[转]Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
https://medium.com/@ranko.mosic/reinforcement-learning-based-trading-application-at-jp-morgan-chase-f829b8ec54f2
FT released a story today about the new application that will optimize JP Morgan Chase trade execution ( Business Insider article on the same topic for readers that do not have FT subscription ). The intent is to reduce market impact and provide best trade execution results for large orders.
It is a complex application with many moving parts:
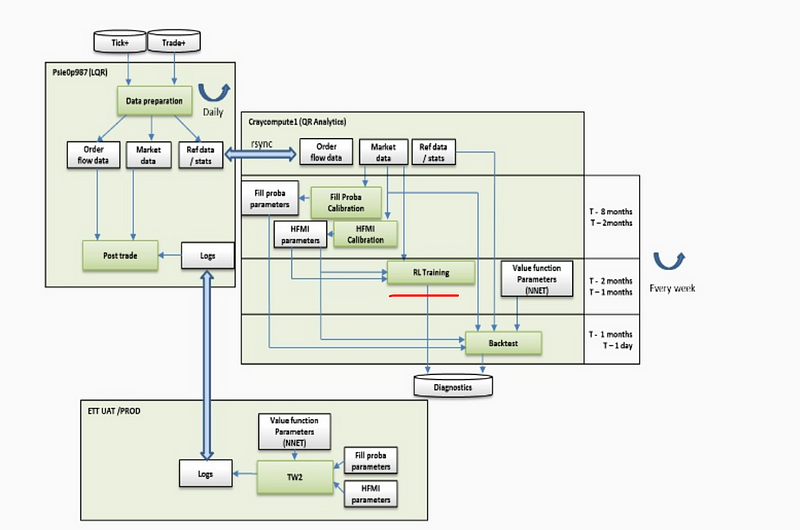
Its core is an RL algorithm that learns to perform the best action ( choose optimal price, duration and order size ) based on market conditions. It is not clear if it is Sarsa ( On-Policy TD Control) or Q-learning (Off-Policy Temporal Difference Control Algorithm ) as both algorithms are present in JP Morgan slides:
Sarsa

Q-learning
State consists of price series, expected spread cost, fill probability, size placed, as well as elapsed time, %progress, etc. Rewards are immediate rewards ( price spread ) and terminal ( end of episode ) rewards like completion, order duration and market penalties ( obviously those are negative rewards that punish the agent along these dimensions ).
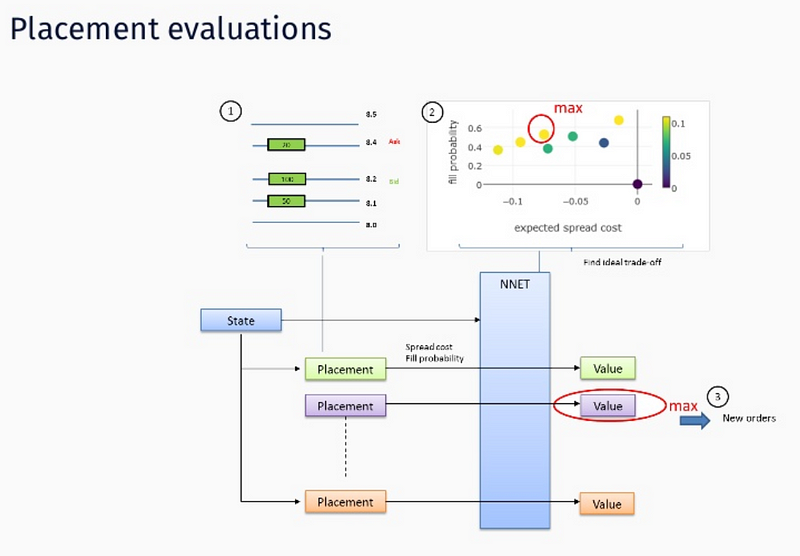
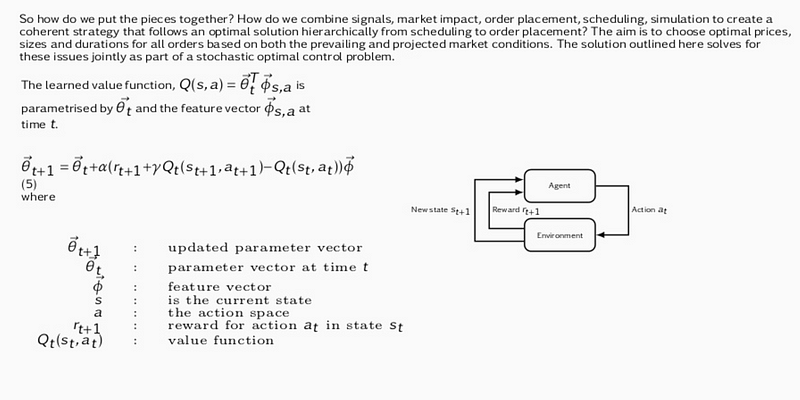
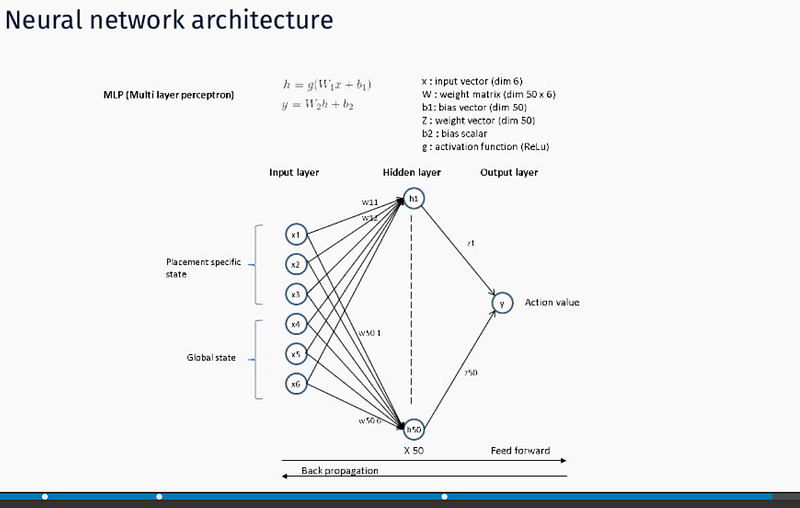
Actions are memorized as weights of a Deep Neural Network — function approximation via NN is used since state, action space is too big to be handled in tabular form. We assume stochastic gradient descent is used for both feed forward and backprop operation operation ( hence Deep designation ):
JP Morgan is convinced this is the very first real time trading AI/ML application on Wall Street. We are assuming this is not true i.e. there are surely other players operating in this space as RL implementation to order execution is known for quite a while now ( Kearns and Nevmyvaka 2006 ).
