一推断未知的哪一类,这样做是为了推断.基于欧几里得定理,已知推断未知什么样的特点和最亲密的事情特性: K最近的邻居(k-Nearest Neighbor ...
- 机器学习之KNN原理与代码实现
KNN原理与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9670187.html 1. KNN原理 K ...
- 数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析 分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法. 分类问题的应用场景:分 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 【数据挖掘】分类之kNN(转载)
[数据挖掘]分类之kNN 1.算法简介 kNN的思想很简单:计算待分类的数据点与训练集所有样本点,取距离最近的k个样本:统计这k个样本的类别数量:根据多数表决方案,取数量最多的那一类作为待测样本的类别 ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
随机推荐
- MYSQL学习笔记——数据类型
mysql的数据类型可以分为三大类,分别是数值数据类型.字符串数据类型以及日期时间数据类型. 数值数据类型 ...
- GNU linker script,ld script,GNU链接脚本
https://blog.csdn.net/itxiebo/article/details/50937412 https://blog.csdn.net/itxiebo/article/details ...
- [web 安全] php随机数安全问题
and() 和 mt_rand() 产生随机数srand() 和 mt_srand() 播种随机数种子(seed)使用: <?php srand(123);//播种随机数种子 for($i=0; ...
- css3 动画实例
animation 动画 animation-duration 代码实例: <!DOCTYPE html> <html> <head> <meta chars ...
- 【串线篇】spring boot自动配置精髓
一.SpringBoot启动会加载大量的自动配置类即绿色部分 二.我们看我们需要的功能有没有SpringBoot默认写好的自动配置类: 比如HttpEncodingAutoConfiguration ...
- django权限之二级菜单
遗漏知识点 1.构建表结构时,谁被关联谁就是主表,在层级删除的时候,删除子表的时候,主表不会被删除,反之删除主表的话,字表也会被删除, 使用related_name=None 反向查询,起名用的 ...
- 032:DTL常用过滤器(1)
为什么需要过滤器: 在DTL中,不支持函数的调用形式‘()’,因此不能给函数传递参数,这将有很大的局限性:而过滤器其实就是一个函数,可以对需要处理的参数进行处理,并且还可以额外接受一个参数(也就是说: ...
- 项目部署到tomcat上
1:先讲解一下tomcat的各个目录的作用 2:将项目打包成war的格式,然后放到webapps chengtai 是启动项目的时候自动解压的,不需要我们手动解压. 3:启动tomcat 进入到b ...
- 前端开发本地存储之cookie
1.cookie cookie是纯文本,没有可执行代码,是指某些网站为了辨别用户身份.进行 session 跟踪而储存在用户本地终端(浏览器)上的数据(通常经过加密).当用户访问了某个网站的时候,我们 ...
- OUC-NULL -凡事遇则立
[OUC-NULL-凡事遇则立] 一.项目的GITHUB地址 https://github.com/OUC-null/null- 二.对遇到的问题思考及总结 一开始进度较慢,大家一开始也没太找到前进的 ...