DBSCAN密度聚类
1. 密度聚类概念
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。
2. 密度聚类步骤

这个算法的关键是理解几个概念:
- 直接密度可达
- 密度可达
- 核心点
- 边界点
- 噪声点

# coding:utf-8
"""
@author = LPS
"""
import numpy as np
import matplotlib.pyplot as plt data = np.loadtxt('moon.txt')
n,m = data.shape
all_index = np.arange(n)
dis = np.zeros([n,n])
data = np.delete(data, m-1, axis=1) def dis_vec(a,b): # 计算两个向量的距离 if len(a)!=len(b):
return Exception
else:
return np.sqrt(np.sum(np.square(a-b))) for i in range(n): # 计算距离矩阵
for j in range(i):
dis[i,j] = dis_vec(data[i],data[j])
dis[j,i] = dis[i,j] def dbscan(s, minpts): # 密度聚类 center_points = [] # 存放最终的聚类结果
k = 0 # 检验是否进行了合并过程 for i in range(n):
if sum(dis[i] <= s) >= minpts: # 查看距离矩阵的第i行是否满足条件
if len(center_points) == 0: # 如果列表长为0,则直接将生成的列表加入
center_points.append(list(all_index[dis[i] <= s]))
else:
for j in range(len(center_points)): # 查找是否有重复的元素
if set(all_index[dis[i] <= s]) & set(center_points[j]):
center_points[j].extend(list(all_index[dis[i] <= s]))
k=1 # 执行了合并操作
if k==0 :
center_points.append(list(all_index[dis[i] <= s])) # 没有执行合并说明这个类别单独加入
k=0 lenc = len(center_points) # 以下这段代码是进一步查重,center_points中所有的列表并非完全独立,还有很多重复
# 那么为何上面代码已经查重了,这里还需查重,其实可以将上面的步骤统一放到这里,但是时空复杂的太高
# 经过第一步查重后,center_points中的元素数目大大减少,此时进行查重更快!
k = 0
for i in range(lenc-1):
for j in range(i+1, lenc):
if set(center_points[i]) & set(center_points[j]):
center_points[j].extend(center_points[i])
center_points[j] = list(set(center_points[j]))
k=1 if k == 1:
center_points[i] = [] # 合并后的列表置空
k = 0 center_points = [s for s in center_points if s != []] # 删掉空列表即为最终结果 return center_points if __name__ == '__main__':
center_points = dbscan(0.2,10) # 半径和元素数目
c_n = center_points.__len__() # 聚类完成后的类别数目
print (c_n)
ct_point = []
color = ['g','r','b','m','k']
noise_point = np.arange(n) # 没有参与聚类的点即为噪声点
for i in range(c_n):
ct_point = list(set(center_points[i]))
noise_point = set(noise_point)- set(center_points[i])
print (ct_point.__len__()) # 输出每一类的点个数
print (ct_point) # 输出每一类的点
print ("**********") noise_point = list(noise_point) for i in range(c_n):
ct_point = list(set(center_points[i]))
plt.scatter(data[ct_point,0], data[ct_point,1], color=color[i]) # 画出不同类别的点
plt.scatter(data[noise_point,0], data[noise_point,1], color=color[c_n], marker='h', linewidths=0.1) # 画噪声点
plt.show()
DBSCAN的主要优点有:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
DBSCAN的主要缺点有:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参相对于传统的K-Means之类的聚类算法稍复杂,不同的参数组合对最后的聚类效果有较大影响。
实验:
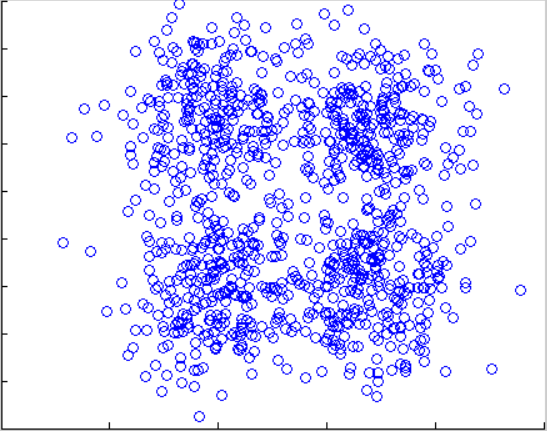
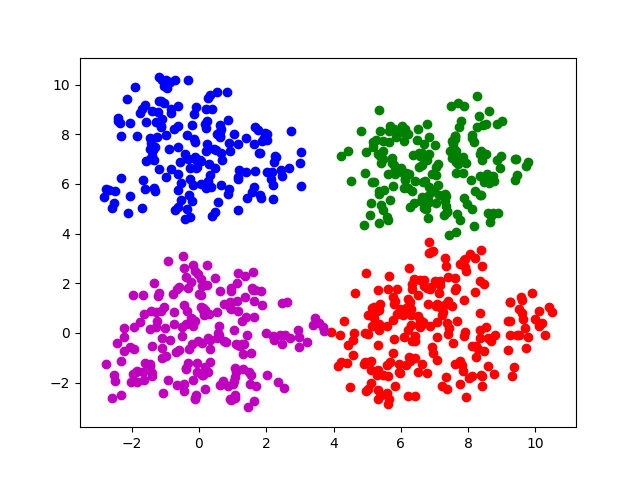

