kafka 数据存储结构+原理+基本操作命令
数据存储结构:
Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
partition是以文件的形式存储在文件系统中,比如,创建了一个名为page_visits的topic,其有5个partition,那么在Kafka的数据目录中(由配置文件中的log.dirs指定的)中就有这样5个目录: page_visits-0, page_visits-1,page_visits-2,page_visits-3,page_visits-4,其命名规则为<topic_name>-<partition_id>,里面存储的分别就是这5个partition的数据。
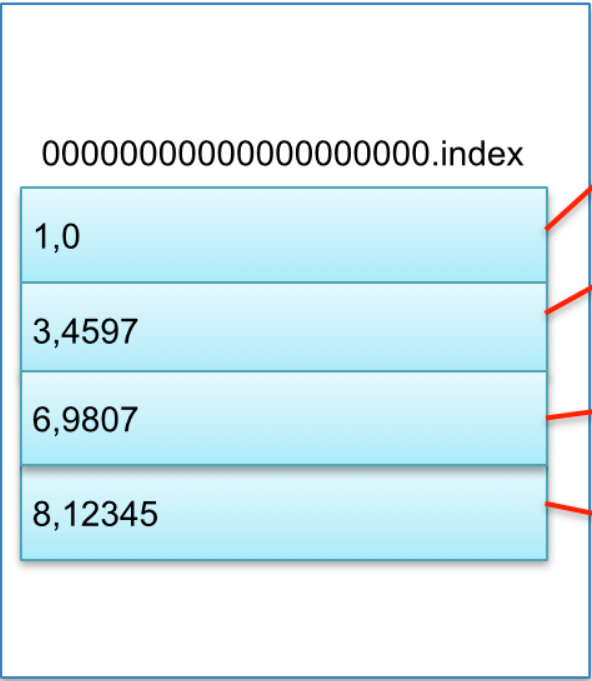
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。类似于下面的一个图片,消息存储在每个log文件中,index对应的是消息的索引信息,另外,为了让消息消费的时候更快,又将文件分成很多段。
数据消费查询:
我们要查询 offset 为7的消息,那kafka就会快速定位到这个index文件,得知offset 为7的消息在6,9807后面,这时候就可以通过9807快速定位到数据文件,然后从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
kafka 数据存储结构+原理+基本操作命令的更多相关文章
- 深度剖析HashMap的数据存储实现原理(看完必懂篇)
深度剖析HashMap的数据存储实现原理(看完必懂篇) 具体的原理分析可以参考一下两篇文章,有透彻的分析! 参考资料: 1. https://www.jianshu.com/p/17177c12f84 ...
- Atitit.数据库表的物理存储结构原理与架构设计与实践
Atitit.数据库表的物理存储结构原理与架构设计与实践 1. Oracle和DB2数据库的存储模型如图: 1 1.1. 2. 表数据在块中的存储以及RowId信息3 2. 数据表的物理存储结构 自然 ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- [转帖]Git数据存储的原理浅析
Git数据存储的原理浅析 https://segmentfault.com/a/1190000016320008 写作背景 进来在闲暇的时间里在看一些关系P2P网络的拓扑发现的内容,重点关注了Ma ...
- Cassandra 的数据存储结构——本质是SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>
Cassandra 的数据存储结构 Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型.它借鉴了 Amazon 的 Dynamo 和 Google's BigTab ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- 解决KafKa数据存储与顺序一致性保证
“严格的顺序消费”有多么困难 下面就从3个方面来分析一下,对于一个消息中间件来说,”严格的顺序消费”有多么困难,或者说不可能. 发送端 发送端不能异步发送,异步发送在发送失败的情况下,就没办法保证消息 ...
- Hashtable数据存储结构-遍历规则,Hash类型的复杂度为啥都是O(1)-源码分析
Hashtable 是一个很常见的数据结构类型,前段时间阿里的面试官说只要搞懂了HashTable,hashMap,HashSet,treeMap,treeSet这几个数据结构,阿里的数据结构面试没问 ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
随机推荐
- cdqz2017-test11-奇诺之旅(拟阵)
解为基环树森林 证明其具有拟阵的性质: 1.空集独立 2.基环树森林的子集仍然是基环树森林,满足遗传特性 3.对于基环树森林A,B,若|A|<|B| (边数),一定可以找到一条边e∈B,∉A,使 ...
- cmd 命令 添加端口
cmd 添加端口:netsh firewall add portopening tcp 45625 "telnet"
- Redis 主从模式
系统:Centos6.6x64安装目录:/usr/local/主:192.168.100.103从:192.168.100.104 ,下载安装: 安装依赖: # yum install gcc tcl ...
- HTML —— 小记
标签语义化 所谓标签语义化是要使HTML标签具备很好的可读性,可以清晰传达每个标签所要表达的意义,以方便其被友好的处理和解析(主要针对网络爬虫) 好处: 1.对搜索引擎友好,增加排名权重 2.对用户友 ...
- python(七) Python中单下划线和双下划线
Python中单下划线和双下划线: 一.分类 (1).以单下划线开头,表示这是一个保护成员,只有类对象和子类对象自己能访问到这些变量. 以单下划线开头的变量和函数被默认是内部函数,使用from mod ...
- Python 爬虫学习
#coding:utf-8 #author:Blood_Zero ''' 1.获取网页信息 2.解决编码问题,通过charset库(默认不安装这个库文件) ''' import urllib impo ...
- 使用Groovy的mixin方法注入,和mixedIn属性实现过滤链
mixin方法注入不多说,这里只是用这个属性搞一个过滤器链的功能 假设我现在有个方法,输入一个字符串,然后需求提出需要进行大写转换输出, 过了一天又要加个前缀,再过了一天,需要把一些字符过滤掉.... ...
- 【转】Python之列表生成式、生成器、可迭代对象与迭代器
[转]Python之列表生成式.生成器.可迭代对象与迭代器 本节内容 语法糖的概念 列表生成式 生成器(Generator) 可迭代对象(Iterable) 迭代器(Iterator) Iterabl ...
- Linux内存管理2---段机制
1.前言 本文所述关于内存管理的系列文章主要是对陈莉君老师所讲述的内存管理知识讲座的整理. 本讲座主要分三个主题展开对内存管理进行讲解:内存管理的硬件基础.虚拟地址空间的管理.物理地址空间的管理. 本 ...
- 【转】Source Insight中文注释为乱码的解决办法
我网上查了一堆解决办法,但是都是2017年以前的,并且都是针对于source insight 3.5及以下版本的解决方案,软件版本都到4.0了,应该有新方法出现. 干货:Source Insight ...