[2] Bert 论文精读
BERT是NLP领域让预训练这件事情出圈的工作。
开篇Introduction介绍了两类主流的预训练方法:
1、feature-based,即基于特征的,即我首先通过预训练得到一些比较好的特征,然后将这些特征作为额外的训练数据输入到模型中,从而使得模型在训练起来变得容易很多;
2、fine-tuning,即基于微调的。即我首先用其他数据集做预训练,训练好之后,我再去用我所需要的针对我的任务的数据集做微调,对我的模型的权重做一些小改动。
这两种方法都有一种局限性,即二者都是单向的模型,而Bert不是,正如其名字:Bidirectional Encoder Representations from Transformers
这个idea的主要来源很明确:我们平时处理NLP问题的模型都是单向的,但是虽然我们读一句话的时候总是从左到右这么读下来,但是在做一些其他任务的时候比如阅读理解、Q&A等等问题的时候,我们总会看完整个句子的全貌从而去理解这个句子的文本语义,因此如果能够让模型也做到这一点,效果会不会更好呢?
在conclusion写了,作者其实是把ELM0和GPT的idea拼接在一起,说得简单一些,就是用ELMo的双向,用Transformer实现。但具体到BERT这篇工作,我觉得还有一个更出众的点子在于《完形填空》。
Bert是一个微调模型,即先预训练,然后微调。
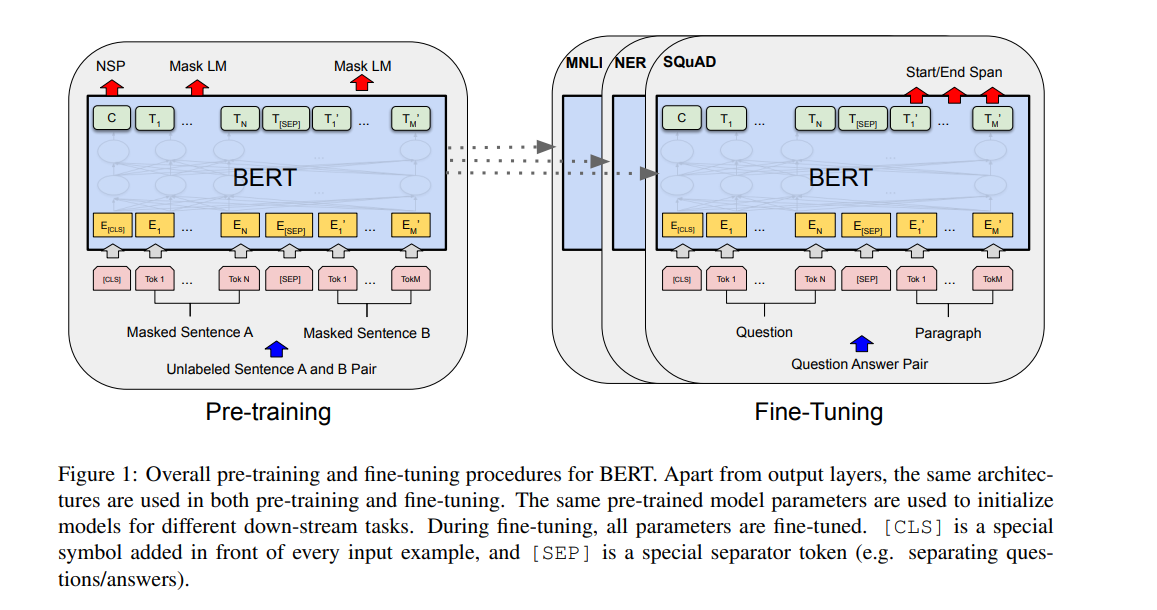
整体上来看,首先用一组没有label的数据做预训练,然后用有标号的对应下游任务的数据集去做微调。
其实说到底,Bert就是一个Transformer,只不过分成了预训练和微调。
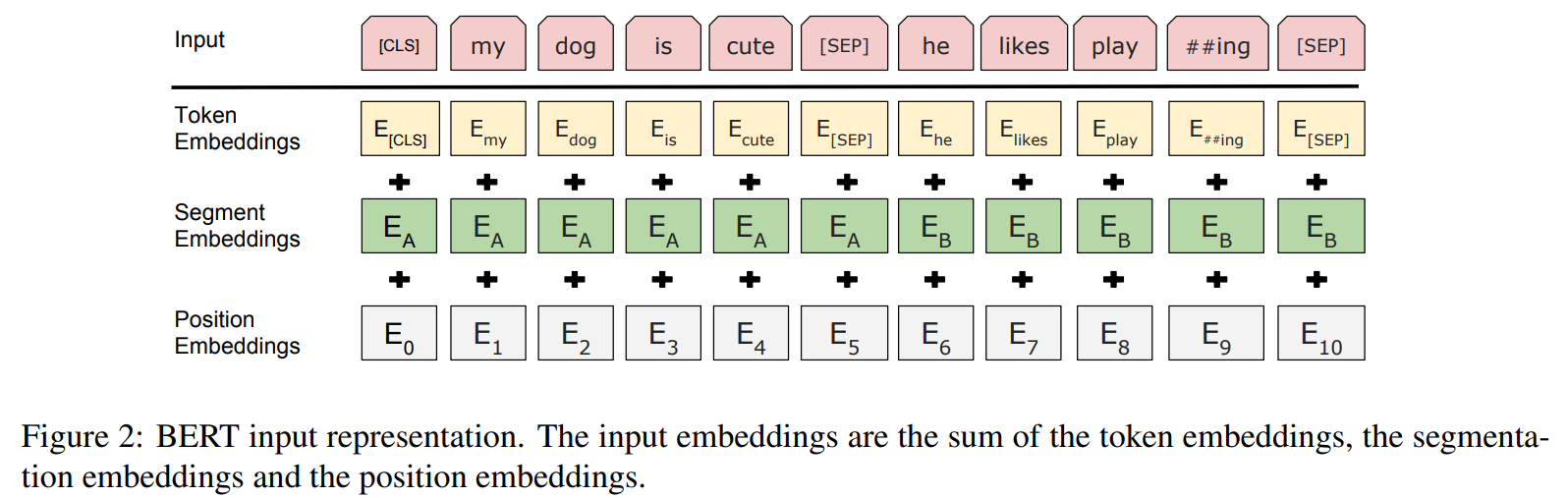
另外注意一下Bert的Embedding是三个:
在做完形填空的时候,Bert用了概率mask的trick。因为他们发现直接mask掉15%的数据存在很多问题,因此选择了另外20%特殊的点。其中,10%为随机替换一个词,我觉得可以理解成噪音;另外10%就是将答案暴露出来,用答案预测答案,算是对mask的一种补偿。
而在做句子连贯性预测的时候,则50%为连贯的一组句子,50%为不连贯。
此外,他还有一个小trick,即Wordpiece,将一些比较长的单词切开。因为长单词往往有多重含义的词根,这些词根组合在一起可以表示一个新的完整的意思,但是这种长单词大部分都出现频率都不是很高,因此将这些内容切开,可以更好地让模型学习到一句话中的语义碎片。比如将homeless拆分成home与less。
然后我发现,作为一篇深度学习的文章,作为一个深度学习模型,Bert竟然没有整体的模型架构!!这真的是我第一次见。
当然了,作者对于这个操作也解释了,“我们基本上是直接把Transformer源码拿过来用了,因此我们也没必要详细再讲一次。”
这个是很值得思考的,作者没有提出新的架构,这确实是一个缝合的文章,但是他却有5w的引用。
Bert更大的特点,我觉得是证明了一点,用更大的数据集训练更大的模型会更好,但其实这个东西早就被证实了。另外就是预训练和微调的理念在NLP的出圈。
[2] Bert 论文精读的更多相关文章
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- 用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读
虽然国内必须FQ才能登录YouTube,但想必大家都知道这个网站.基本上算是世界范围内视频领域的最大的网站了,坐拥10亿量级的用户,网站内的视频推荐自然是一个非常重要的功能.本文就focus在YouT ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- bert论文笔记
