(原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念、优化目标、聚类中心等内容;特征降维包括降维的缘由、算法描述、压缩重建等内容。coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml
(一)K-means聚类算法
Input data:未标记的数据集,类别数K;
算法流程:
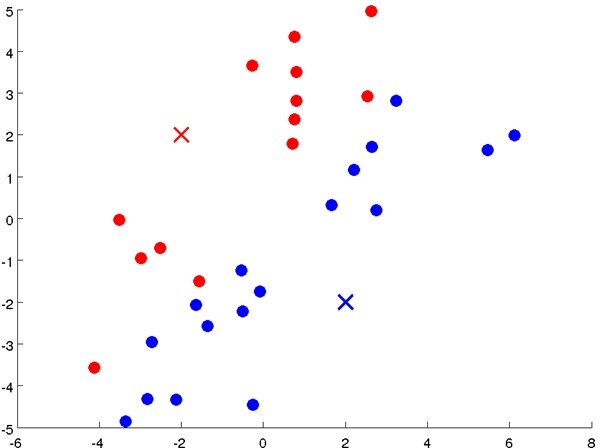
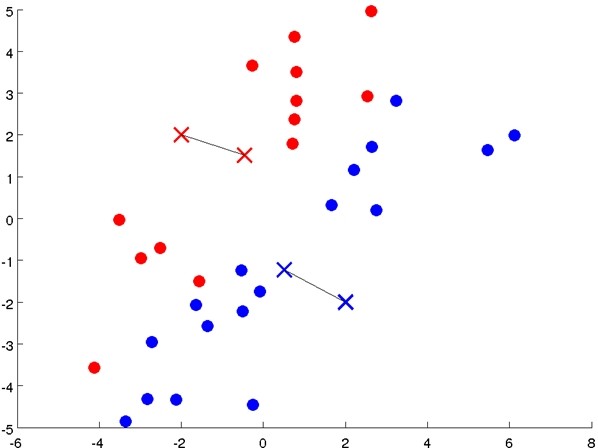
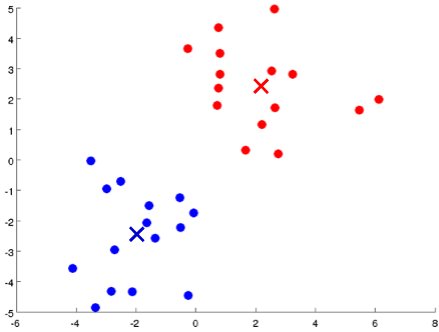
- 首先随机选择K个点,作为初始聚类中心(cluster centroids);
- 计算数据集中每个数据与聚类中心的距离,将其划分到与其最近的中心点那类;
- 重新计算每个类的平均值,并将其作为新的聚类中心;
- 重复步骤2-4直至聚类中心不再变化;
 |
 |
 |
Repeat {
for i = 1 to m
c(i):= index (from 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk:= average (mean) of points assigned to cluster k}
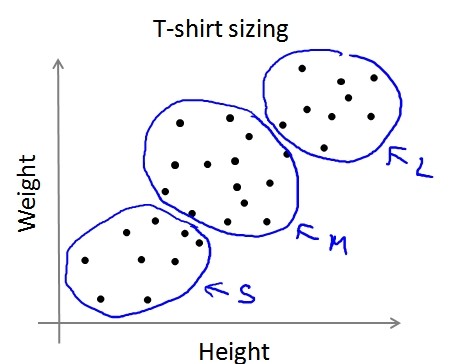
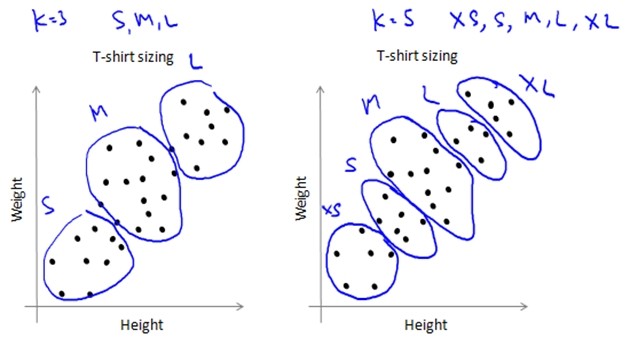
