【mybatis源码学习】mybtias一级,二级缓存
转载:https://www.cnblogs.com/ysocean/p/7342498.html
mybatis 为我们提供了一级缓存和二级缓存,可以通过下图来理解:

①、一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
②、二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
1、一级缓存
①、我们在一个 sqlSession 中,对 User 表根据id进行两次查询,查看他们发出sql语句的情况。
@Test
public void testSelectOrderAndUserByOrderId(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession = sessionFactory.openSession();
String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID";
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper.selectUserByUserId(1);
System.out.println(u1); //第二次查询,由于是同一个sqlSession,会在缓存中查找查询结果
//如果有,则直接从缓存中取出来,不和数据库进行交互
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2); sqlSession.close();
}
查看控制台打印情况:

②、 同样是对user表进行两次查询,只不过两次查询之间进行了一次update操作。
@Test
public void testSelectOrderAndUserByOrderId(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession = sessionFactory.openSession();
String statement = "one.to.one.mapper.OrdersMapper.selectOrderAndUserByOrderID";
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper.selectUserByUserId(1);
System.out.println(u1); //第二步进行了一次更新操作,sqlSession.commit()
u1.setSex("女");
userMapper.updateUserByUserId(u1);
sqlSession.commit(); //第二次查询,由于是同一个sqlSession.commit(),会清空缓存信息
//则此次查询也会发出 sql 语句
User u2 = userMapper.selectUserByUserId(1);
System.out.println(u2); sqlSession.close();
}
控制台打印情况:

③、总结
1、第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
2、如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
3、第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
2、二级缓存
二级缓存的原理和一级缓存原理一样,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于 sqlSession 的,而 二级缓存是基于 mapper文件的namespace的,也就是说多个sqlSession可以共享一个mapper中的二级缓存区域,并且如果两个mapper的namespace相同,即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。
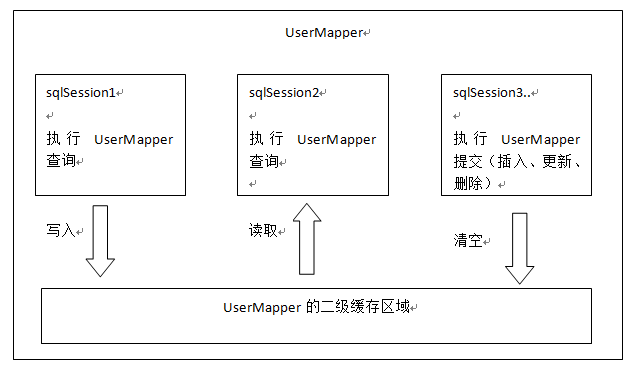
那么二级缓存是如何使用的呢?
①、开启二级缓存
和一级缓存默认开启不一样,二级缓存需要我们手动开启
首先在全局配置文件 mybatis-configuration.xml 文件中加入如下代码:
<!--开启缓存 -->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
其次在 UserMapper.xml 文件中开启缓存
<!-- 开启二级缓存 -->
<cache></cache>
我们可以看到 mapper.xml 文件中就这么一个空标签<cache/>,其实这里可以配置<cache type="org.apache.ibatis.cache.impl.PerpetualCache"/>,PerpetualCache这个类是mybatis默认实现缓存功能的类。我们不写type就使用mybatis默认的缓存,也可以去实现 Cache 接口来自定义缓存。
我们可以看到 二级缓存 底层还是 HashMap 架构。
开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口。
③、测试
一、测试二级缓存和sqlSession 无关
public void testTwoCache(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
String statement = "com.ys.twocache.UserMapper.selectUserByUserId";
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper1.selectUserByUserId(1);
System.out.println(u1);
sqlSession1.close();//第一次查询完后关闭sqlSession
//第二次查询,即使sqlSession1已经关闭了,这次查询依然不发出sql语句
User u2 = userMapper2.selectUserByUserId(1);
System.out.println(u2);
sqlSession2.close();
}
可以看出上面两个不同的sqlSession,第一个关闭了,第二次查询依然不发出sql查询语句。
二、测试执行 commit() 操作,二级缓存数据清空
@Test
public void testTwoCache(){
//根据 sqlSessionFactory 产生 session
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
SqlSession sqlSession3 = sessionFactory.openSession(); String statement = "com.ys.twocache.UserMapper.selectUserByUserId";
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3 = sqlSession2.getMapper(UserMapper.class);
//第一次查询,发出sql语句,并将查询的结果放入缓存中
User u1 = userMapper1.selectUserByUserId(1);
System.out.println(u1);
sqlSession1.close();//第一次查询完后关闭sqlSession //执行更新操作,commit()
u1.setUsername("aaa");
userMapper3.updateUserByUserId(u1);
sqlSession3.commit(); //第二次查询,由于上次更新操作,缓存数据已经清空(防止数据脏读),这里必须再次发出sql语句
User u2 = userMapper2.selectUserByUserId(1);
System.out.println(u2);
sqlSession2.close();
}
查看控制台情况:

