4月26日 python学习总结 JoinableQueue、线程、三种锁
一、进程队列补充-创建进程队列的另一个类JoinableQueue
JoinableQueue同样通过multiprocessing使用。
创建队列的另外一个类:
JoinableQueue([maxsize]):这就像是一个Queue对象,但队列允许项目的使用者通知生成者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
参数介绍:
1 import time
2 import random
3 from multiprocessing import Process,JoinableQueue
4
5 def consumer(name,q):
6 while True:
7 res=q.get()
8 if res is None:break
9 time.sleep(random.randint(1,3))
10 print('\033[46m消费者===》%s 吃了 %s\033[0m' %(name,res))
11 q.task_done()
12
13 def producer(name,q,food):
14 for i in range(5):
15 time.sleep(random.randint(1,2))
16 res='%s%s' %(food,i)
17 q.put(res)
18 print('\033[45m生产者者===》%s 生产了 %s\033[0m' %(name,res))
19
20
21
22 if __name__ == '__main__':
23 #1、共享的盆
24 q=JoinableQueue()
25
26
27 #2、生产者们
28 p1=Process(target=producer,args=('egon',q,'包子'))
29 p2=Process(target=producer,args=('刘',q,'泔水'))
30 p3=Process(target=producer,args=('杨',q,'米饭'))
31
32 #3、消费者们
33 c1=Process(target=consumer,args=('alex',q))
34 c2=Process(target=consumer,args=('梁',q))
35 c1.daemon=True
36 c2.daemon=True
37
38 p1.start()
39 p2.start()
40 p3.start()
41 c1.start()
42 c2.start()
43
44
45 # 确定生产者确确实实已经生产完毕
46 p1.join()
47 p2.join()
48 p3.join()
49 # 在生产者生产完毕后,拿到队列中元素的总个数,然后直到元素总数变为0,q.join()这一行代码才算运行完毕
50 q.join()
51 #q.join()一旦结束就意味着队列确实被取空,消费者已经确确实实把数据都取干净了
52 print('主进程结束')
生产者消费者模型例子
二、线程
1、什么是线程
线程指的是一条流水线的工作过程
进程根本就不是一个执行单位,进程其实是一个资源单位
一个进程内自带一个线程,线程才是执行单位
2、进程VS线程
- 同一进程内的线程们共享该进程内资源,不同进程内的线程资源肯定是隔离的
- 创建线程的开销比创建进程要小的多
- 一个进程的所有线程的pid都是一样的
- 线程之间的地位相同,没有主次之分,但是主线程又代表着主进程
3、创建线程的两种方式
#方式一
from threading import Thread
import time
def sayhi(name):
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.start()
print('主线程')
#方式二
from threading import Thread
import time
class Sayhi(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
print('%s say hello' % self.name) if __name__ == '__main__':
t = Sayhi('egon')
t.start()
print('主线程')
线程执行的结果:
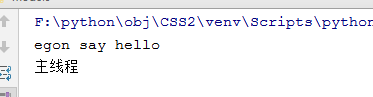
与进程不同,是因为线程启动的代价很小,启动速度远大于进程,所以,子线程先打印,主线程才打印
from threading import Thread,current_thread,active_count,enumerate
import time,os def task():
print('%s is running' %current_thread().name)
time.sleep(3) if __name__ == '__main__':
t1=Thread(target=task,name='第一个线程')
t2=Thread(target=task,)
t3=Thread(target=task,)
t1.start()
t2.start()
t3.start() # print(t1.is_alive()) #查看线程是否存活
print(active_count()) #查看活跃的线程数,包括主线程
print(enumerate()) #获取当前每个活跃的线程对象
print('主线程',current_thread().name) #获取当前线程名
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。 threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
5、守护线程
t.daemon=true
# 设为守护线程,守护线程要在线程开始执行之前设置,否则报错
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁
需要强调的是:运行完毕并非终止运行
1 .对主进程来说,运行完毕指的是主进程代码运行完毕
2. 对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
详细解释:
- 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束
- 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name) if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必须在t.start()之前设置
t.start() print('主线程')
print(t.is_alive())
'''
主线程
True
'''
三、死锁现象;互斥锁、递归锁、信号量
死锁现象
1 from threading import Thread,Lock,RLock
2 import time
3
4 mutexA=Lock()
5 mutexB=Lock()
6
7 class MyThread(Thread):
8 def run(self):
9 self.f1()
10 self.f2()
11
12 def f1(self):
13 mutexA.acquire()
14 print('%s 拿到了A锁' %self.name)
15
16 mutexB.acquire()
17 print('%s 拿到了B锁' %self.name)
18 mutexB.release()
19
20 mutexA.release()
21
22 def f2(self):
23 mutexB.acquire()
24 print('%s 拿到了B锁' %self.name)
25 time.sleep(0.1)
26
27 mutexA.acquire()
28 print('%s 拿到了A锁' %self.name)
29 mutexA.release()
30
31 mutexB.release()
32
33
34 if __name__ == '__main__':
35 for i in range(10):
36 t=MyThread()
37 t.start()
38
39 print('主')
死锁
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
信号量
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
# from multiprocessing import Semaphore from threading import Thread,Semaphore,current_thread
import time,random sm=Semaphore(5) def go_wc():
sm.acquire()
print('%s 上厕所ing' %current_thread().getName())
time.sleep(random.randint(1,3))
sm.release() if __name__ == '__main__':
for i in range(23):
t=Thread(target=go_wc)
t.start()
4月26日 python学习总结 JoinableQueue、线程、三种锁的更多相关文章
- 6月6日 python学习总结 jQuery (三)
1. 常用事件 1. hover #鼠标悬停监听 2. keydown和keyup #键盘按键 按下/抬起 3. change #监听值的改变 全部输入完失去焦点后 4. focus和blur # 获 ...
- 4月2日 python学习总结
昨天内容回顾: 1.迭代器 可迭代对象: 只要内置有__iter__方法的都是可迭代的对象 既有__iter__,又有__next__方法 调用__iter__方法==>得到内置的迭代器对象 调 ...
- 4月8日 python学习总结 模块与包
一.包 #官网解释 Packages are a way of structuring Python's module namespace by using "dotted module n ...
- 5月14日 python学习总结 视图、触发器、事务、存储过程、函数、流程控制、索引
一.视图 1.什么是视图 视图就是通过查询得到一张虚拟表,然后保存下来,下次用的直接使用即可 2.为什么要用视图 如果要频繁使用一张虚拟表,可以不用重复查询 3.如何用视图 create view t ...
- 4月12日 python学习总结 继承和派生
一.继承 什么是继承: 继承是一种新建类的方式,在python中支持一个子类继承多个父类 新建类称为子类或派生类 父类可以称之为基类或者超类 子类会遗传父类的属性 2. 为什么继承 ...
- 4月11日 python学习总结 对象与类
1.类的定义 #类的定义 class 类名: 属性='xxx' def __init__(self): self.name='enon' self.age=18 def other_func: pas ...
- 4月3日 python学习总结
1. 列表生成器 l=['egg%s' %i for i in range(100) if i>20 ] print(l) 若将 [ ] 换成 ( ),则为生成器表达式,结果是一个迭代器 #求文 ...
- 4月17日 python学习总结 反射、object内置方法、元类
一.反射 下述四个函数是专门用来操作类与对象属性的,如何操作? 通过字符串来操作类与对象的属性,这种操作称为反射 class People: country="China" def ...
- 4月4日 python学习总结 os pickle logging
1.序列化和反序列化 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling. 反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickl ...
随机推荐
- 基于反熔丝FPGA、QSPI FLASH的高可靠程序存储、启动控制系统
1 涉及术语解释 1.1 三模冗余 三模冗余系统简称TMR(Triple Modular Redundancy),是最常用的一种容错设计技术.三个模块同时执行相同的操作,以多数相同的 ...
- Java在算法题中的输入问题
Java在算法题中的输入问题 在写算法题的时候,经常因为数据的输入问题而导致卡壳,其中最常见的就是数据输入无法结束. 1.给定范围,确定输入几个数据 直接使用普通的Scanner输入数据范围,然后使用 ...
- CentOS 7.6 部署 GlusterFS 分布式存储系统
文章目录 GlusterFS简介 环境介绍 开始GlusterFS部署 配置hosts解析 配置GlusterFS 创建文件系统 安装GlusterFS 启动GlusterFS 将节点加入到主机池 创 ...
- No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK 问题解决
1. 问题描述 使用idea对Java工程执行mvn compile命令进行编译,出现以下报错: [ERROR] Failed to execute goal org.apache.maven.plu ...
- Springboot整合kaptcha验证码
01.通过配置类来配置kaptcha 01-01.添加kaptcha的依赖: <!-- kaptcha验证码 --> <dependency> <groupId>c ...
- 关于Windows安装两个不同版本的MySQL详细步骤
关于Windows安装两个不同版本的MySQL详细步骤 安装两个不同版本的数据库原因 由于大部分教程所使用的数据库为5.7版本,而我之前安装的是8.0版本. 在一些特殊情况下,低版本数据库不能动,高版 ...
- Shell 函数带中横线问题排查
Shell 中编写的函数,如果函数名中带了中横线,在使用 /bin/sh 执行时会报错. ➜ subprocess git:(master) ✗ cat kubectl.sh _kubectl_api ...
- 微信小程序实现文本的展开与收起
致谢 https://www.jianshu.com/p/9458083214cc 效果图 代码 js部分 // pages/volunteer/active/info/activeInfo.js ...
- [旧][Android] ButterKnifeProcessor 工作流程分析
备注 原发表于2016.05.21,资料已过时,仅作备份,谨慎参考 前言 在 [Android] ButterKnife 浅析 中,我们了解了 ButterKnife 的用法,比较简单. 本次文章我们 ...
- R数据分析:样本量计算的底层逻辑与实操,pwr包
样本量问题真的是好多人的老大难,是很多同学科研入门第一个拦路虎,今天给本科同学改大创标书又遇到这个问题,我想想不止是本科生对这个问题不会,很多同学从上研究生到最后脱离科研估计也没能把这个问题弄得很明白 ...