4.10:Spark之wordcount
〇、概述
1、拓扑结构
2、目标
使用spark完成计数实验
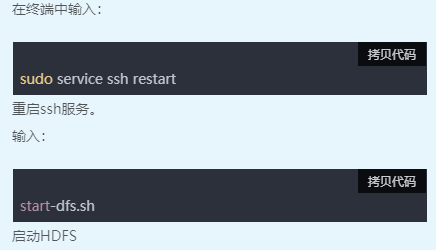
一、启动环境
二、新建数据文件

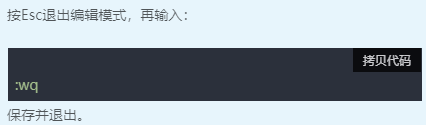
三、查看文件内容
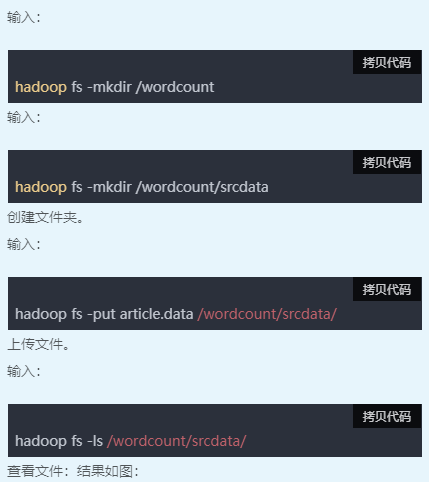

四、启动spark服务
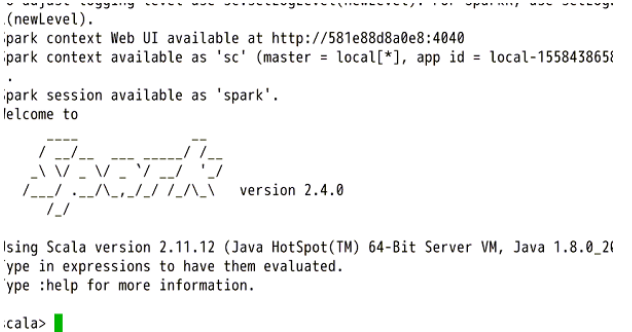
五、编写代码
复制以下代码到shell中(复制后在终端右键->粘贴):
import org.apache.spark.HashPartitioner
import java.io.PrintWriter
import java.io.File val links = sc.parallelize(List(("A",List("B","C")),("B",List("A","C")),("C",List("A","B","D")),("D",List("C")))).partitionBy(new HashPartitioner(100)).persist() var ranks=links.mapValues(v=>1.0) for (i <- 0 until 10) {
val contributions=links.join(ranks).flatMap {
case (pageId,(links,rank)) => links.map(dest=>(dest,rank/links.size))
}
ranks=contributions.reduceByKey((x,y)=>x+y).mapValues(v=>0.15+0.85*v)
} ranks.sortByKey().collect() var input = sc.textFile("hdfs://localhost:9000/wordcount/srcdata/article.data")
val writer = new PrintWriter(new File("/home/user/bigdata/spark_output.txt"))
writer.println(input.flatMap(x=>x.split(" ")).countByValue())
writer.close()
input.flatMap(x=>x.split(" ")).countByValue()
之后可以查看输出结果。

4.10:Spark之wordcount的更多相关文章
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark版wordcount,并根据词频进行排序
import org.apache.spark.{SparkConf, SparkContext}/** * Created by loushsh on 2017/10/9. */object Wor ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
随机推荐
- 分布式安装部署MinIO
官方文档地址:http://docs.minio.org.cn/docs/master/distributed-minio-quickstart-guide 前提条件:分布式Minio至少需要4个硬盘 ...
- Ceph 存储集群第一部分:配置和部署
内容来源于官方,经过个人实践操作整理,官方地址:http://docs.ceph.org.cn/rados/ 所有 Ceph 部署都始于 Ceph 存储集群. 基于 RADOS 的 Ceph 对象存储 ...
- Elastic App Search 入门
官方文档地址:https://swiftype.com/documentation/app-search/getting-started Elastic App Search 架构图: 它的特点是帮助 ...
- 组合总和 II
组合总和 II 题目介绍 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates ...
- day05-离线留言和离线文件
多用户即时通讯系统05 4.编码实现04(拓展) 拓展功能: 实现离线留言,如果某个用户不在线 ,当登陆后,可以接收离线的消息 实现离线发文件,如果某个功能没有在线,当登录后,可以接收离线的文件 4. ...
- js对象结构赋值const {XXX } =this
样例1: const { xxx } = this.state; 上面的写法是es6的写法,其实就相当于: const xxx = this.state.xxx 样例2: const {comment ...
- C++自学笔记 Composition:对象组合
继承是实现软件重用的一种方式. 在C++中拥有另一种实现软件重用的方式----- Composition:对象组合 用已经有的对象制造新的对象 (设计一个类的时候它的成员变量可以是另一个类的对象) 对 ...
- CSS基础-关于CSS注释的添加
在 CSS 中增加注释很简单,所有被放在/*和*/分隔符之间的文本信息都被称为注释. CSS 只有一种注释,不管是多行注释还是单行注释,都必须以/*开始.以*/结束,中间加入注释内容. 1.注释放在样 ...
- 洛谷P1638 逛画展 (尺取法)
尺取法的经典题目: 博览馆正在展出由世上最佳的 mm 位画家所画的图画. 游客在购买门票时必须说明两个数字,aa 和 bb,代表他要看展览中的第 aa 幅至第 bb 幅画(包含 a,ba,b)之间的所 ...
- 实时营销引擎在vivo营销自动化中的实践 | 引擎篇04
作者:vivo 互联网服务器团队 本文是<vivo营销自动化技术解密>的第5篇文章,重点分析介绍在营销自动化业务中实时营销场景的背景价值.实时营销引擎架构以及项目开发过程中如何利用动态队列 ...