大数据(9) - Flume的安装与使用
Flume简介 --(实时抽取数据的工具)
1) Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。
2) Flume基于流式架构,容错性强,也很灵活简单。
3) Flume、Kafka用来实时进行数据收集,Spark、Storm用来实时处理数据,impala用来实时查询。
Flume角色
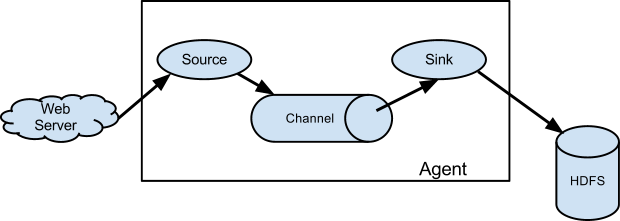
1、Source
用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel。
2、Channel
用于桥接Sources和Sinks,类似于一个队列。
3、Sink
从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)。
4、Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume传输过程
source监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event中,并put到channel后commit提交,channel队列先进先出,sink去channel队列中拉取数据,然后写入到HDFS中。
Flume部署及使用
1.下载并解压到指定目录
$ tar -zxf ~/softwares/installtions/apache-flume-1.7.0-bin.tar.gz -C ~/modules/
2.重命名文件,且修改配置文件。
cd /home/admin/modules/apache-flume-1.7.0-bin/conf 将所有带有template的文件去掉template 修改配置文件 flume-env.sh
(只需修改你对应的java安装路径即可) export JAVA_HOME=/home/admin/modules/jdk1.8.0_131
使用案例
案例一 :端口数据监控
1.先安装telnet,telnet rpm包 下载
$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm
$ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm
$ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm
2.创建案例一的文件夹,与配置文件
在Flume的根目录创建对应的文件夹 mkdir -p jobs/job1
3.创建项目对应的配置文件
cd /home/admin/modules/apache-flume-1.7.0-bin/jobs/job1 vim flume-telnet.conf # Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444 # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.判断44444端口是否被占用
$ sudo netstat -tunlp | grep 44444
5.先开启flume先听端口
在Flume的根目录下 $ bin/flume-ng agent --conf conf/ --name a1 --conf-file jobs/job1/flume-telnet.conf -Dflume.root.logger==INFO,console
6.使用telnet工具向本机的44444端口发送内容
克隆会话 $ telnet localhost 44444 然后随便输入点东西看Flume是否能够监看到发送的内容
案例二 :hive日志监控
1.下载并将hadoop jar包拉到flume的lib目录下
http://flume.apache.org/ 官方文档
cp ~/softwares/installtions/flume-hadoop-jar/* ~/modules/apache-flume-1.7.0-bin/lib/
2.创建项目二的文件夹与配置文件
mkdir jobs/job2 vim jobs/job2/flume-hdfs.conf # Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /home/admin/modules/apache-hive-1.2.2-bin/hive.log
a2.sources.r2.shell = /bin/bash -c # Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://linux01:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小副本数
a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
3.修改hive log 日志上传目录
vim /home/admin/modules/apache-hive-1.2.2-bin/conf/hive-log4j.properties hive.log.dir=/home/admin/modules/apache-hive-1.2.2-bin/logs 在hive的根目录创建logs文件夹 mkdir logs
4.启动案例2的flume任务
bin/flume-ng agent --conf conf/ --name a2 --conf-file jobs/job2/flume-hdfs.conf
5.新开会话,在新会话中启动hive。成功的话,hive的日志已经存到了hdfs上面的flume文件夹里面了
大数据(9) - Flume的安装与使用的更多相关文章
- 【大数据之数据仓库】安装部署GreenPlum集群
本篇将向大家介绍如何快捷的安装部署GreenPlum测试集群,大家可以跟着我一块儿实践一把^_^ 1.主机资源 申请2台网易云主机,操作系统必须是RedHat或者CentOS,配置尽量高一点.如果是s ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- 【大数据作业九】安装关系型数据库MySQL 安装大数据处理框架Hadoop
作业要求:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161 4.简述Hadoop平台的起源.发展历史与应用现状. 列举发展过程中 ...
