Windows下基于python3使用word2vec训练中文维基百科语料(三)
对前两篇获取到的词向量模型进行使用:
代码如下:
import gensim
model = gensim.models.Word2Vec.load('wiki.zh.text.model')
flag=1
while(flag):
word = input("Please input the key_word:\n")
if word in model:
print(model['word'])
# 词相似度
result = model.most_similar(word)
for e in result:
print(e[0], e[1])
else:
print('单词不在字典中') flag=int(input("do you want to input next(yes=1,no=0):\n")) #计算两个单词相似度
print ("水杯和水瓶的相似度为:",model.similarity('水杯','水瓶')) #模型还提供了一个方法,用于寻找离群词:
print (model.doesnt_match(u"早餐 晚餐 午餐 中心".split()))
#我们还可以根据给定的条件推断相似词,比如下面的代码中,我们找到一个跟篮球最相关,跟计算机很不相关的第一个词:
print (model.most_similar(positive=['篮球'],negative=['计算机'],topn=1))
输出结果:
(1)求“漂亮”的向量:

结果:
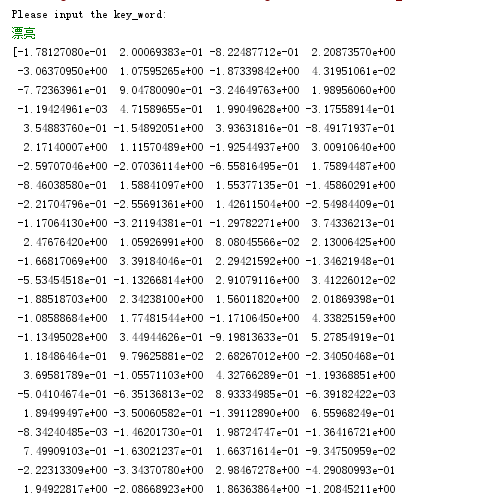
(2)输出“漂亮”的相似词,以及他们之间的相关度:

结果:

(3)输出“水杯”和“水瓶”之间的相似度:

结果:
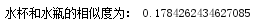
(4)寻找“离群词”

结果:

(5)根据给定的条件推断相似词:

结果:
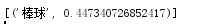
现在所有的工作就都结束啦!!!之后可以根据不同的要求来进行不同的应用啦!
Windows下基于python3使用word2vec训练中文维基百科语料(三)的更多相关文章
- Windows下基于python3使用word2vec训练中文维基百科语料(二)
在上一篇对中文维基百科语料处理将其转换成.txt的文本文档的基础上,我们要将为文本转换成向量,首先都要对文本进行预处理 步骤四:由于得到的中文维基百科中有许多繁体字,所以我们现在就是将繁体字转换成简体 ...
- Windows下基于python3使用word2vec训练中文维基百科语料(一)
在进行自然语言处理之前,首先需要一个语料,这里选择维基百科中文语料,由于维基百科是 .xml.bz2文件,所以要将其转换成.txt文件,下面就是相关步骤: 步骤一:下载维基百科中文语料 https:/ ...
- 使用word2vec对中文维基百科数据进行处理
一.下载中文维基百科数据https://dumps.wikimedia.org/zhwiki/并使用gensim中的wikicorpus解析提取xml中的内容 二.利用opencc繁体转简体 三.利用 ...
- Windows下基于Python3安装Ipython Notebook(即Jupyter)。python –m pip install XXX
1.安装Python3.x,注意修改环境变量path(追加上python安装目录,如:D:\Program Files\Python\Python36-32) 2.查看当前安装的第三方包:python ...
- windows下基于sublime text3的nodejs环境搭建
第一步:先安装sublime text3.详细教程可自行百度,这边不具体介绍了. 第二步.安装nodejs插件,有两种方式 第一种方式:直接下载https://github.com/tanepiper ...
- Windows下安装Python3.4.2
一.Windows下安装Python3.4.2 1.下载Windows下的Python3.4.2.exe 2.指定一个目录安装,然后下一步 3.配置环境变量包括Python.exe的文件.目录如下图所 ...
- 环境搭建文档——Windows下的Python3环境搭建
前言 背景介绍: 自己用Python开发了一些安卓性能自动化测试的脚本, 但是想要运行这些脚本的话, 本地需要Python的环境. 测试组的同事基本都没有安装Python环境, 于是乎, 我就想直接在 ...
- word2vec训练中文模型
-- 这篇文章是一个学习.分析的博客 --- 1.准备数据与预处理 首先需要一份比较大的中文语料数据,可以考虑中文的维基百科(也可以试试搜狗的新闻语料库).中文维基百科的打包文件地址为 https: ...
- Windows下基于http的git服务器搭建-gitstack
版权声明:若无来源注明,Techie亮博客文章均为原创. 转载请以链接形式标明本文标题和地址: 本文标题:Windows下基于http的git服务器搭建-gitstack 本文地址:http: ...
随机推荐
- 【week6】用户数
小组名称:nice! 小组成员:李权 于淼 杨柳 刘芳芳 项目内容:约跑app alpha发布48小时以后用户数如何,是否达到预期目标,为什么,是否需要改进,如何改进(或理性估算). 首先我们的app ...
- 某一线互联网公司前端面试题js部分总结
js部分 1,使用严格模式的优点 - 消除Javascript语法的一些不合理.不严谨之处,减少一些怪异行为; - 消除代码运行的一些不安全之处,保证代码运行的安全: - 提高编译器效率,增加运行速度 ...
- python爬虫从入门到放弃(五)之 正则的基本使用(转)
什么是正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符”,这个“规则字符” 来表达对字符的一种过滤逻辑. 正则并不是pyth ...
- 【Linux】- 文件基本属性
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限.为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定. 在Linux中我们可 ...
- CodeForces 632E Thief in a Shop
题意:给你n种物品,每种无限个,问恰好取k个物品能组成哪些重量.n<=1000,k<=1000,每种物品的重量<=1000. 我们搞出选取一种物品时的生成函数,那么只要对这个生成函数 ...
- Socket_FTP
1. md5加密回顾: import hashlib m=hashlib.md5() #创建md5对象 m.update(b'abcd') #生成加密串 m.update(b'efg') print( ...
- POJ 3261 Milk Patterns (后缀数组,求可重叠的k次最长重复子串)
Milk Patterns Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 16742 Accepted: 7390 Ca ...
- CF#508 1038E Maximum Matching
---题面--- 题解: 感觉还是比较妙的,复杂度看上去很高(其实也很高),但是因为n只有100,所以还是可以过的. 考虑一个很暴力的状态f[i][j][x][y]表示考虑取区间i ~ j的方格,左右 ...
- Educational Codeforces Round 39 (Rated for Div. 2) G
Educational Codeforces Round 39 (Rated for Div. 2) G 题意: 给一个序列\(a_i(1 <= a_i <= 10^{9}),2 < ...
- android内核源码下载和编译
1.下载编译 新建kernel目录 ~/srcAndroid/src4.4.4_r1/kernel目录下,输入命令: seven@ThinkPad:~/srcAndroid/src4.4.4_r1/k ...