批量自动化生成PDF目录标签
所需软件:
1. FreePic2Pdf(网上很容易找到)
2. python3
3. 天若OCR
搜狗OCR配置:https://tianruoocr.cn/interface/Txt_sougou.html
免费版调用的是百度的OCR,对于这种目录的识别效果不好,经过尝试发现只有搜狗的效果是最好的,所以如果有需要还是购买专业版,然后配置搜狗的OCR
实现方法:
1. 提取书签内容文本

许多英文书籍PDF的文字是可以直接复制粘贴的,这种情况比较好处理,直接复制出来,暂时保存到文本中。
如果为扫描版PDF,则可以用上面提供的天若OCR进行识别,然后提取文字内容,识别率挺高,不算太麻烦。
最后得到目录内容:
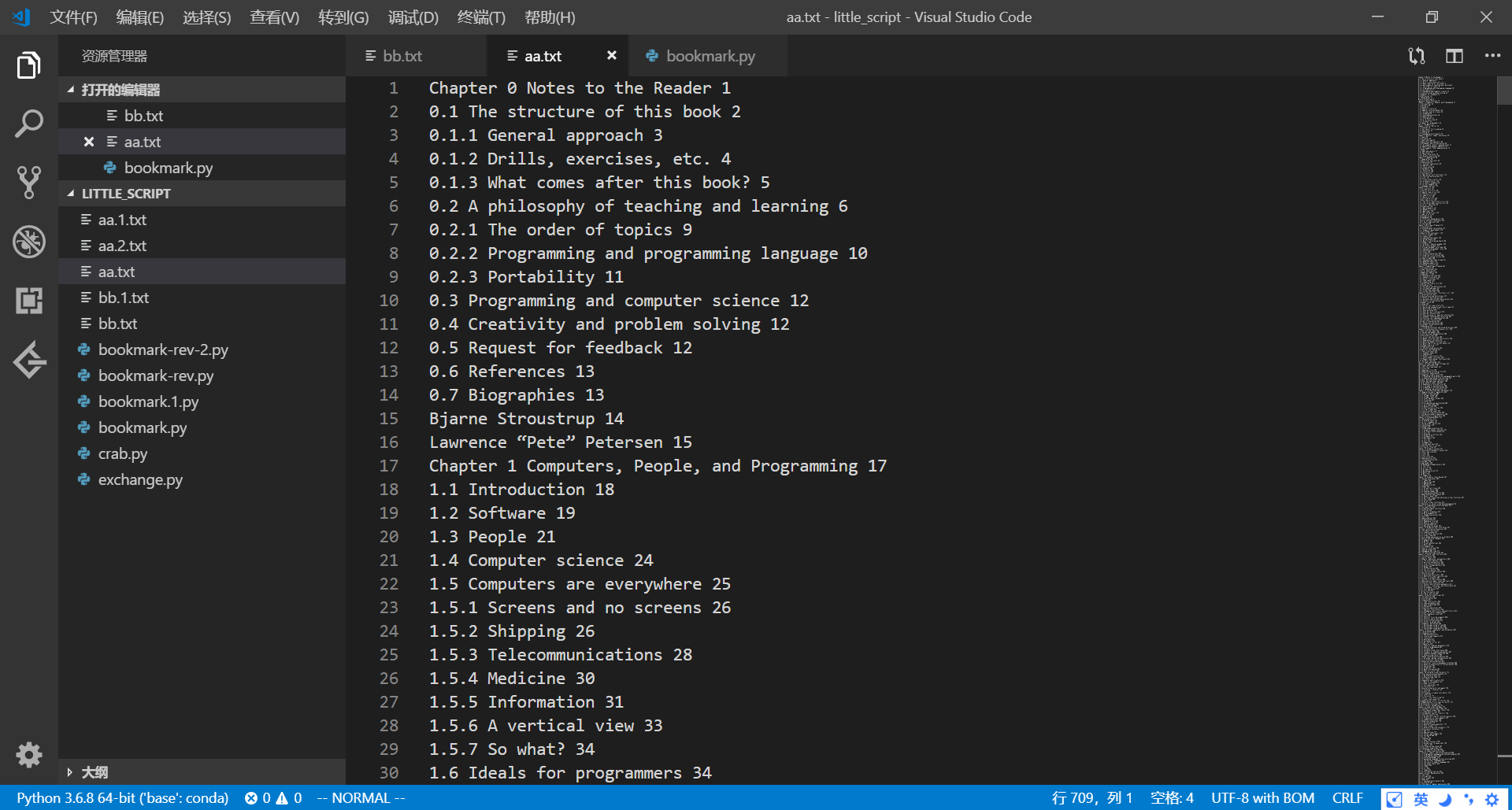
