[elk]logstash统计api访问失败率
处理原始日志
日志从moogoo导出来的
{ "mobile" : "13612345678", "isp" : "中国移动_广东", "time" : ISODate("2017-10-16T18:39:51.245Z"), "success" : true }
要解决时间问题:
logstash修改时间
发现日志已是json格式,想用date插件实现time字段赋值给@timestap字段,未果.(因为之前做的都是非json格式日志的时间匹配,先grok 后date)
改造日志为:
{"mobile" : "15812345606", "province": "上海", "isp": "中国移动","@timestamp" : "2017-12-06T09:30:51.244Z", "success" : "false"}
{"mobile" : "15812345607", "province": "河北", "isp": "中国移动","@timestamp" : "2017-12-06T09:20:51.244Z", "success" : "true"}
{"mobile" : "15812345607", "province": "河北", "isp": "中国联通","@timestamp" : "2017-12-06T09:22:51.244Z", "success" : "false"}
{"mobile" : "15812345608", "province": "广东", "isp": "中国移动","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : "true"}
{"mobile" : "15812345608", "province": "广东", "isp": "中国移动","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : "false"}
{"mobile" : "15812345608", "province": "广东", "isp": "中国电信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : "false"}
这样日志@timestamp的时间就是日志文件的时间了.
统一日志统计需求
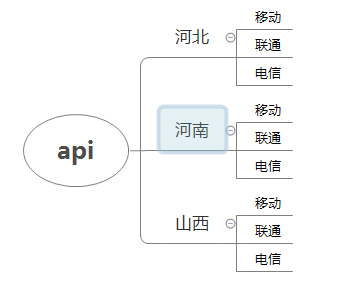
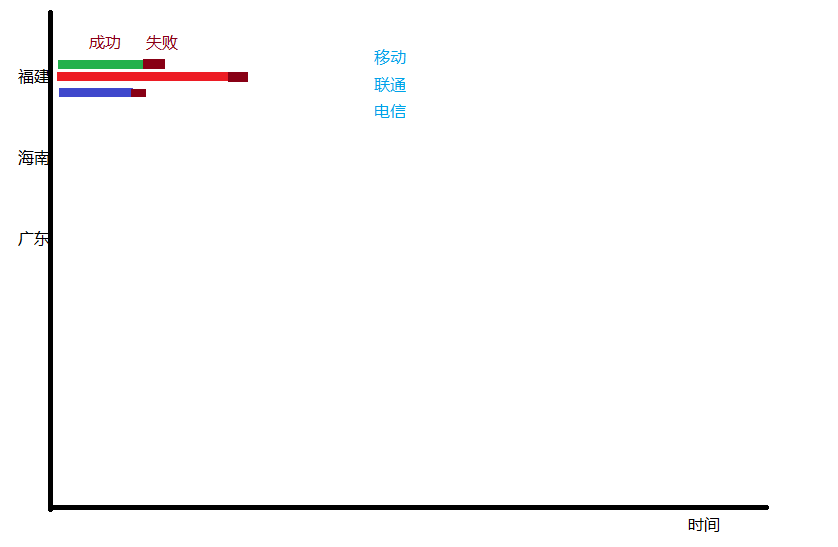