- 大数据(13) - Spark的安装部署与简单使用
一 .Spark概述 官网:http://spark.apache.org 1. 什么是spark Spark是一种快速.通用.可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校 ...
- FusionInsight大数据开发---Flume应用开发
Flume应用开发 要求: 了解Flume应用开发适用场景 掌握Flume应用开发 Flume应用场景Flume的核心是把数据从数据源收集过来,在送到目的地.为了保证输送一定成功,发送到目的地之前,会 ...
- 【大数据】Linux下安装Hadoop(2.7.1)详解及WordCount运行
一.引言 在完成了Storm的环境配置之后,想着鼓捣一下Hadoop的安装,网上面的教程好多,但是没有一个特别切合的,所以在安装的过程中还是遇到了很多的麻烦,并且最后不断的查阅资料,终于解决了问题,感 ...
- 大数据之Flume
什么是Flume ApacheFlume是一个分布式的.可靠的.可用的系统,用于高效地收集.聚合和将大量来自不同来源的日志数据移动到一个集中的数据存储区. 系统要求 1. JDK 1.8 或以上版本 ...
随机推荐
- sparkStreaming读取kafka的两种方式
概述 Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka.flume.socket流等等.除了Kafka以外的实时输入源,由于我们的业务场景没有涉及,在此将不会讨论.本篇 ...
- [Functional Programming ADT] Adapt Redux Actions/Reducers for Use with the State ADT
By using the State ADT to define how our application state transitions over time, we clear up the ne ...
- Android技术——在Android中的随意视图中找控件
1.在非常多情况下,我们可能不知道控件的id,可是我们却希望在包括这个控件的视图中找到它,能够採用例如以下做法: 例:在Activity的根视图中找出当中全部的Button控件 private voi ...
- TestNG 七 annotation
TestNG中用到的annotation的快速预览及其属性. @BeforeSuite: 被注释的方法将在所有测试运行前运行 @AfterSuite: 被注释的方法将在所有测试运行后运行 @Be ...
- 前端性能优化:DocumentFragments或innerHTML取代复杂的元素注入
来源:GBin1.com 我们的浏览器执行越来越多的特性,并且网络逐渐向移动设备转移,使我们的前端代码更加紧凑,如何优化,就变得越来越重要了.前端给力的地方是可以有 许多种简单的策略和代码习惯让我们可 ...
- STL_算法_区间的比較(equal、mismatch、 lexicographical_compare)
C++ Primer 学习中.. . 简单记录下我的学习过程 (代码为主) //全部容器适用 equal(b,e,b2) //用来比較第一个容器[b,e)和第二个容器b2开头,是否相等 e ...
- 近期写的一个控件——Well Swipe beta 1.0
原文地址:http://blog.csdn.net/u013045971/article/details/51119507 近期花了大概一个半月的业余时间写的.从没有到有,中间也碰到了非常多的坑,一点 ...
- Uber 四年时间增长近 40 倍,背后架构揭秘
据报道,Uber 仅在过去4年的时间里,业务就激增了 38 倍.Uber 首席系统架构师 Matt Ranney 在一个非常有趣和详细的访谈<可扩展的 Uber 实时市场平台>中告诉我们 ...
- AWS RDS mysql无法连接的问题
rds创建后,无法连接mysql 检查安全组规则是否配置了 1. 2. 这样你的EC2就可以访问了.如果还不行,检查数据库是否和EC2在同一 VPC内. 官方文档:https://docs.amazo ...
- vue - webpack.dev.conf.js for CopyWebpackPlugin
描述:将单个文件或整个目录复制到构建目录 官网地址:https://www.npmjs.com/package/copy-webpack-plugin // 复制到自定义静态源 new CopyWeb ...