图数据库|正反向边的最终一致性——TOSS 介绍
{kind=link}

Nebula Graph v2.6 当中比较重要的特性之一便是 TOSS。通过本文,我将带你全方位了解 TOSS 为何物。
从一条 GO 语句说起
众所周知,边分为无向边跟有向边两种。所以当按有向边去探索时,就可以按正向边 / 反向边做遍历,Nebula Graph 也支持这种语义。比如:
go from "101" over known reversely yield known.kdate, id($$);
上述语句从点 101 开始反向的找所有的对应邻边。但,当用户使用 Nebula 插入一条边时,命令都类似于:
insert edge known(degree) VALUES "100" -> "101":(299792458);
上述语句看上去只写了正向边,并没有输入反向边:这是因为在 Nebula 设计时,当用户插入一条边时,系统会默默地在后台写入一条反向边。
聊聊 Nebula Graph 如何插入一条边
以上文的那条 INSERT 语句为例,后台的执行流程有:
- Nebula Console 将
INSERT对应的 request 发给连接的 Nebula Graph Server; - Nebula Graph Server 收到后,根据正向边的信息对应补充出反向边的信息,并将这个 AddEdgeRequest 分别发往正反向边对应的主机;
- Nebula Storage Server 收到这个 AddEdgeRequest 后,在本地(通过 raft)插入对应的边,并将结果返回给 Graph Server;
- Nebula Graph Server 收到两边的结果后,返回给 Nebula Console;
流程图如下:
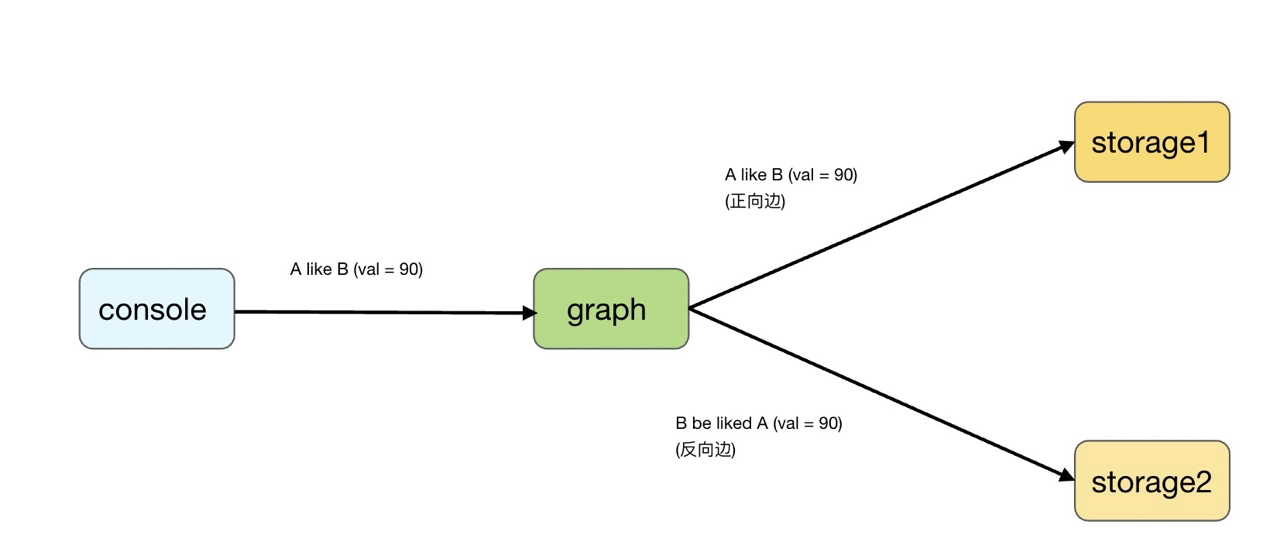
这里,对网络 / 分布式编程比较熟悉的同学可能现在就看出问题了:因为 Graph 对于两个 Storage 的调用使用 RPC,那么当 INSERT 操作执行的次数足够多,就一定会遇到一边 RPC 成功,另一边 RPC 失败(超时)的情况。换句话说,可能出现一个 INSERT 正向边成功,反向边失败的情况。
这种结果会反馈给客户端:如果用户有正反向边属性一致的需求,就需要对 failed 的 request 做无限重试。但是 Nebula Graph 做为一个数据库,将数据的原子性交由外部(客户端)来保证还是不合适的。
于是,诞生了一个需求——保证正反向边的原子性,即变更边时,正反边要么同时变更成功,要么同时变更失败。这便是 TOSS(Transaction on storage side)的由来,用于保证对边进行 INSERT、UPDATE 或 UPSERT 操作的最终一致性。
TOSS 使用方法
随着 Nebula v2.6.0 的发布,TOSS 功能已经上线。但基于性能和稳定性考虑,Nebula Graph 默认将该功能设为 default disable 状态。有正反向边一致性需求的小伙伴们可以在 Nebula Graph Server的配置中找到 enable_experimental_feature 这个选项,将它设为 true 并重启 graphd。如下:
--enable_experimental_feature=true
那么之后的 INSERT / UPDATE / UPSERT 就会有一致性的保证了。(跟之前一样做 CREATE SPACE / CREATE EDGE / INSERT / UPDATE 即可,不需要额外操作)
注:开启 TOSS 之后,只对增量数据有效,存量数据之前有过正反边不一致时不会得到修正。
Nebula 社区首届征文活动正式开启啦 奖品丰厚,全场景覆盖:撸码机械键盘、手机无线充、健康小助手智能手环,更有数据库设计、知识图谱实践书籍等你来领,还有 Nebula 精致周边送不停
欢迎对 Nebula 有兴趣、喜钻研的小伙伴来书写自己和 Nebula 有趣的故事呀~

交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
图数据库|正反向边的最终一致性——TOSS 介绍的更多相关文章
- 下一代NoSQL:最终一致性的末日
相比关系型数据库,NoSQL解决方案提供了shared-nothing.容错和可扩展的分布式架构等特性,同时也放弃了关系型数据库的强数据一致性和隔离性,美其名曰:"最终一致性". ...