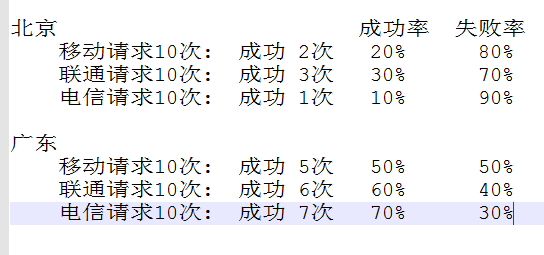
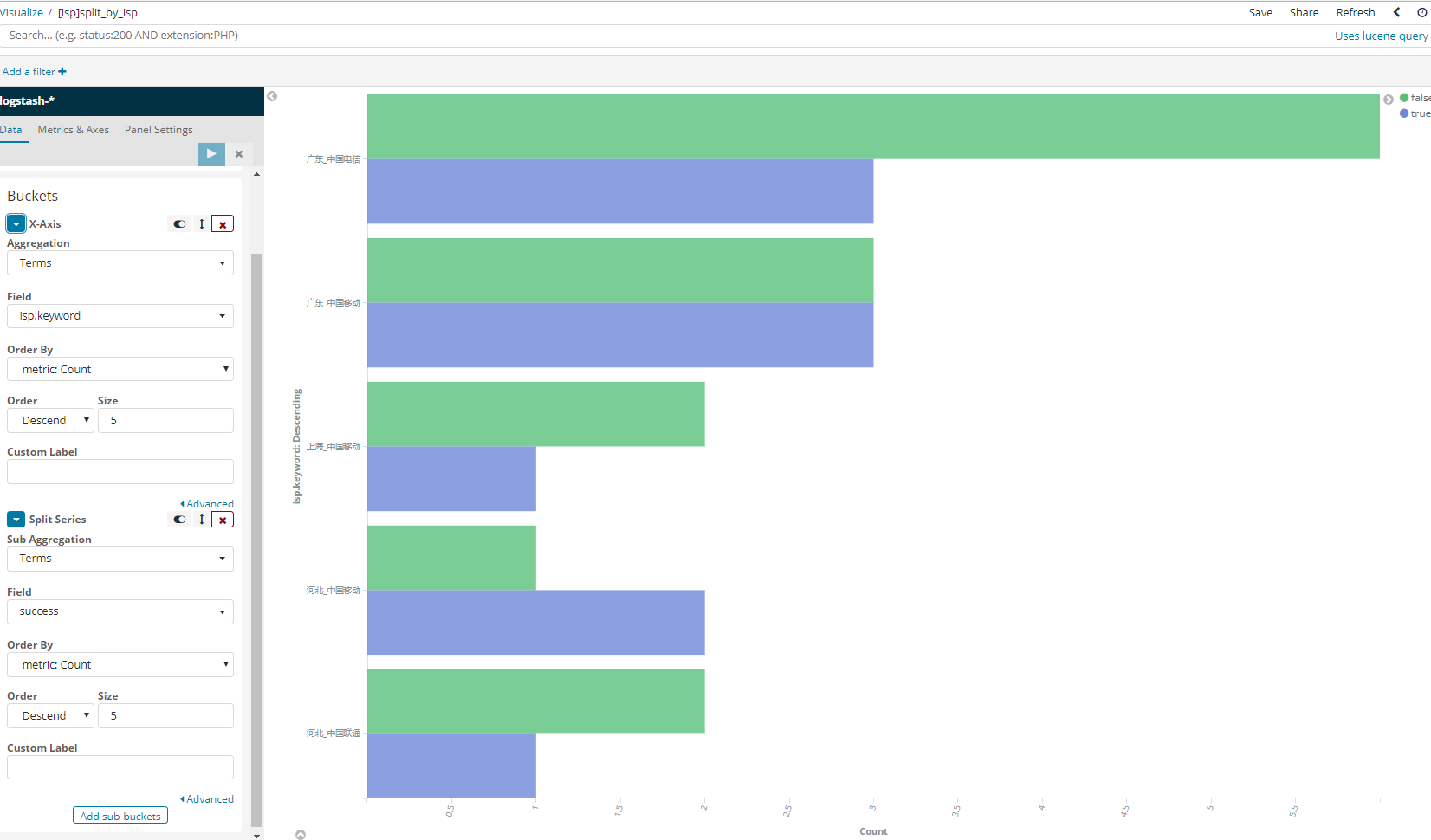
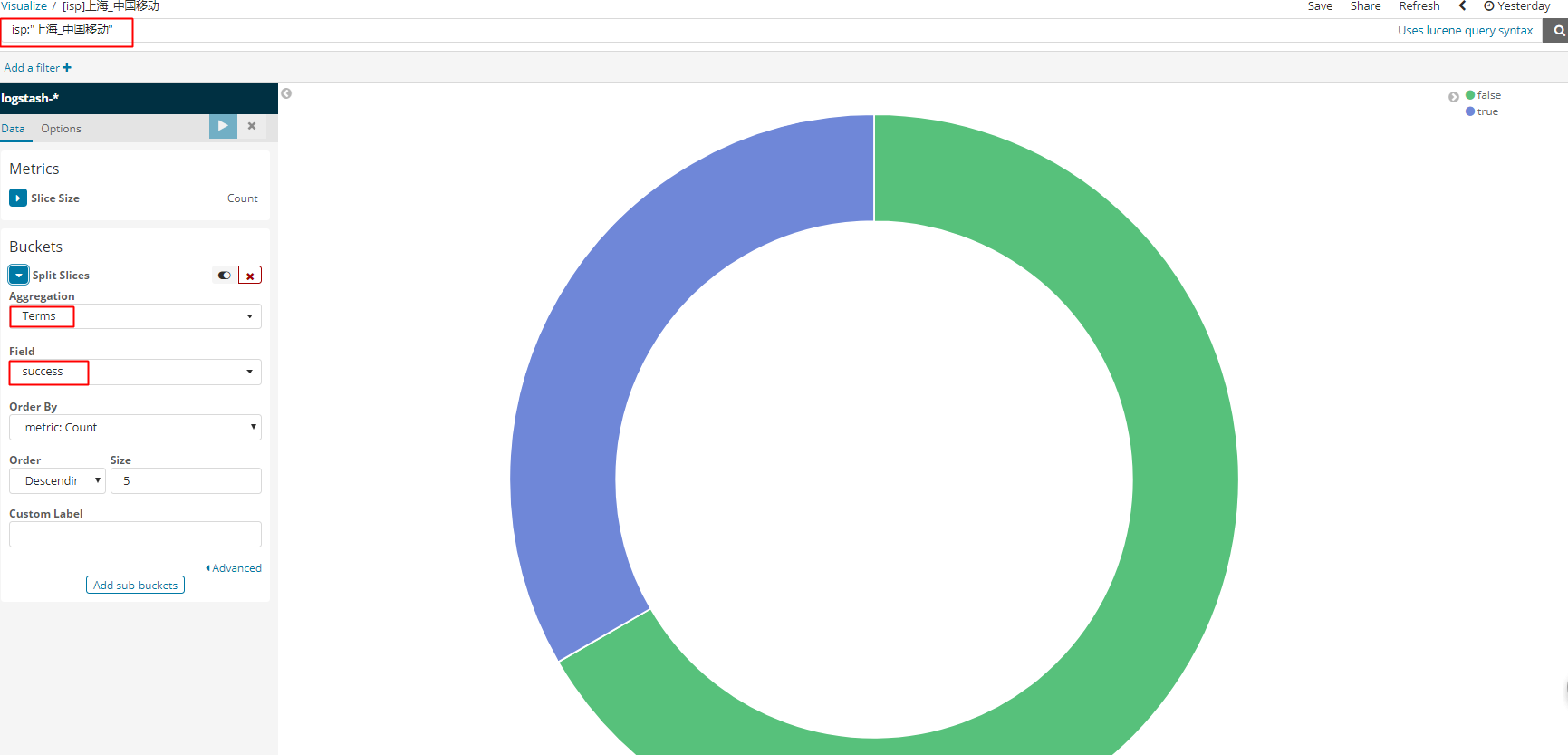
上面的几幅图基本说明了问题:三级分, 第一级: 按照省份分 第二级: 按照isp分 第三级: 每个isp的标出成功失败比例
进一步处理日志:
mutate 拆封字段
input { stdin { codec => "json" } }
filter {
if [success] == "true" { // 这里true必须是字符串,否则lg启动会报错
mutate { rename => ["sucess", "status_true"] }
}
else {
mutate { rename => ["sucess", "status_false"] }
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => [ "localhost:9200" ]
}
}
即把日志的 "success" : "false" 拆分成2个字段:
status_true:true
status_false:false
中途遇到的问题:
codec => json失效.
