Storm手写WordCount
建立一个maven项目,在pom.xml中进行如下配置:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.darrenchan</groupId>
<artifactId>StormDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>StormDemo</name> <dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.5</version>
<!--<scope>provided</scope> -->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.bigdata.hadoop.mapreduce.wordcount.WordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build> </project>
项目目录为:
MySpout.java:
package cn.darrenchan.storm; import java.util.Map; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values; public class MySpout extends BaseRichSpout { private SpoutOutputCollector collector; //storm框架不停地调用nextTuple方法
//values继承ArrayList
@Override
public void nextTuple() {
collector.emit(new Values("i am lilei love hanmeimei"));
} //初始化方法
@Override
public void open(Map config, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
} //声明本spout组件发送出去的tuple中的数据的字段名
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("love"));
} }
MySplitBolt.java:
package cn.darrenchan.storm; import java.util.Map; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; public class MySplitBolt extends BaseRichBolt { private OutputCollector collector; //storm框架不停地调用,传入参数是tutle
@Override
public void execute(Tuple input) {
String line = input.getString(0);
String[] words = line.split(" ");
for (String word : words) {
//Values有两个,对应下面Fields有两个
collector.emit(new Values(word, 1));
}
} //初始化方法
@Override
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//Fields有两个,对应上面Values有两个
declarer.declare(new Fields("word", "num"));
} }
MyCountBolt.java:
package cn.darrenchan.storm; import java.util.HashMap;