④、useCache和flushCache
mybatis中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id="selectUserByUserId" useCache="false" resultType="com.ys.twocache.User" parameterType="int">
select * from user where id=#{id}
</select>
这种情况是针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存,直接从数据库中获取。
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。
设置statement配置中的flushCache=”true” 属性,默认情况下为true,即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
<select id="selectUserByUserId" flushCache="true" useCache="false" resultType="com.ys.twocache.User" parameterType="int">
select * from user where id=#{id}
</select>
一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存,这样可以避免数据库脏读。所以我们不用设置,默认即可。
3、二级缓存整合ehcache
上面我们介绍了mybatis自带的二级缓存,但是这个缓存是单服务器工作,无法实现分布式缓存。那么什么是分布式缓存呢?假设现在有两个服务器1和2,用户访问的时候访问了1服务器,查询后的缓存就会放在1服务器上,假设现在有个用户访问的是2服务器,那么他在2服务器上就无法获取刚刚那个缓存,如下图所示:

为了解决这个问题,就得找一个分布式的缓存,专门用来存储缓存数据的,这样不同的服务器要缓存数据都往它那里存,取缓存数据也从它那里取,如下图所示:

3、二级缓存的应用场景
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分的,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题可能需要在业务层根据需求对数据有针对性缓存。
【mybatis源码学习】mybtias一级,二级缓存的更多相关文章
- mybatis源码学习(三)-一级缓存二级缓存
本文主要是个人学习mybatis缓存的学习笔记,主要有以下几个知识点 1.一级缓存配置信息 2.一级缓存源码学习笔记 3.二级缓存配置信息 4.二级缓存源码 5.一级缓存.二级缓存总结 1.一级缓存配 ...
- mybatis源码学习:一级缓存和二级缓存分析
目录 零.一级缓存和二级缓存的流程 一级缓存总结 二级缓存总结 一.缓存接口Cache及其实现类 二.cache标签解析源码 三.CacheKey缓存项的key 四.二级缓存TransactionCa ...
- Mybatis源码分析之Cache二级缓存原理 (五)
一:Cache类的介绍 讲解缓存之前我们需要先了解一下Cache接口以及实现MyBatis定义了一个org.apache.ibatis.cache.Cache接口作为其Cache提供者的SPI(Ser ...
- mybatis源码分析之06二级缓存
上一篇整合redis框架作为mybatis的二级缓存, 该篇从源码角度去分析mybatis是如何做到的. 通过上一篇文章知道,整合redis时需要在FemaleMapper.xml中添加如下配置 &l ...
- mybatis源码学习:基于动态代理实现查询全过程
前文传送门: mybatis源码学习:从SqlSessionFactory到代理对象的生成 mybatis源码学习:一级缓存和二级缓存分析 下面这条语句,将会调用代理对象的方法,并执行查询过程,我们一 ...
- mybatis源码学习:插件定义+执行流程责任链