原因是: json数据中间本来逗号 不小心少了个逗号mutate 没成功
日志是
{"mobile" : "15812345608", "province": "广东", "isp": "中国电信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : false}
改日志为
# 最后一个字段改成字符串即可
{"mobile" : "15812345608", "province": "广东", "isp": "中国电信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : "false"}
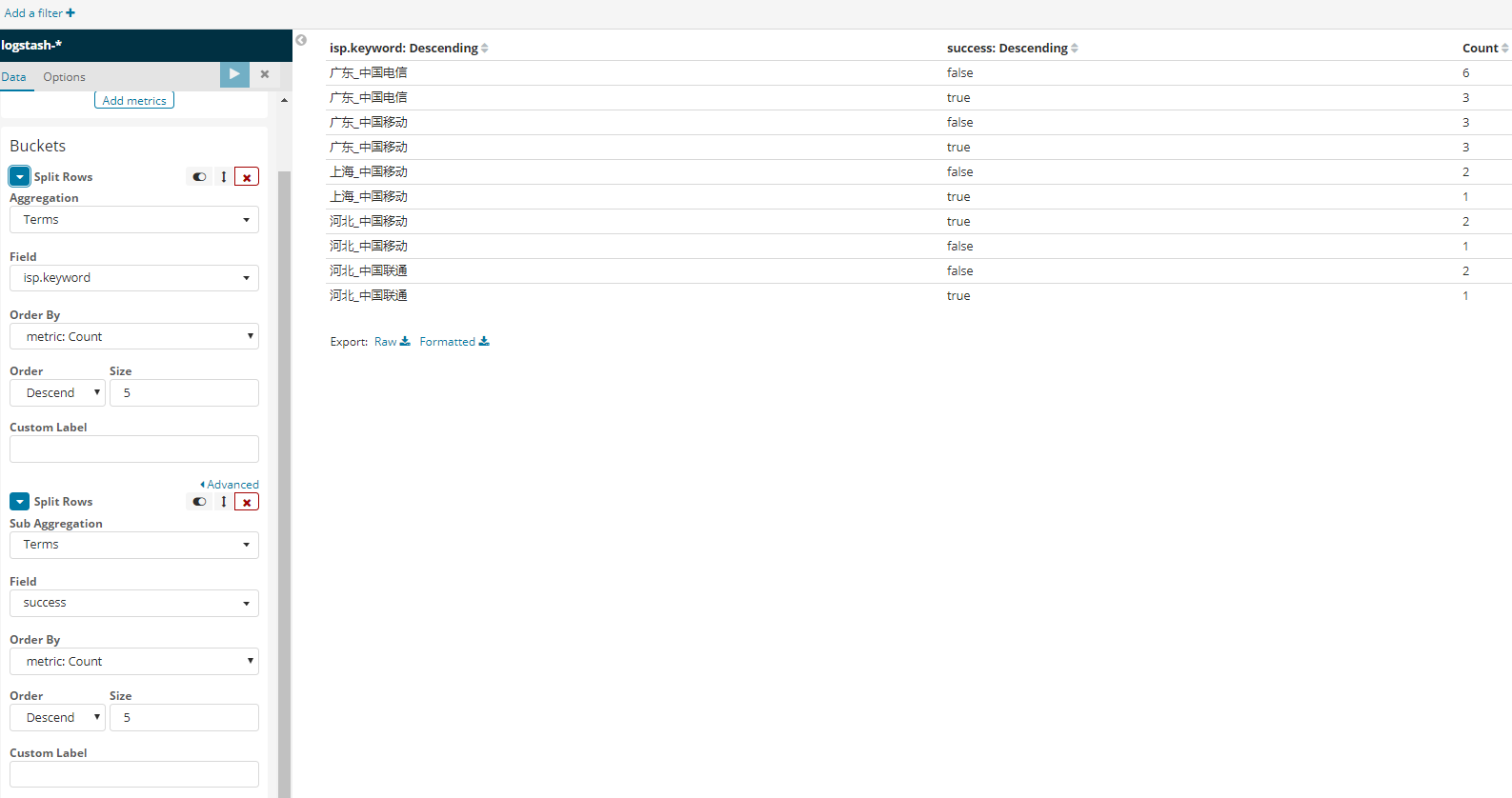
最终日志入库展示
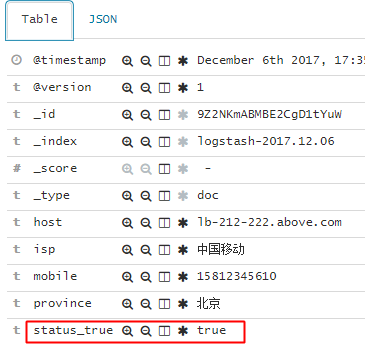
接下来就是kibana出图了
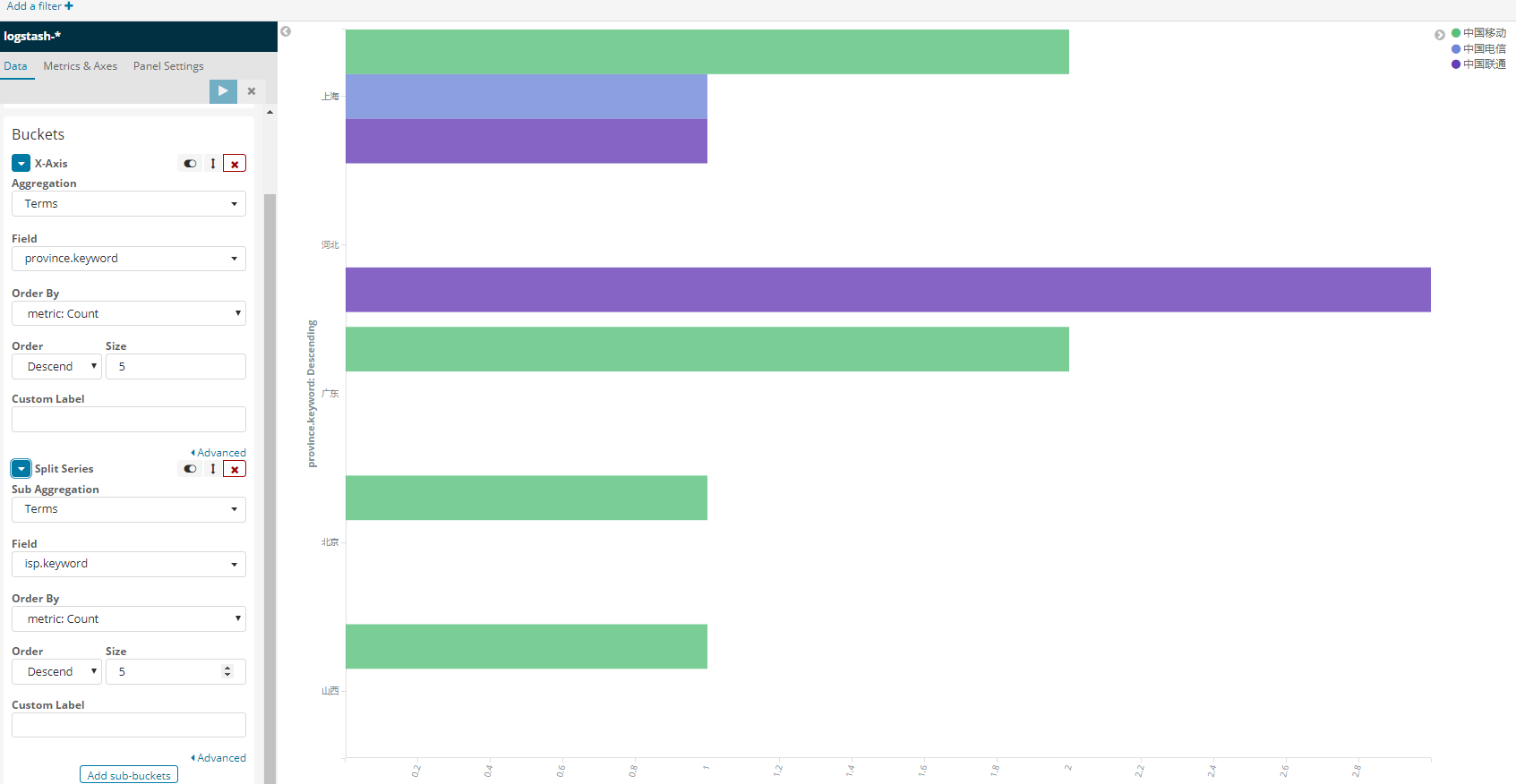
但目标是
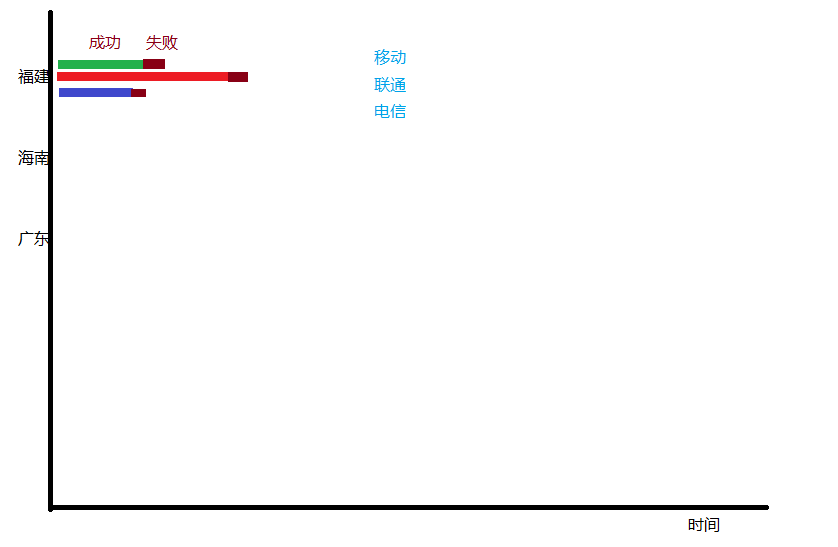
目前还没实现百分比.