原图 square4 e=0.85 minpts = 13 square4-sklearn e=0.9 minpts=15
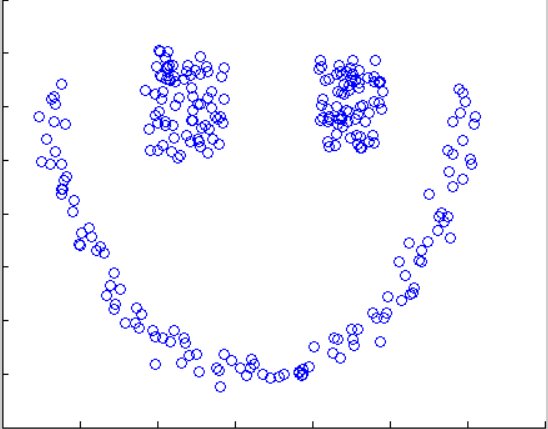
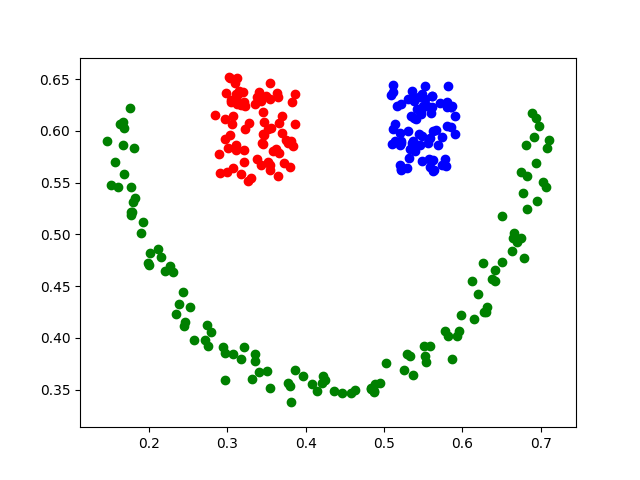
原图 结果图



原图 square1 1.185,8 square1 0.85 15

原图 结果图
原图 结果图
实验过程中:前几幅图由于分布比较密集,参数调整要很多次,后几张图因为分布比较分散,所以参数基本一次设置成功。
结果和资料已上传,下载~~~
DBSCAN密度聚类的更多相关文章
- DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- 【转】DBSCAN密度聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种很典型的密度聚类算法,和K-M ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 机器学习——dbscan密度聚类
完整版可关注公众号:大数据技术宅获取 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的有噪应用中的空间聚 ...
- 密度聚类 - DBSCAN算法
参考资料:python机器学习库sklearn——DBSCAN密度聚类, Python实现DBScan import numpy as np from sklearn.cluster impo ...
- 密度聚类 DBSCAN
刘建平:DBSCAN密度聚类算法 https://www.cnblogs.com/pinard/p/6208966.html API 的说明: https://www.jianshu.com/p/b0 ...
- Python之密度聚类
# -*- coding: utf-8 -*- """ Created on Tue Sep 25 10:48:34 2018 @author: zhen "& ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- [luogu4264][USACO18FEB]Teleportation
题解 先吐槽一波题目:便便传送门,出题人还真的有一点厉害的滑稽. 废话不多说. 首先问题的本质就是求如果当这个传送门的端点位于\(y\)的时候,最小的求出总代价,我们设为函数\(f(y)\). 因为这 ...
- hdu 2577 How to Type(dp)
Problem Description Pirates have finished developing the typing software. He called Cathy to test hi ...
- 原生js操作option
<script type="text/javascript"> // 1.动态创建select function createSelect() { var mySele ...
- 线程的状态有哪些,线程中的start与run方法的区别
线程在一定条件下,状态会发生变化.线程一共有以下几种状态: 1.新建状态(New):新创建了一个线程对象. 2.就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法. ...
- shell中脚本变量和函数变量的作用域
http://blog.csdn.net/ltx19860420/article/details/5570902 1. shell脚本中定义的变量是global的,其作用域从被定义的地方开始,到she ...
- frp源码剖析-frp中的log模块
前言&引入 一个好的log模块可以帮助我们排错,分析,统计 一般来说log中需要有时间.栈信息(比如说文件名行号等),这些东西一般某些底层log模块已经帮我们做好了.但在业务中还有很多我们需要 ...
- yolov2-tiny-voc.cfg 参数解析
一.参数解析 [net] batch=64 # number of images pushed with a forward pass through the network subdivisions ...
- Struts2中遇到的问题
问题1: 最近在学习的时候用到了Struts2.5,在一系列操作之后Tomcat部署成功了,然而之后在测试的时候却出现了问题,网页无法正常响应,并且报出了Wrong method was define ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- 面向对象【day07】:多态(九)
本节内容 概述 多态 小结 一.概述 多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作 ...