如果是用OCR软件识别的内容,有时候会有一些多余的符号,影响下面python脚本的运行,最常见的是:
1)目录出现换行,导致该行最后一个字符不是数字,脚本无法正确运行,会报错;
2)行末的数字前出现一些多余符号,也会影响脚本运行,一个个手动修改太麻烦,可以在VScode里用vim批量操作。如:

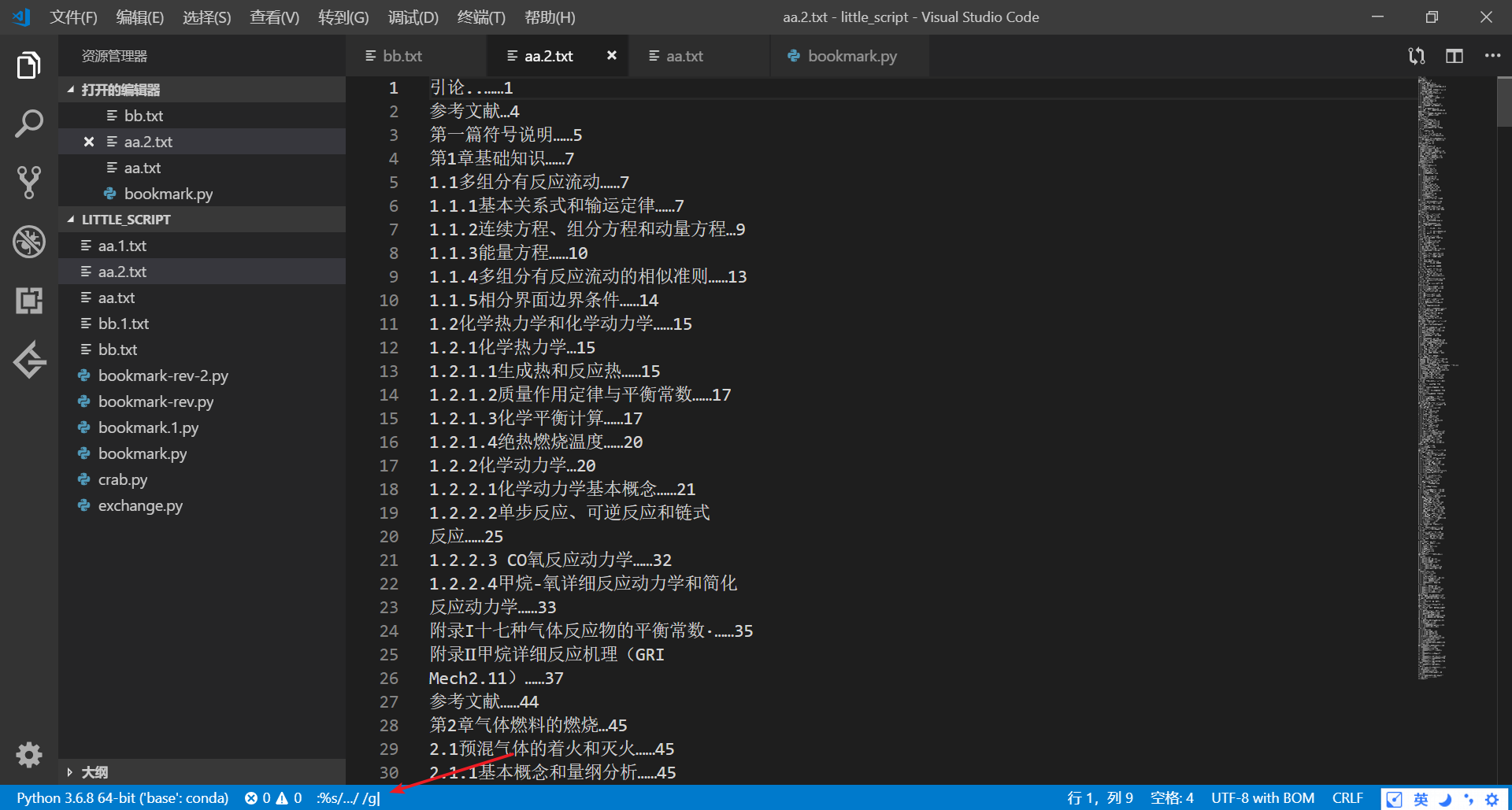
上面输入的替换命令为:
%s/…/ /g
用vim里:模式下的替换命令,上面表示把…全部替换成空格。注意VScode里的vim插件可以在替换命令里粘贴内容,但是我在terminal的vim里似乎不行,有些字符奇怪字符有时候不知道怎么打,可以直接粘贴过去。
%s/(待替换内容)/(替换内容)/g
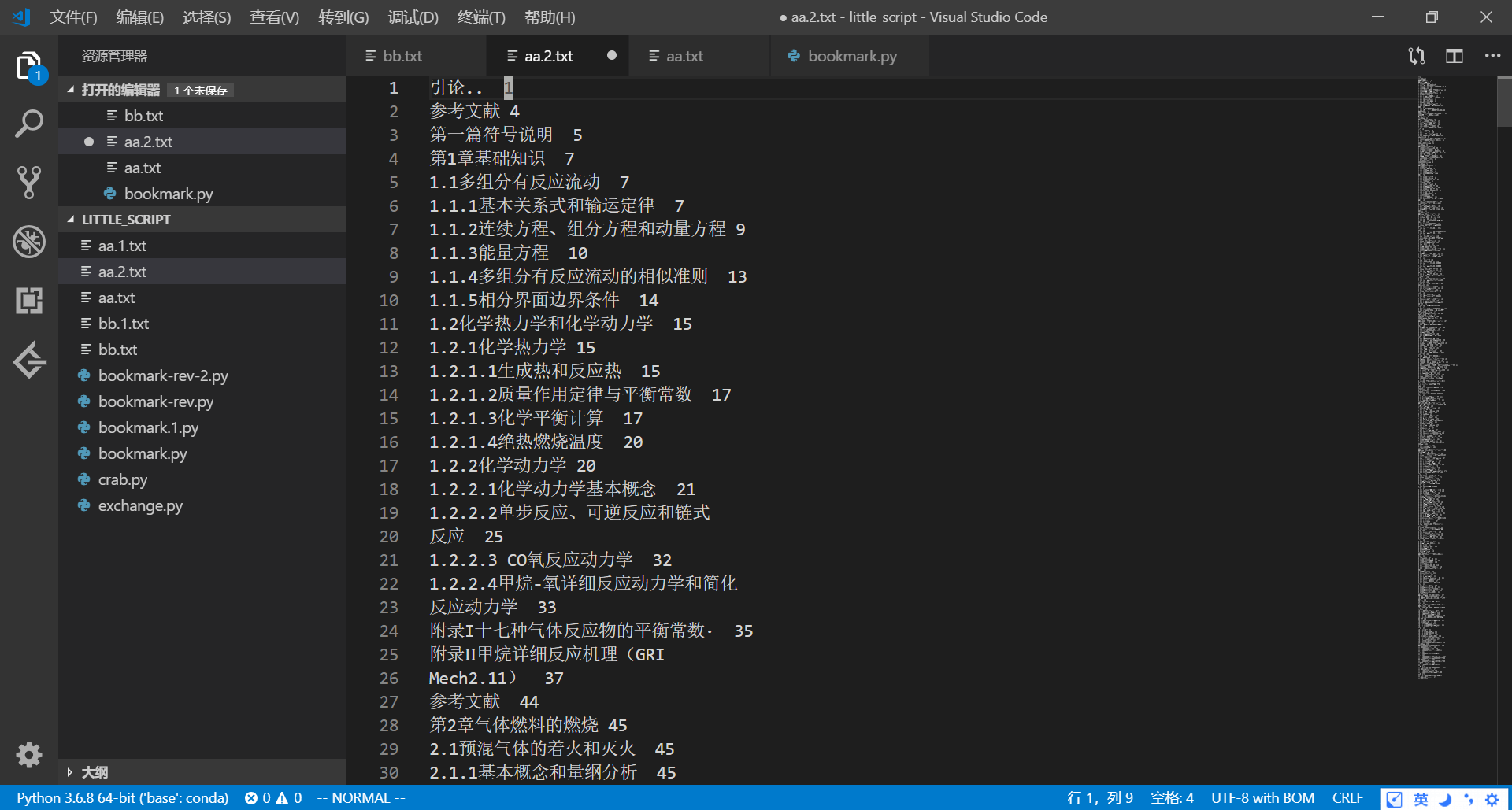
2. 在同一工作目录下运行如下python脚本