import java.util.Map; import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple; public class MyCountBolt extends BaseRichBolt { private OutputCollector collector;
private Map<String, Integer> map; @Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
map = new HashMap<String, Integer>();
} @Override
public void execute(Tuple input) {
String word = input.getString(0);
Integer num = input.getInteger(1);
if(map.containsKey(word)){
map.put(word, map.get(word) + num);
} else {
map.put(word, 1);
} System.out.println(map);
} @Override
public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
WordCountTopoloyMain.java:
package cn.darrenchan.storm; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields; public class WordCountTopoloyMain {
public static void main(String[] args) throws Exception {
//1.准备一个TopologyBuilder
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("mySpout", new MySpout(), 1);
builder.setBolt("mySplitBolt", new MySplitBolt(), 2).shuffleGrouping("mySpout");
builder.setBolt("myCountBolt", new MyCountBolt(), 2).fieldsGrouping("mySplitBolt", new Fields("word")); //2.创建一个configuration,用来指定当前的topology需要的worker的数量
Config config = new Config();
config.setNumWorkers(4); //3.任务提交 两种模式————本地模式和集群模式
//集群模式
//StormSubmitter.submitTopology("myWordCount", config, builder.createTopology());
//本地模式
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("myWordCount", config, builder.createTopology());
}
}
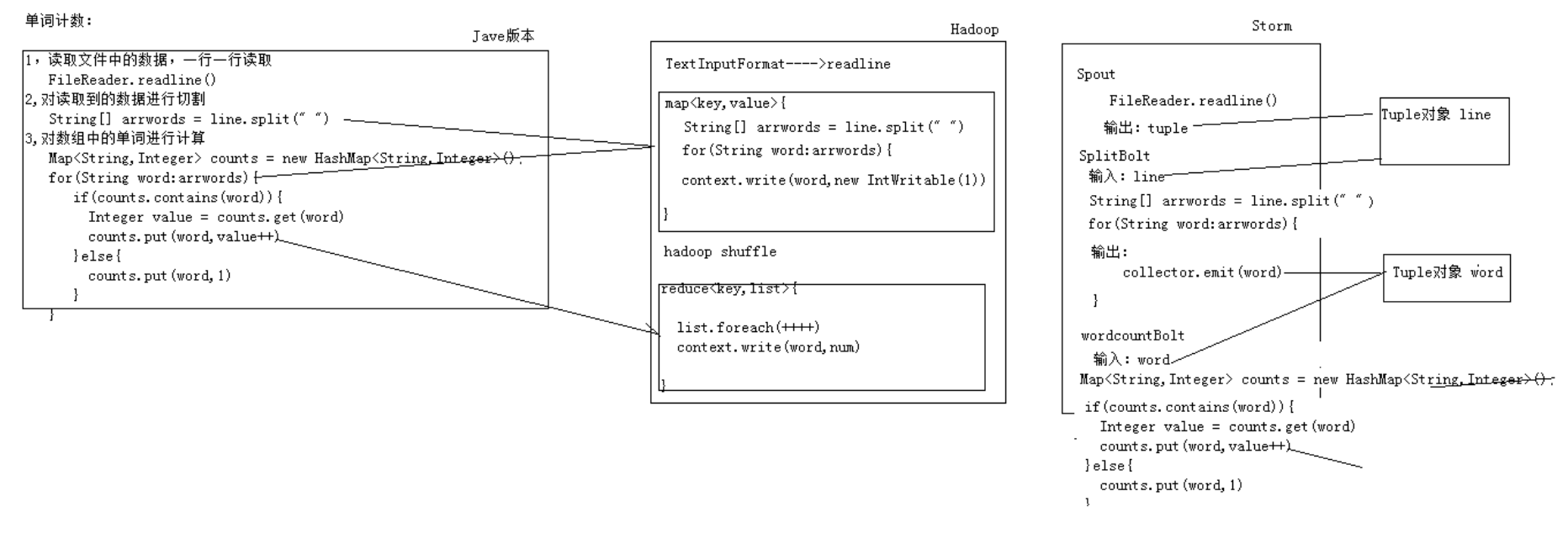
三种求wordcount方式 比较:
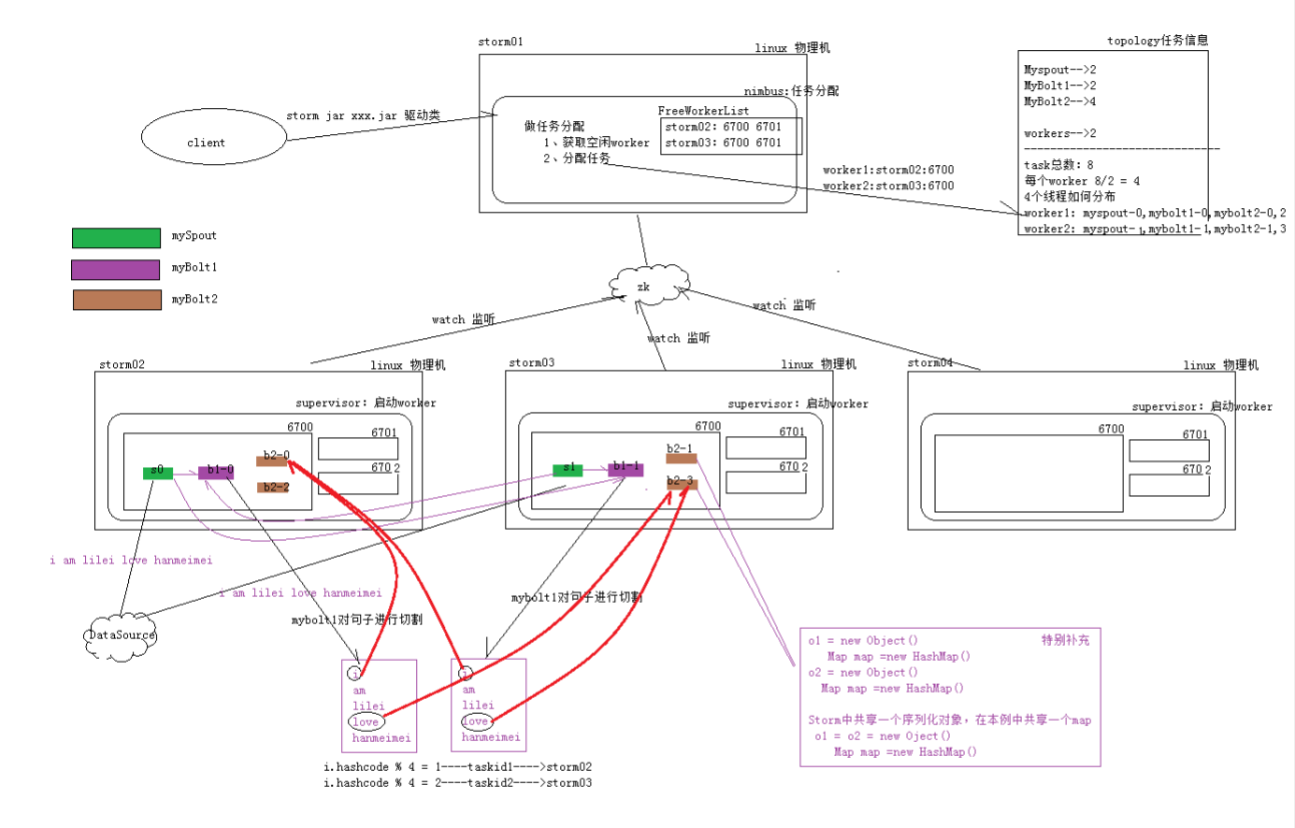
整体运行架构图:
Storm手写WordCount的更多相关文章
- 如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP, ...