既然他能分两级我就这样排序: 能看到个数了
todo: 研究百分比
{"mobile" : "15812345606", "isp": "上海_中国移动","@timestamp" : "2017-12-06T09:30:51.244Z", "success" : false}
{"mobile" : "15812345607", "isp": "河北_中国移动","@timestamp" : "2017-12-06T09:20:51.244Z", "success" : true}
{"mobile" : "15812345607", "isp": "河北_中国联通","@timestamp" : "2017-12-06T09:22:51.244Z", "success" : false}
{"mobile" : "15812345608", "isp": "广东_中国移动","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : true}
{"mobile" : "15812345608", "isp": "广东_中国移动","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : false}
{"mobile" : "15812345608", "isp": "广东_中国电信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : false}
{"mobile" : "15812345608", "isp": "广东_中国电信","@timestamp" : "2017-12-06T09:23:51.244Z", "success" : true}
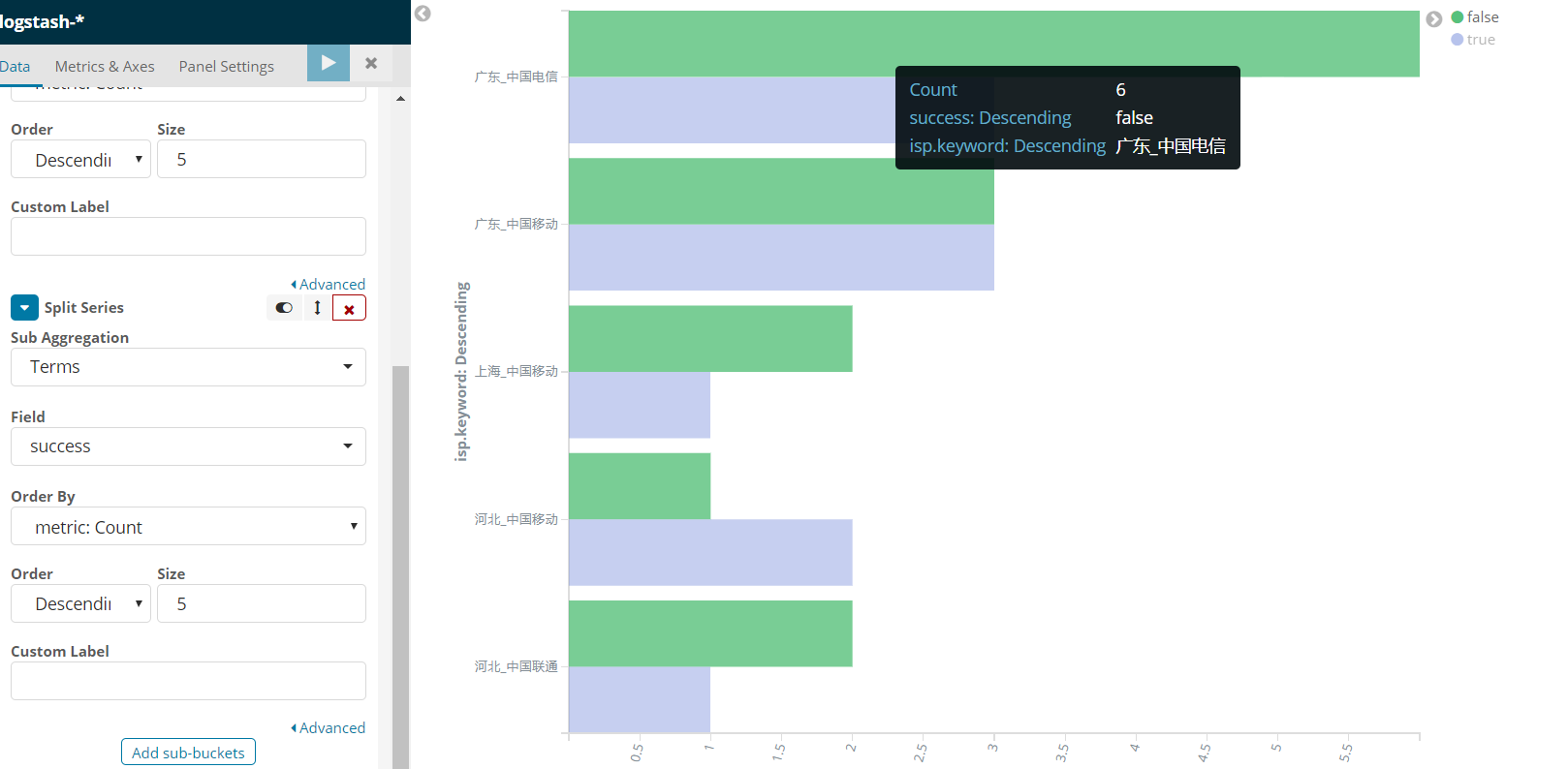
最后折衷了下,采用目前方案
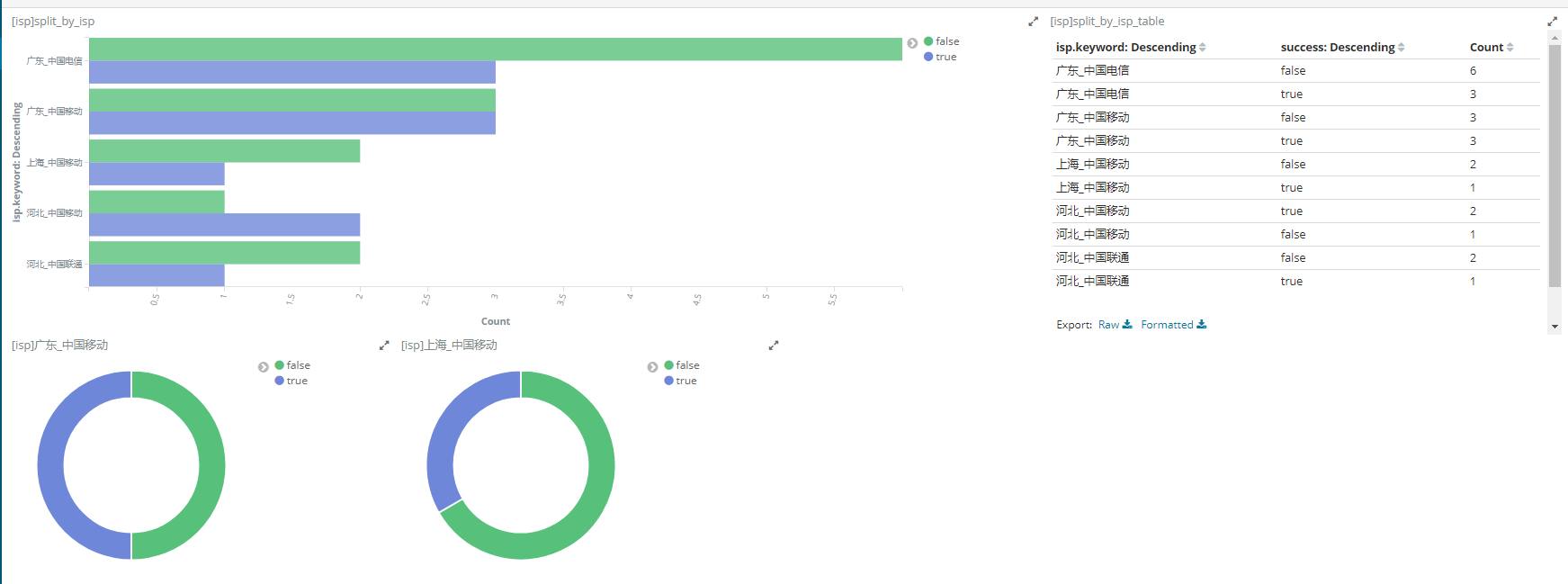
绘制方法:
[elk]logstash统计api访问失败率的更多相关文章
- 百度统计API的使用
百度统计API的使用 在搭建自己博客的时候,希望自己能有个日志系统,能够看到PV.UV等信息,同时自己也搭建了个ELK系统,可惜服务器配置太低(1GHZ+1G内存),根本运行不起来.只能使用第三方的日 ...
- logstash收集nginx访问日志
logstash收集nginx访问日志 安装nginx #直接yum安装: [root@elk-node1 ~]# yum install nginx -y 官方文档:http://nginx.org ...