摘要 BERT是“Bidirectional Encoder Representations from Transformers"的简称,代表来自Transformer的双向编码表示.不同于 ...
- 【DL论文精读笔记】Object Detection in 20 Y ears: A Survey目标检测综述
目标检测20年综述(2019) 摘要 Abstract 该综述涵盖了400篇目标检测文章,时间跨度将近四分之一世纪.包括目标检测历史上的里程碑检测器.数据集.衡量指标.基本搭建模块.加速技术,最近的s ...
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- Faster-RCNN论文精读
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize objec ...
- 【DL论文精读笔记】 深度压缩
深度压缩 DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFM ...
- 【DL论文精读笔记】Image Segmentation Using Deep Learning: A Survey 图像分割综述
深度学习图像分割综述 Image Segmentation Using Deep Learning: A Survey 原文连接:https://arxiv.org/pdf/2001.05566.pd ...
随机推荐
- H5商城项目源码 (可预览 测试有效)
商城简介 这个商城项目由首页模块,发现模块,购物车模块以及我的等四大模块组成了33个相关内容界面 预览下载直通车 预览地址 首页模块 首页拥有搜索模块.分类模块.内容模块组成 发现模块 发现模块主要是 ...
- springcloud微服务搭建demo
软件 版本 IDEA 2022.3.1 <兼容maven 3.8.1及之前的所用版本> JDK 1.8_64 Maven 3.8.2 本demo只使用了服务发现与注册.Feign调用及负载 ...
- Navicat 15 or 16 永久版本(window和Mac)
一.下载Navicat Premium 官网https://www.navicat.com.cn/下载最新版本下载安装 链接包含(window激活包和Mac版本,请选择性下载): https://no ...
- SRE:如何提高报警有效性?
为什么要提升<报警有效性> 过多的报警会让负责人麻木 过多的报警会增加短信和电话的成本 提升根因定位效率 如何定义<报警有效性> 不漏报 不误报 不重报 不延报 如何量化 MT ...
- Centos8安装nvidia驱动
Centos8安装nvidia驱动 1. 查看显卡型号 lspci | grep-i nvidia 或者 lspci -vnn | grep VGA 2. 前往nvidia官网下载对应驱动 NVIDI ...
- 安卓开发 java控制UI
创建布局管理器对象 设置背景 设置活动界面 按钮事件 按钮显示
- 【NOIP2012提高组】开车旅行
题目 到处都有 闲话 碰巧考场上出了 \(Noip\) 原题 然后这题自然而然想到 预处理一个点开始分别由 \(A,B\) 驾驶会走到的下一个点 然后用预处理的数组求答案 当然你会发现 \(X=X0\ ...
- ascii编码常用字符的十进制对照表
- libcurl CURLOPT_WRITEFUNCTION 回调函数多次触发导致数据错乱的问题
记录一下自己犯的错误,回调函数本身就会提供数据大小,自己算反而出了问题. size_t Get_Receive_Data(void* buffer, size_t size, size_t nmemb ...
- C++标准库string学习笔记
string概述 作为c++语言用作字符串处理的标准库,和Python字符串类型有较多相似之处.可以使用'='进行赋值,"=="来比较,"+"进行拼接. 构造函 ...