大数据学习(03)——HDFS的高可用
高可用架构图
先上一张搜索来的图。
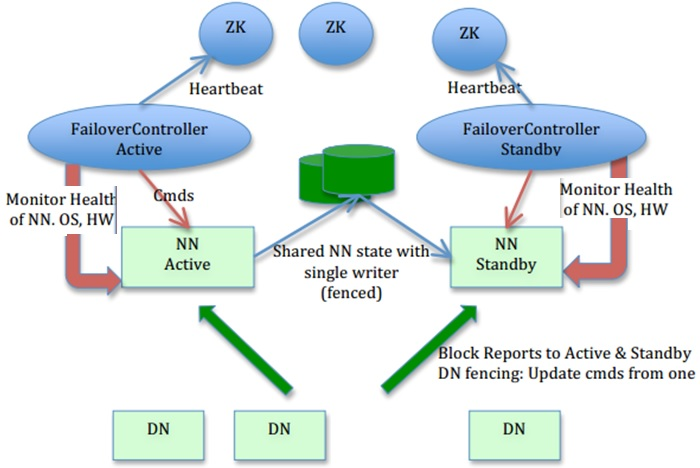
如上图,HDFS的高可用其实就是NameNode的高可用。
上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameNode完成日志合并的工作,在NameNode出现问题时不能顶上去。
在高可用里,不再有SecondaryNameNode这个角色,Hadoop2.x版本支持NameNode的一主一备,3.x版本支持一主多备,由备机完成日志合并任务。某个时点只有主NameNode对外提供服务。
总结一下,在一个高可用的HDFS集群里,至少需要这么几个角色:
- DataNode,存数据的节点,没它就不能叫文件系统了
- NameNode,有两个或多个,主节点状态是Active,备节点状态是Standby,备节点来同步、合并、推送主节点的FsImage
- 共享存储,存放的是主节点的实时日志,备节点从共享存储里异步同步日志,官方有QJM和NFS两种实现
为了实现NameNode的自动切换,还需要这两个角色:
- Zookeeper,分布式协调器,NameNode选主用的
- ZKFS,Zookeeper客户端,监控NameNode状态,并与Zookeeper保持长连接,与NameNode在一台机器上部署
高可用原理
它的高可用步骤如下:
- 在配置文件中配置多个NameNode属于同一个cluster,启动hdfs后,NameNode通过zookeeper选主
- 客户端通过dfs.client.failover.proxy.provider.[clusterID]配置的策略去访问NameNode,通常是向所有的NameNode发送请求来判断哪个是主节点
- 客户端对主NameNode发起的操作会同步写入共享存储,这里不直接写入其他NameNode是为了避免由于NameNode故障引起响应超时
- DataNode把文件的Block信息发送给所有的NameNode
- 备NameNode按照时间间隔或者日志文件大小来合并主NameNode的FsImage
- 如果主节点的NameNode或者ZKFS挂了
- 如果主NameNode挂了,本机的ZKFS会将ZK集群的锁释放,并回调其他ZKFS的方法,通知它们来拿锁。拿到锁的ZKFS连接一下原来的主NameNode,发现确实挂了,再把本机的NameNode状态由Standby修改为Active。
- 如果ZKFS挂了,ZKFS与ZK的TCP连接会断掉。ZK集群将删除该ZKFS持有的锁,并回调其他ZKFS的方法,通知它们来拿锁。拿到锁的ZKFS连接一下原来的主NameNode,发现它还活着,ZKFS先把原来的主NameNode降级为Standby,再把本机的NameNode升为Active。
高可用环境搭建
Hadoop的官方文档讲的很详细,参考 《用QJM实现HDFS的高可用》
HDFS联邦
一个主NameNode里存放的元数据毕竟容量有限,在数据量大的时候,很可能无法满足需要。
HDFS联邦机制类似于HDFS的分片存储,把所有元数据分散在多个NameNode里,互相没有交集。
那么客户端怎么知道要访问的数据该连接哪一个NameNode呢?这涉及到在多个NameNode之上增加一个抽象层的问题,由抽象层来确定到底该访问哪一个NameNode。
大数据学习(03)——HDFS的高可用的更多相关文章
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
随机推荐
- excel VBA中正则模块vbscript.regexp的用法
一.是一个对象,用于执行 正则表达式! 二.有三个属性: 1. Global属性: True or False, 指明模式是匹配整个字符串中所有与之相符的地方还是只匹配第一次出现的地方.默认 ...
- Linux中系统时间同步ntpdate简介
Linux服务器运行久时,系统时间就会存在一定的误差,一般情况下可以使用date命令进行时间设置,但在做数据库集群分片等操作时对多台机器的时间差是有要求的,此时就需要使用ntpdate进行时间同步.所 ...
- flyway实现java 自动升级SQL脚本
flyway实现java 自动升级SQL脚本 为什么要用Flyway 在日常开发中,我们经常会遇到下面的问题: 自己写的SQL忘了在所有环境执行: 别人写的SQL我们不能确定是否都在所有环境执行过了: ...
- (数据科学学习手札124)pandas 1.3版本主要更新内容一览
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 就在几天前,pandas发布了其1.3版本 ...
- centos 8 下解压.tar.gz文件
执行命令 tar 参数 文件名 参数: -c :建立一个压缩文件的参数指令(create 的意思): -x :解开一个压缩文件的参数指令: -t :查看 tarfile 里面的文件: 特别注意,在参数 ...
- centos7安装chrome+chromeDriver+Xvfb
安装chrome 创建yum源 # cd /etc/yum.repos.d/ # vim google-chrome.repo 创建yum源信息 [google-chrome] name=google ...
- SpringCloud:扩展zuul配置路由访问
继续上次整合SpringCloud的demo进行扩展zuul:https://www.cnblogs.com/nhdlb/p/12555968.html 这里我把zuul划分出一个模块单独启动 创建 ...
- Spring:Spring-IOC容器、DI依赖注入简介
Spring容器到底是什么? 从概念上讲:Spring 容器是 Spring 框架的核心,是用来管理对象的.容器将创建对象,把它们连接在一起,配置它们,并管理他们的整个生命周期从创建到销毁. 从具象化 ...
- Spring:Spring事务手动回滚方式
方法1: 在service层方法的catch语句中增加:TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();语句 ...
- jvm代码热替换过程中异常
BTrace java.lang.NoClassDefFoundError: javax/xml/bind/JAXBException 具体如下: 1. 信这个问题很多小伙伴已经遇到了,这是在你的jd ...