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
'''
@Author: Yin Weijie
@Date: 2018.5.25
@Description:
替换页码
@Revised Date: 2019.3.7
@Description:
在次级目录前加tab
''' fin = open("aa.txt", "r")
fout = open("bb.txt", "w") for each_line in fin:
list = each_line.split()
for i in range(len(list) - 1): #倒数第一个元素是数字,先不放
if (list[i] == '.'):
continue
# 这里章数默认不超过两位数
if ((len(list[i]) > 1 and list[i][1] == '.') or (len(list[i]) > 2 and list[i][2] == '.')):
fout.write('\t')
fout.write(list[i])
fout.write(' ')
# print(list[i])
fout.write('\t')
num = int(list[-1]) + 0 #单独处理倒数第一个数字
fout.write(str(num)) fout.write("\n") fin.close()
fout.close()
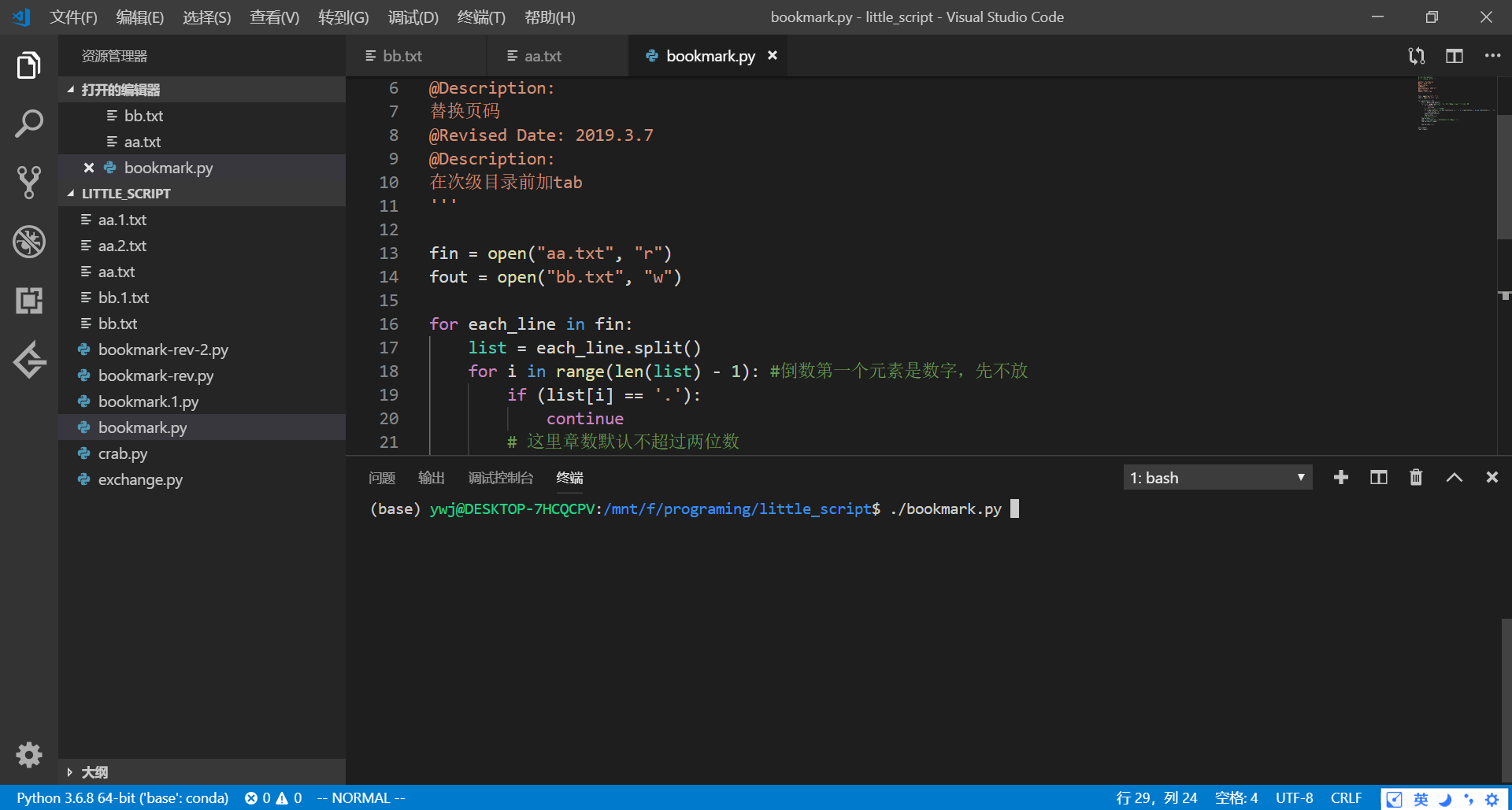
得到文件bb.txt的内容:

这里实际上就是做一个文本替换,为后面FreePic2Pdf使用作准备。因为FreePic2Pdf只能识别固定格式的书签内容,主要有如下几方面需要修改:
1)页码是PDF中的绝对页码,通常需要加减一个差值,但是这个PDF的排版比较特殊,书中的页码内容和PDF绝对页码内容一致,否则上面python代码中
num = int(list[-1]) + 0 #单独处理倒数第一个数字
这一行加的数字应该是PDF绝对页码和书籍页码的差值。
2)页码数字和前面的文字之间应该是\tab,而不是空格。
3)每行行首也可以加\tab,表示次级目录。也可以加多个\tab增加更多目录层级,这里只做了一个次级目录。
3. 用FreePic2Pdf批量插入标签

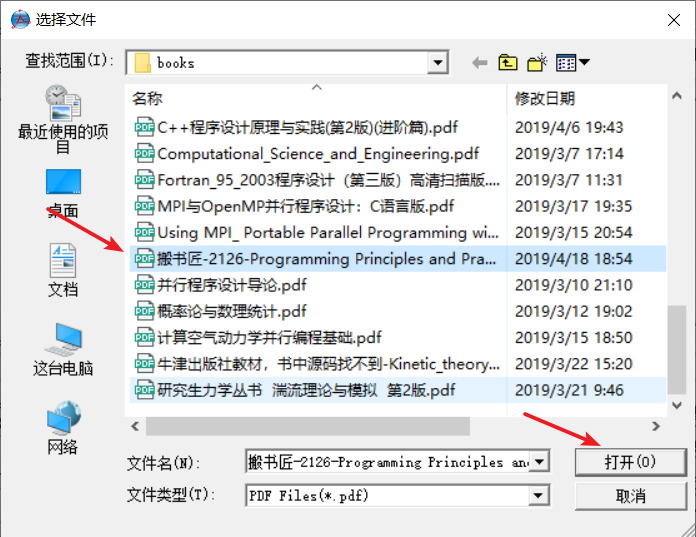
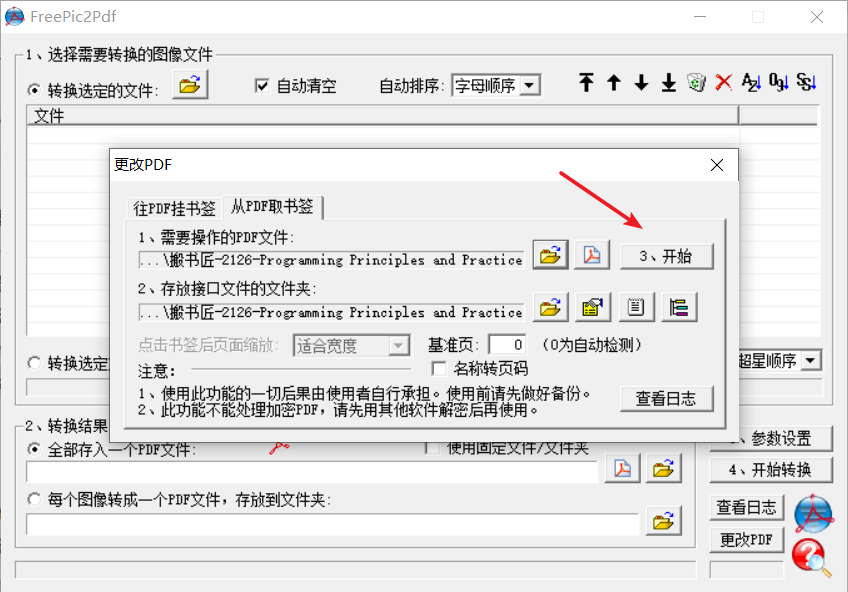
会在该PDF文件所在目录生成一个新的目录,包含如下文件:
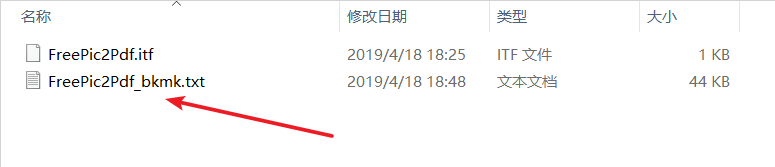
打开上面的txt文件,把之前生成的bb.txt中的内容贴进去,保存。然后再回到FreePic2Pdf软件:
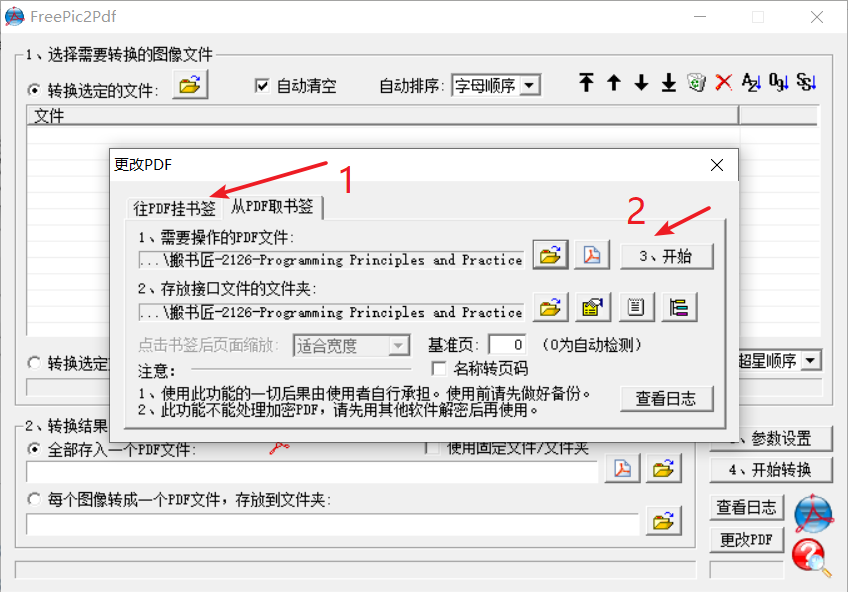
经过上面操作,就能成功添加标签了。

批量自动化生成PDF目录标签的更多相关文章
- doc文档生成带目录的pdf文件方法
准备软件: 福昕PDF阅读器 下载地址:http://rj.baidu.com/soft/detail/12882.html?ald 安装福昕PDF阅读器,会自动安装pdf打印机. 准备好设置好各级标 ...
- 生成有目录的pdf
生成有目录的pdf 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 https://jingyan.baidu.com/article/ff411625c2153512e48237a ...