- Python获得百度统计API的数据并发送邮件
Python获得百度统计API的数据并发送邮件 小工具 本来这么晚是不准备写博客的,当是想到了那个狗子绝对会在开学的时候跟我逼逼这个事情,所以,还是老老实实地写一下吧. Baidu统计API的使 ...
- 使用MTA HTML5统计API来分析数据
使用MTA HTML5统计API来分析数据 在开发个人博客的时候,用到了腾讯移动分析(MTA),相比其他数据统计平台来说我喜欢她的简洁高效,易上手,同时文档也比较全面,提供了数据接口供用户调用. 在看 ...
- ELK——Logstash 2.2 date 插件【翻译+实践】
官网地址 本文内容 语法 测试数据 可配置选项 参考资料 date 插件是日期插件,这个插件,常用而重要. 如果不用 date 插件,那么 Logstash 将处理时间作为时间戳.时间戳字段是 Log ...
- 5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01.02.03.04.05.06.07的分布式集群的HA测试 1) weekend01.02的hdfs的HA测试 2) weekend03.04的yarn的HA测试 1) wee ...
- API访问客户端
API访问客户端(WebApiClient适用于MVC/WebForms/WinForm) 这几天没更新主要是因为没有一款合适的后端框架来支持我们的Web API项目Demo, 所以耽误了几天, 目前 ...
- ELK logstash 处理MySQL慢查询日志(初步)
写在前面:在做ELK logstash 处理MySQL慢查询日志的时候出现的问题: 1.测试数据库没有慢日志,所以没有日志信息,导致 IP:9200/_plugin/head/界面异常(忽然出现日志数 ...
- asp.net core系列 57 IS4 使用混合流(OIDC+OAuth2.0)添加API访问
一.概述 在上篇中,探讨了交互式用户身份验证,使用的是OIDC协议. 在之前篇中对API访问使用的是OAuth2.0协议.这篇把这两个部分放在一起,OpenID Connect和OAuth 2.0组合 ...
随机推荐
- 《CUDA并行程序设计:GPU编程指南》
<CUDA并行程序设计:GPU编程指南> 基本信息 原书名:CUDA Programming:A Developer’s Guide to Parallel Computing with ...
- gpu和cpu区别
GPU的功耗远远超过CPUCache, local memory: CPU > GPU Threads(线程数): GPU > CPURegisters: GPU > CPU 多寄存 ...
- 3)Linux程序设计入门--文件操作
)Linux程序设计入门--文件操作 Linux下文件的操作 前言: 我们在这一节将要讨论linux下文件操作的各个函数. 文件的创建和读写 文件的各个属性 目录文件的操作 管道文件 .文件的创建和读 ...
- ThreadLocal实现session中用户信息 的线程间共享
转载自:http://blog.sina.com.cn/s/blog_4b5bc01101013gok.html ThreadLocal并不难理解,我总结的最简单的理解就是: ThreadLocal像 ...
- ElementUI表单验证使用
1.设计校验方式: 我们表单验证的rules一般封装一个单独的js文件,比如我之前写的这个博客: ElementUI使用问题记录:设置路由+iconfont图标+自定义表单验证 可以修改下:公共的校验 ...
- 【干货合集】Docker快速入门与进阶
收录待用,修改转载已取得腾讯云授权 Docker 在众多技术中,绝对是当红炸子鸡.这年头,如果你不懂一点容器,不学一些Docker,还怎么出去跟人炫耀技术? Docker 也是云计算技术中较为热门的一 ...
- Tensorflow 深度学习简介(自用)
一些废话,也可能不是废话.可能对,也可能不对. 机器学习的定义:如果一个程序可以在任务T上,随着经验E的增加,效果P也可以随之增加,则称这个程序可以在经验中学习. “程序”指的是需要用到的机器学习算法 ...
- Python 数据驱动工具:DDT
背景 python 的unittest 没有自带数据驱动功能. 所以如果使用unittest,同时又想使用数据驱动,那么就可以使用DDT来完成. DDT是 “Data-Driven Tests”的缩写 ...
- 【JavaScript】2013年人气最高的JavaScript框架排名
本文概述 本文介绍2013年人气急速上升,2014年必须知道的JavaScript框架排名.本文所介绍的排名为Google根据全世界2013年的搜索关键词所做出的统计结果. MVC框架 JavaScr ...
- 流编辑器sed
sed与grep一样,都起源于老式的ed编辑器,因其是一个流编辑器(stream editor)而得名.与vi等编辑器不同,sed是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑 ...