Windows下基于python3使用word2vec训练中文维基百科语料(三)
对前两篇获取到的词向量模型进行使用:
代码如下:
import gensim
model = gensim.models.Word2Vec.load('wiki.zh.text.model')
flag=1
while(flag):
word = input("Please input the key_word:\n")
if word in model:
print(model['word'])
# 词相似度
result = model.most_similar(word)
for e in result:
print(e[0], e[1])
else:
print('单词不在字典中') flag=int(input("do you want to input next(yes=1,no=0):\n")) #计算两个单词相似度
print ("水杯和水瓶的相似度为:",model.similarity('水杯','水瓶')) #模型还提供了一个方法,用于寻找离群词:
print (model.doesnt_match(u"早餐 晚餐 午餐 中心".split()))
#我们还可以根据给定的条件推断相似词,比如下面的代码中,我们找到一个跟篮球最相关,跟计算机很不相关的第一个词:
print (model.most_similar(positive=['篮球'],negative=['计算机'],topn=1))
输出结果:
(1)求“漂亮”的向量:

结果:
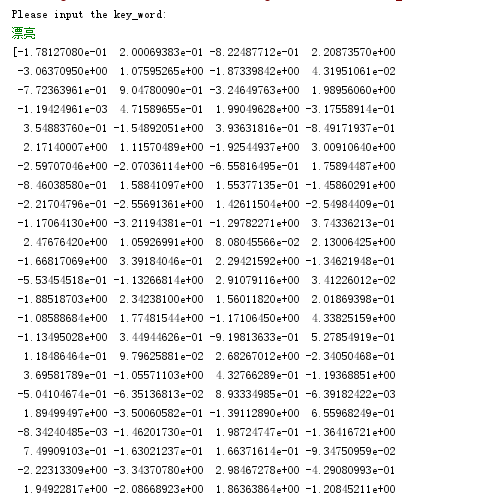
(2)输出“漂亮”的相似词,以及他们之间的相关度:

结果:

(3)输出“水杯”和“水瓶”之间的相似度:

结果:
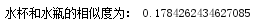
(4)寻找“离群词”

结果:

(5)根据给定的条件推断相似词:

结果:
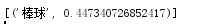
现在所有的工作就都结束啦!!!之后可以根据不同的要求来进行不同的应用啦!
Windows下基于python3使用word2vec训练中文维基百科语料(三)的更多相关文章
- Windows下基于python3使用word2vec训练中文维基百科语料(二)
在上一篇对中文维基百科语料处理将其转换成.txt的文本文档的基础上,我们要将为文本转换成向量,首先都要对文本进行预处理 步骤四:由于得到的中文维基百科中有许多繁体字,所以我们现在就是将繁体字转换成简体 ...
- Windows下基于python3使用word2vec训练中文维基百科语料(一)
在进行自然语言处理之前,首先需要一个语料,这里选择维基百科中文语料,由于维基百科是 .xml.bz2文件,所以要将其转换成.txt文件,下面就是相关步骤: 步骤一:下载维基百科中文语料 https:/ ...
- 使用word2vec对中文维基百科数据进行处理
一.下载中文维基百科数据https://dumps.wikimedia.org/zhwiki/并使用gensim中的wikicorpus解析提取xml中的内容 二.利用opencc繁体转简体 三.利用 ...
- Windows下基于Python3安装Ipython Notebook(即Jupyter)。python –m pip install XXX
1.安装Python3.x,注意修改环境变量path(追加上python安装目录,如:D:\Program Files\Python\Python36-32) 2.查看当前安装的第三方包:python ...
- windows下基于sublime text3的nodejs环境搭建
第一步:先安装sublime text3.详细教程可自行百度,这边不具体介绍了. 第二步.安装nodejs插件,有两种方式 第一种方式:直接下载https://github.com/tanepiper ...
- Windows下安装Python3.4.2
一.Windows下安装Python3.4.2 1.下载Windows下的Python3.4.2.exe 2.指定一个目录安装,然后下一步 3.配置环境变量包括Python.exe的文件.目录如下图所 ...
- 环境搭建文档——Windows下的Python3环境搭建
前言 背景介绍: 自己用Python开发了一些安卓性能自动化测试的脚本, 但是想要运行这些脚本的话, 本地需要Python的环境. 测试组的同事基本都没有安装Python环境, 于是乎, 我就想直接在 ...
- word2vec训练中文模型
-- 这篇文章是一个学习.分析的博客 --- 1.准备数据与预处理 首先需要一份比较大的中文语料数据,可以考虑中文的维基百科(也可以试试搜狗的新闻语料库).中文维基百科的打包文件地址为 https: ...
- Windows下基于http的git服务器搭建-gitstack
版权声明:若无来源注明,Techie亮博客文章均为原创. 转载请以链接形式标明本文标题和地址: 本文标题:Windows下基于http的git服务器搭建-gitstack 本文地址:http: ...
随机推荐
- docker配置网络
1.暂停服务,删除旧网桥#service docker stop#ip link set dev docker0 down#brctl delbr docker0 2.创建新网桥bridge0#brc ...
- 【.Net】浅谈C#中的值类型和引用类型
在C#中,值类型和引用类型是相当重要的两个概念,必须在设计类型的时候就决定类型实例的行为.如果在编写代码时不能理解引用类型和值类型的区别,那么将会给代码带来不必要的异常.很多人就是因为没有弄清楚这两个 ...
- 【python】python字符串前面加u,r,b的含义
1.字符串前加 u 例:u"我是含有中文字符组成的字符串." 作用:后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出 ...
- 安装FastDFS+Nginx
安装FastDFS FastDFS开发者的GitHub地址为:https://github.com/happyfish100 打开上述链接,我们点击fastdfs–>release,发现最新版的 ...
- 客户端 new socket时候 就像服务端发起连接了
客户端 new socket时候 就像服务端发起连接了
- Go语言【第六篇】:Go循环语句
Go语言循环语句 在不少实际问题中有许多具有规律性的重复操作,因此在程序中就需要重复执行某些语句,以下为大多数编程语言循环程序的流程如: Go语言提供了以下几种类型循环处理语句: 循环类型 描述 fo ...
- [bzoj4391] [Usaco2015 dec]High Card Low Card 贪心 线段树
---题面--- 题解: 观察到以决策点为分界线,以点数大的赢为比较方式的游戏都是它的前缀,反之以点数小的赢为比较方式的都是它的后缀,也就是答案是由两段答案拼凑起来的. 如果不考虑判断胜负的条件的变化 ...
- 【基础】ASP.net MVC 文件下载的几种方法(欢迎讨论)
在ASP.net MVC 中有几种下载文件的方法 前提:要下载的文件必须是在服务器目录中的,至于不在web项目server目录中的文件下载我不知道,但是还挺想了解的. 第一种:最简单的超链接方法,&l ...
- 非代码抽取的dex加固脱壳
常见的非代码抽取的dex加固,可以通过修改或者hook源码中的dex解析函数拿到目标dex完成脱壳.该dex解析函数为DexFile* dexFileParse(const u1* data, siz ...
- Linux内核中的常用宏container_of其实很简单
http://blog.csdn.net/npy_lp/article/details/7010752 通过一个结构体变量的地址,求该结构体的首地址. #ifndef CONTAINER_OF #de ...