目录 一.自定义插件流程 二.测试插件 三.源码分析 1.inteceptor在Configuration中的注册 2.基于责任链的设计模式 3.基于动态代理的plugin 4.拦截方法的interc ...
- Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口 在这里贴一下Mybatis查询体系结构图 Executor组件分析 E ...
- mybatis源码学习(一) 原生mybatis源码学习
最近这一周,主要在学习mybatis相关的源码,所以记录一下吧,算是一点学习心得 个人觉得,mybatis的源码,大致可以分为两部分,一是原生的mybatis,二是和spring整合之后的mybati ...
- Mybatis源码学习之整体架构(一)
简述 关于ORM的定义,我们引用了一下百度百科给出的定义,总体来说ORM就是提供给开发人员API,方便操作关系型数据库的,封装了对数据库操作的过程,同时提供对象与数据之间的映射功能,解放了开发人员对访 ...
- Mybatis源码学习第八天(总结)
源码学习到这里就要结束了; 来总结一下吧 Mybatis的总体架构 这次源码学习我们,学习了重点的模块,在这里我想说一句,源码的学习不是要所有的都学,一行一行的去学,这是错误的,我们只需要学习核心,专 ...
随机推荐
- IOS应用内支付IAP从零开始详解
前言 什么是IAP,即in-app-purchase 这几天一直在搞ios的应用内购,查了很多博客,发现几乎没有一篇博客可以完整的概括出所有的点,为了防止大伙多次查阅资料,所以写了这一篇博客,希望大家 ...
- window.open()打开页面
一.window.open()支持环境:JavaScript1.0+/JScript1.0+/Nav2+/IE3+/Opera3+ 二.基本语法:window.open(pageURL,name,pa ...
- 修改Host,配置域名访问
修改Host,配置域名访问 虽然我们已经能够通过localhost访问本地网站了,为了提高逼格,我们可以修改host文件,设置一个自己喜欢的域名指向本地网站,岂不是更高大上. 明确需求 通过配置, ...
- hdu3377
题解: 简单的插头dp 加上一个代价即可 代码: #include<cstdio> #include<cmath> #include<cstring> #inclu ...
- ppt点击文字出现图片,再次点击消失
实现效果:在PPT一个页面的任意位置,单击左键,出现图片:在图片上,单击左键,图片消失 实现思路:给图片做两个动画,一个进入,文字作触发器,另一个退出,图片本身为触发器. 实现方法: 1.选中图片…… ...
- 双引号与尖括号的区别 and 相对路径与绝对路径
包含头文件的时候,如果包含的是自己写的头文件是用" " .如果是包含系统的头文件,一般用<>. 相对路径与绝对路径
- [ZJOI2008]泡泡堂BNB
这个题...是一道神奇的贪心题... 根据田忌赛马的原理... 先假使两队都符合田忌和齐王的配置... 我们可以发现如果我们用当前最弱的...去和对方当前最强的打... 然后一直按照这个方案...当我 ...
- Spring实现Ioc的多种方式--控制反转、依赖注入、xml配置的方式实现IoC、对象作用域
Spring实现Ioc的多种方式 一.IoC基础 1.1.概念: 1.IoC 控制反转(Inversion of Control) IoC是一种设计思想. 2.DI 依赖注入 依赖注入是实现IoC的一 ...
- python random模块(获取随机数)
如果要使用random模块,需要先导入 import random 1.random.random() #用于生成一个0到1的随机浮点数 2.random.uniform(a,b) #用于生成一个 ...
- day 60 pyMySQL 的安装及其 增删改查的应用
一 pyMySQL 的安装 1 在pyCharm 中安装pyMySQL 这个模块取决能否顺利链接到MySQL 2 可以在 cod 中 添加 pip install pyMySQL 3 在cmd 中 ...