- RocketMQ系列(七)事务消息(数据库|最终一致性)
终于到了今天了,终于要讲RocketMQ最牛X的功能了,那就是事务消息.为什么事务消息被吹的比较热呢?近几年微服务大行其道,整个系统被切成了多个服务,每个服务掌管着一个数据库.那么多个数据库之间的数据 ...
- 开源软件:NoSql数据库 - 图数据库 Neo4j
转载自原文地址:http://www.cnblogs.com/loveis715/p/5277051.html 最近我在用图形数据库来完成对一个初创项目的支持.在使用过程中觉得这种图形数据库实际上挺有 ...
- 图数据库项目DGraph的前世今生
本文由云+社区发表 作者:ManishRai Jain 作者:ManishRai Jain Dgraph Labs创始人 版权声明:本文由腾讯云数据库产品团队整理,页面原始内容来自于db weekly ...
- NoSql的三大基石:CAP理论&BASE&最终一致性
关系型数据库的局限 NoSql出现在关系型数据库之后,主要是为了解决关系型数据库的短板,我们先来看看随着软件行业的发展,关系型数据库面临了哪些挑战: 1.高并发 一个最典型的就是电商网站,例如双11, ...
- 使用kafka消息队列解决分布式事务(可靠消息最终一致性方案-本地消息服务)
微服务框架Spring Cloud介绍 Part1: 使用事件和消息队列实现分布式事务 本文转自:http://skaka.me/blog/2016/04/21/springcloud1/ 不同于单一 ...
- 图数据库Neo4j简介
图数据库Neo4j简介 转自: 图形数据库Neo4J简介 - loveis715 - 博客园https://www.cnblogs.com/loveis715/p/5277051.html 最近我在用 ...
- Neo4j图数据库从入门到精通
目录 第一章:介绍 Neo4j是什么 Neo4j的特点 Neo4j的优点 第二章:安装 1.环境 2.下载 3.开启远程访问 4.启动 第三章:CQL 1.CQL简介 2.Neo4j CQL命令/条款 ...
- 图数据库 Nebula Graph 的安装部署
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,还能够实现服务高可 ...
随机推荐
- Kubernetes:存储管理
Blog:博客园 个人 参考:Volumes | Kubernetes.Persistent Volumes | Kubernetes.Kubernetes 基础入门实战 简单来说,存储卷是定义在Po ...
- CF914G Sum the Fibonacci(FWT,FST)
CF914G Sum the Fibonacci(FWT,FST) Luogu 题解时间 一堆FWT和FST缝合而来的丑陋产物. 对 $ cnt[s_{a}] $ 和 $ cnt[s_{b}] $ 求 ...
- Python集成开发工具(IDE)推荐
1.7 Python集成开发工具(IDE)推荐 1.7.1 Notepad++ Notepad++是Windows操作系统下的一套文本编辑器(软件版权许可证: GPL),有完整的中文化接口及支持多国语 ...
- @Qualifier 注解?
当有多个相同类型的bean却只有一个需要自动装配时,将@Qualifier 注解和@Autowire 注解结合使用以消除这种混淆,指定需要装配的确切的bean. Spring数据访问
- 解释 AOP 模块?
AOP 模块用于发给我们的 Spring 应用做面向切面的开发, 很多支持由 AOP 联 盟提供,这样就确保了 Spring 和其他 AOP 框架的共通性.这个模块将元数据编 程引入 Spring.
- Servlet之间的关联
- Java 中,Maven 和 ANT 有什么区别?
虽然两者都是构建工具,都用于创建 Java 应用,但是 Maven 做的事情更多, 在基于"约定优于配置"的概念下,提供标准的 Java 项目结构,同时能为应用自 动管理依赖(应用 ...
- 定时任务__@Xxl-JOB的使用
概述xxl-job框架 首先我们要知道什么是XXL-JOB? 官方简介:XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并接入多家公司 ...
- Demo示例——Bundle打包和加载
Unity游戏里面的场景.模型.图片等资源,是如何管理和加载的? 这就是本文要讲的资源管理方式--bundle打包和加载. 图片 Unity游戏资源管理有很多方式: (1)简单游戏比如demo,可以直 ...
- MOS管驱动电路,看这里就啥都懂了
一.MOS管驱动电路综述在使用MOS管设计开关电源或者马达驱动电路的时候,大部分人都会考虑MOS的导通电阻,最大电压等,最大电流等,也有很多人仅仅考虑这些因素.这样的电路也许是可以工作的,但并不是优秀 ...