- php利用mpdf生成pdf并保存到目录
下载mpdf7.0两种方法 (1). github地址:https://github.com/mpdf/mpdf (2). composer require mpdf/mpdf <?php er ...
- 谈FME批量自动化数据转换方法
FME作为转换神器,支持几百种格式的互转,实现互操作化.从fme.exe执行方式入手,讨论Command命令式执行模板(.fmw/.fmwt)和脚本(.tcl/.py)实现自动化批量转换. 1.fme ...
- 电子凭证 : Java 生成 Pdf
来源:蛙牛, my.oschina.net/lujianing/blog/894365 如有好文章投稿,请点击 → 这里了解详情 1.背景 在某些业务场景中,需要提供相关的电子凭证,比如网银/支付宝中 ...
- Itext生成pdf文件
来源:https://my.oschina.net/lujianing/blog/894365 1.背景 在某些业务场景中,需要提供相关的电子凭证,比如网银/支付宝中转账的电子回单,签约的电子合同等. ...
- Java iText+FreeMarker生成PDF(HTML转PDF)
1.背景 在某些业务场景中,需要提供相关的电子凭证,比如网银/支付宝中转账的电子回单,签约的电子合同等.方便用户查看,下载,打印.目前常用的解决方案是,把相关数据信息,生成对应的pdf文件返回给用户. ...
- 使用puppeteer生成pdf与截图
之前写过一篇 vue cli2 使用 wkhtmltopdf 踩坑指南,由于wkhtmltopdf对vue的支持并不友好,而且不支持css3,经过调研最终选择puppeteer,坑少,比较靠谱. 一. ...
- html 生成pdf
HTML生成PDF(c#) 最近因为工作需要,小小的研究了一下HTML生成PDF的方法,这方面的内容很多,但要么是不尽如人意的方法,要么就是那种收费的类库!为了广大.neter的福利,把自己的一点小小 ...
随机推荐
- Cw210开发板
达内培训嵌入式开发板 qt + kernel uboot toolchain
- mosquitto ---配置SSL/TLS linux
mosquitto ---配置SSL/TLS 摘自: https://www.cnblogs.com/saryli/p/9821343.html 在服务器电脑上面创建myCA文件夹, 如在/home/ ...
- (1)WePHP 开启WePHP
新建入口文件index.php,定义新项目的目录地址APP_PATH,引入WePHP项目入口文件 <?php define('APP_PATH','./index/'); require_onc ...
- 浅说Java反射机制
工作中遇到,问题解决: JAVA语言中的反射机制: 在Java 运行时 环境中,对于任意一个类,能否知道这个类有哪些属性和方法? 对于任意一个对象,能否调用他的方法?这些答案是肯定的,这种动态获取类的 ...
- select, iocp, epoll,kqueue及各种I/O复用机制
http://blog.csdn.net/heyan1853/article/details/6457362 首先,介绍几种常见的I/O模型及其区别,如下: blocking I/O nonblock ...
- VS中ashx文件关键字没有高亮标记的解决办法
VS --- 工具 --- 选项 --- 文本编辑器 --- 文件扩展名,只要在右侧添加 ashx ,选中MS-VS c# 保存后
- 每天多学一个Linux命令--man
今天学习的是“有问题,找男人”.man是manual(操作说明)的简写.它提供强大的帮助文档,当你需要查看某个命令的参数时不必到处上网查找,只要man一下即可. 第一列代表的是章节代号,第二列代表的是 ...
- Asp.net MVC 自定义路由
在做公司接口的时候 由于规范API 要用点分割. 如: HealthWay.controller.action 在MVC 4 下面做了个 路由配置如下: public override void R ...
- org.apache.catalina.util.DefaultAnnotationProcessor cannot be cast to org.ap解决方案
非常可能是因为tomcat的lib文件夹jar包和项目的lib文件下的jar包冲突了 把项目下lib文件下和tomcat的jar的重复的全部删除. 注意,如果你是先建flex工程然后转成web形式的, ...
- libz.dylib框架怎么导入
1.General下 2.点击+号在弹出的对话框选择addother 3.在弹出的对话框中输入"cmd"+"shift"+"g" 输入/us ...