PS:K-means算法也可以用于在没有明显区分的情况下将数据分组,如T-shirt的尺寸问题。
优化目标(Optimization objective)
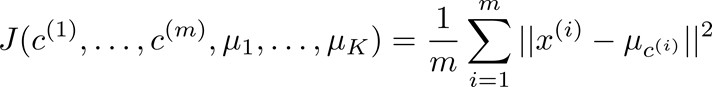
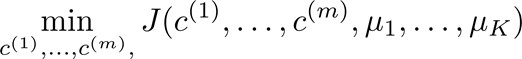

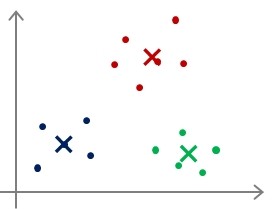
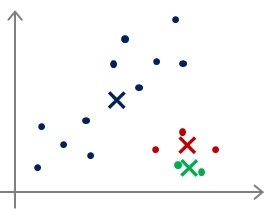
聚类中心初始化(Random initialization)
 |
 |
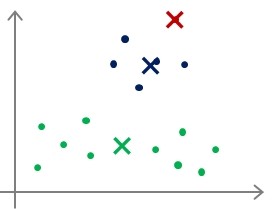 |
- 选择K<m,即聚类中心点的个数要小于所有训练集的数量;
- 随机选择K个训练实例,然后令K个聚类中心分别与这K个训练实例相等;
- 多次运行K-means算法,每次都进行随机初始化;
- 计算代价函数,选择代价最小的结果。
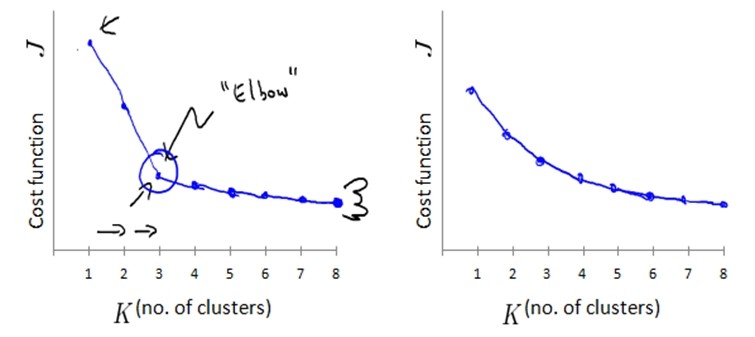
聚类数选择(Choosing the number of clusters)
(二)降维(Dimensionality Reduction)
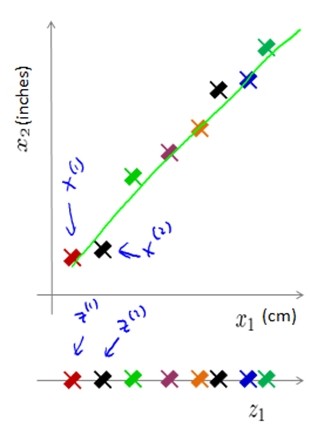
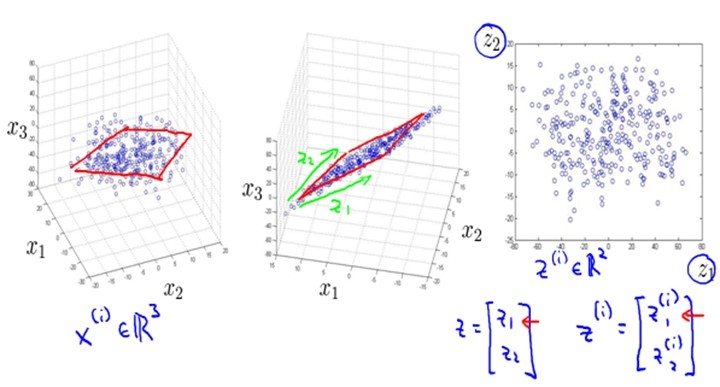
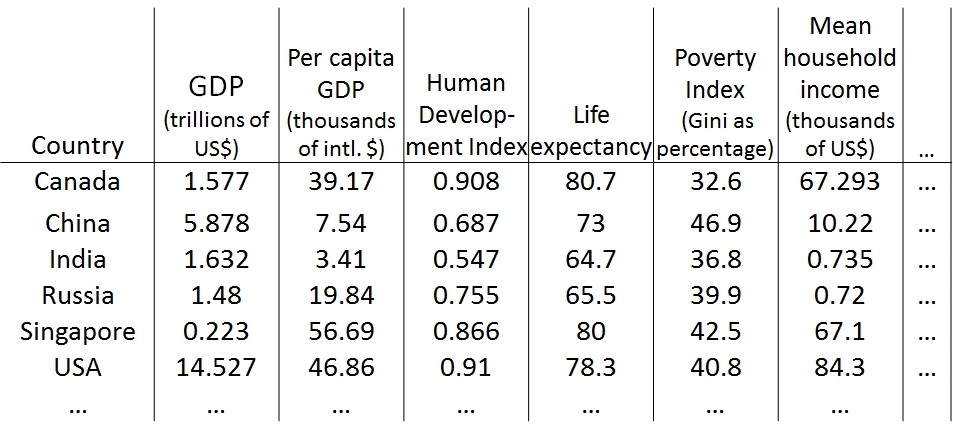