The latest LOXM developmentswill be presented at QuantMinds Conference in Lisbon (May of 2018).
Instinet is also using Q-learning, probably for the same purpose ( market impact reduction ).
[转]Deep Reinforcement Learning Based Trading Application at JP Morgan Chase的更多相关文章
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- 论文笔记:Learning how to Active Learn: A Deep Reinforcement Learning Approach
Learning how to Active Learn: A Deep Reinforcement Learning Approach 2018-03-11 12:56:04 1. Introduc ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
随机推荐
- Oracle11g温习-第二十章:数据装载 sql loader
2013年4月27日 星期六 10:53 1. sql loader :将外部数据(比如文本型)数据导入oracle database.(用于数据导入.不同类型数据库数据迁移) 2.sqlloade ...
- 函数使用十二:BAPI_MATERIAL_BOM_GROUP_CREATE(CS61)
REPORT ZSM_CREATE_SIMPLEBOM.* This code will create a material BoM for the material* MAINMATERIAL wi ...
- Jmeter4.0----录制脚本
1.前言 Jmeter录制脚本有两种方式.1.通过第三方工具录制比如:Badboy,然后转化为jmeter可用的脚本:2.使用jmeter本身自带的录制脚本功能. 对于测试小白来说可用先使用jmete ...
- [CodeForces - 614E] E - Necklace
E - Necklace Ivan wants to make a necklace as a present to his beloved girl. A necklace is a cyclic ...
- [CodeForces - 614B] B - Gena's Code
B - Gena's Code It's the year 4527 and the tanks game that we all know and love still exists. There ...
- WeRun is mini-app
WeRun is a mini-app within WeChat that allows users to monitor their daily step count. One of its mo ...
- jformdesigner 开发
jformdesigner 开发 1● 破解jformadesigner 脑补 2● 建立jfd文件 3● 移动关联 <file leaf-file-name=" ...
- matlab plot line settings
- vue项目如何打包前后端不分离发布手把手教学apache、nginx
vue项目如何不分离发布 1.首先yarn build 我用了vue-cli脚手架,bulid后的dist文件夹里的index.html有加版本号,那么为什么需要加版本号呢? a.回滚 b.解决浏览器 ...
- laravel获取的数据转换为数组
当构建 JSON API 时,您可能常常需要把模型和关联对象转换成数组或JSON.所以Eloquent里已经包含了这些方法.要把模型和已载入的关联对象转成数组,可以使用 toArray方法: $use ...