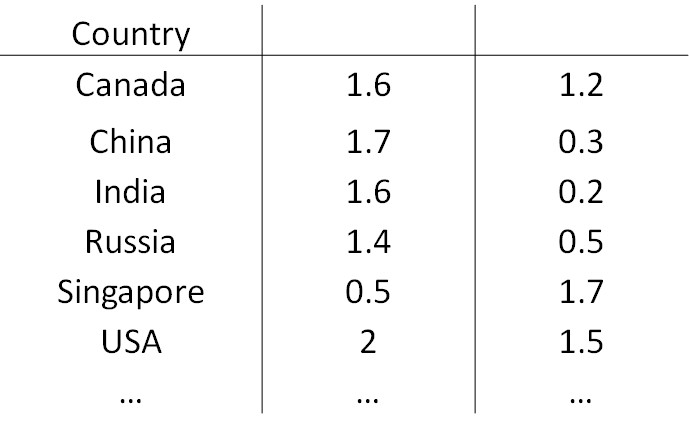
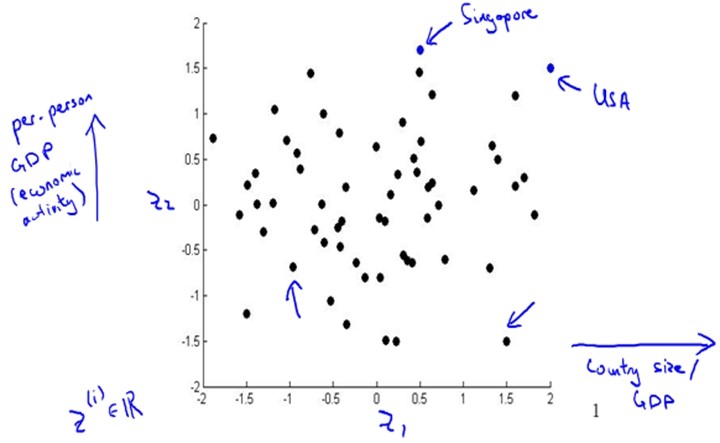
数据可视化(Data Visualization)
 |
 |
PCA(Principal Component Analysis )
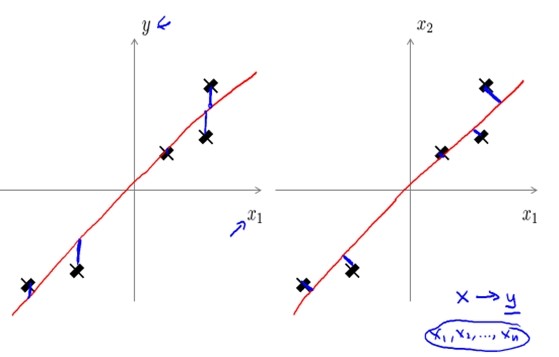
| PCA | Linear Regression |
| 投影误差最小(右图) | 预测误差最小(左图) |
| 无预测任务 | 需预测结果 |
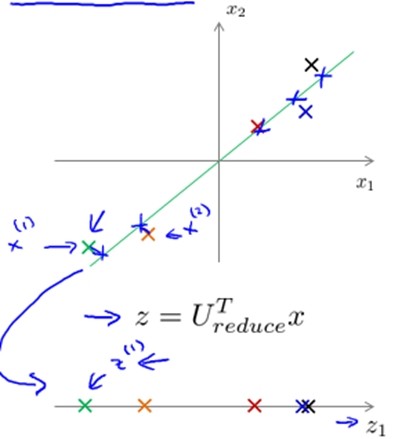
PCA算法
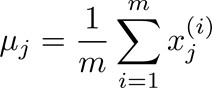
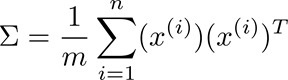
[U,S,V] = svd(Sigma);
其中U是最小投影误差的方向向量构成的矩阵。
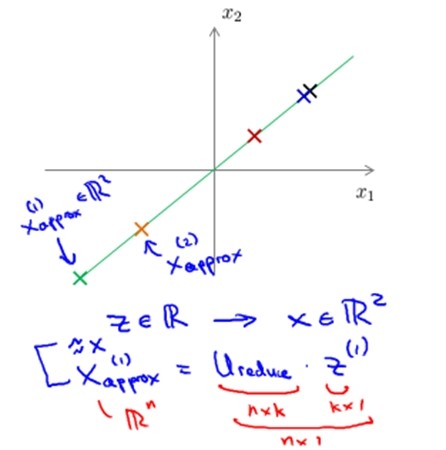
Ureduce = U(:,1:k);
z = UTreduce *x;
压缩重建& k的选择
1. 压缩重建:
- 通过z = UTreduce *x计算特征向量z;其中x是n*1维,所以z是k*1维。
- 通过xapprox = UTreduce * z来近似得到原来的特征向量x;其中z是k*1。所以xapprox 是n*1维。
 |
 |
从上面的分析中可以看出,我们希望在误差尽量小的情况下k值尽量小,那么怎样选择k呢?
2. 方法一:
- 在k = 1时,使用PCA算法;
- 计算Ureduce,z(1),z(2),...,z(m),x(1)approx ,...,x(m)approx
- 检验是否?
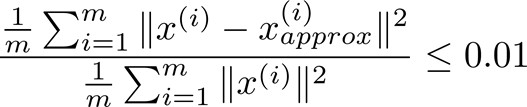 若否,则继续尝试k=2,k=3,.......
若否,则继续尝试k=2,k=3,.......
3. 方法二:
在Octave中使用svd函数时,[U,S,V] = svd(Sigma);其中的S是n*n的矩阵,只有对角线上有值,如下所示:
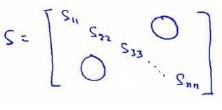
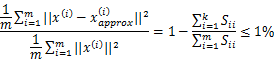 ≡
≡ 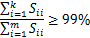
使用PCA的优势及应用
假如我们的输入特征向量是10000维,在使用PCA后可以降至1000维,这样可以加速训练过程,并减少内存。
PS:对于测试集和交叉验证集,同样可以使用训练集得到的Ureduce.由于我们将特征空间由n维减少到了k维,有人会认为这样做会避免过拟合,这样做也许有效,但不是很好的避免过拟合的方法。若要避免过拟合,还是应尝试正则化的方法。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Clustering & Dimensionality Reduction部分作业的核心代码:
1. findClosestCentroids
m = size(X,1);
dis_vec = zeros(K,1);
for i = 1:m
for j = 1:K
dis_vec(j) = sum((X(i,:)-centroids(j,:)).^2);
end
[v,k] = min(dis_vec);
idx(i) = k;
end
2. computeCentroids
tp_sum = zeros(K, n);
tp_num = zeros(K, 1);
for i = 1:m
cy = idx(i);
tp_sum(cy,:) = tp_sum(cy,:) + X(i,:);
tp_num(cy) += 1;
end
for j = 1:K
centroids(j,:) = tp_sum(j,:)/tp_num(j);
end
3. pca.m
sigma = (1/m)*X'*X;
[U,S,V] = svd(sigma);
4. projectData.m
Z = X*U(:,1:K);
5. recoverData.m
X_rec = Z* U(:,1:K)';
(原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 5) Neural Networks Learning
本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
随机推荐
- JSX语法规范
1.只有一个开始节点和一个尾节点 正确的写法 ReactDOM.render( <div>hello,你好</div>, document.body ) 错误的写法,开始节点和 ...
- arch中yaourt的安装和使用
yaourt-Yet AnOther User Repository Tool Yaourt是archlinux方便使用的关键部件之一,但没有被整合到系统安装中的工具.建议在装完系统重启之后,更新完p ...
- git - 使用原理
对git操作最大的功臣就是.git目录下的HEAD HEAD是什么 HEAD其实是一个类似于指针的东西,只不过这个指针的含义是指向当前的分支,当你再[ git checkout 分支 ] 的时候这个分 ...
- python的IDLE界面回退代码语句
Alt+P回退到IDLE中之前输入的代码语句 Alt+N可以移至下一个代码语句
- C# 网络编程小计 20150202
在学习网络Socket编程之前必须得学会多线程编程,这个是经常会用的到 可参考:http://www.cnblogs.com/GIS_zhou/articles/1839248.html System ...
- [New learn]GCD其他方法的使用
https://github.com/xufeng79x/GCDDemo 1.简介 在前面的两篇博文中我介绍了GCD的一般使用方法和死锁的分析调查.本博文中继续讲解GCD的其他比较常用的几个使用方法. ...
- HDU 2829 Lawrence(四边形优化DP O(n^2))
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2829 题目大意:有一段铁路有n个站,每个站可以往其他站运送粮草,现在要炸掉m条路使得粮草补给最小,粮草 ...
- linux下环境变量设置的问题
在当前环境变量前新增加一个路径 export PATH=/your/bin/path:$PATH export LD_LIBRARY_PATH=/your/lib/path:$LD_LIBRARY_P ...
- vue2.0--组件通信(非vuex法)
写在前面: 1.父组件的data写法与子组件的data写法不同 //父组件 data:{ //对象形式 } //子组件 data:function(){ return { //函数形式 } } 2.引 ...
- CentOS7.5安装截图软件
一.Screenshot tool插件 这个插件直接在https://extensions.gnome.org/搜索,然后打开ON,等待安装完毕,就可以在你桌面的顶栏的右侧看到一个相机一样的小东西 缺 ...