- Hive手写SQL案例
1-请详细描述将一个有结构的文本文件student.txt导入到一个hive表中的步骤,及其关键字 假设student.txt 有以下几列:id,name,gender三列 1-创建数据库 creat ...
- 【Win 10 应用开发】手写识别
记得前面(忘了是哪天写的,反正是前些天,请用力点击这里观看)老周讲了一个14393新增的控件,可以很轻松地结合InkCanvas来完成涂鸦.其实,InkCanvas除了涂鸦外,另一个大用途是墨迹识别, ...
- JS / Egret 单笔手写识别、手势识别
UnistrokeRecognizer 单笔手写识别.手势识别 UnistrokeRecognizer : https://github.com/RichLiu1023/UnistrokeRecogn ...
- 【转】机器学习教程 十四-利用tensorflow做手写数字识别
模式识别领域应用机器学习的场景非常多,手写识别就是其中一种,最简单的数字识别是一个多类分类问题,我们借这个多类分类问题来介绍一下google最新开源的tensorflow框架,后面深度学习的内容都会基 ...
- caffe_手写数字识别Lenet模型理解
这两天看了Lenet的模型理解,很简单的手写数字CNN网络,90年代美国用它来识别钞票,准确率还是很高的,所以它也是一个很经典的模型.而且学习这个模型也有助于我们理解更大的网络比如Imagenet等等 ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- 手写原生ajax
关于手写原生ajax重要不重要,各位道友自己揣摩吧, 本着学习才能进步,分享大家共同受益,自己也在自己博客里写一下 function createXMLHTTPRequest() { //1.创建XM ...
- springmvc 动态代理 JDK实现与模拟JDK纯手写实现。
首先明白 动态代理和静态代理的区别: 静态代理:①持有被代理类的引用 ② 代理类一开始就被加载到内存中了(非常重要) 动态代理:JDK中的动态代理中的代理类是动态生成的.并且生成的动态代理类为$Pr ...
随机推荐
- 屏幕实时显示键盘鼠标操作软件keycastow,适合做视频教程
屏幕实时显示键盘鼠标操作软件keycastow,适合做视频教程 学习了:https://www.52pojie.cn/thread-535154-1-1.html 进行键盘按键的屏幕实时显示:
- RS报表自动适应屏幕分辨率大小
问题:同一个报表,由于用户电脑显示器大小,分辨率大小不同显示的不一样,看起来不完整或者很不协调 原因:设计报表大小属性的时候使用了固定值属性,比如限制为宽:1200px 那么在电脑屏幕小分辨率很小的情 ...
- Oracle PL/SQL语句基础学习笔记(上)
PL/SQL是ORACLE对标准数据库语言的扩展,ORACLE公司已经将PL/SQL整合到ORACLE server和其它工具中了,近几年中很多其它的开发者和DBA開始使用PL/SQL,本文将讲述PL ...
- Oracle spatial 空间修正函数(SDO_UTIL.RECTIFY_GEOMETRY)
Oracle spatial有个空间修正函数SDO_UTIL.RECTIFY_GEOMETRY,它可以修复以下可能:a.重复节点 b.自相交 c.坐标串朝向不正确. 该函数的构造函数格式: SDO_U ...
- mysql安装错误总结
1.若在启动mysql服务时出现如下错误,可查看错误日志找出错误原因. Error:Starting MySQL.The server quit without updating PID file ( ...
- MySQL截取字符串函数方法
函数: 1.从左开始截取字符串 left(str, length) 说明:left(被截取字段,截取长度) 例:select left(content,200) as abstract from my ...
- QtGui.QSlider
A QtGui.QSlider is a widget that has a simple handle. This handle can be pulled back and forth. This ...
- LoadRunner中运行场景时提示"You do not have a license for this Vuser type."
LoadRunner中运行场景时提示"You do not have a license for this Vuser type." 2012-06-15 17:09:07| 分 ...
- Centos 开启telnet-service服务
1. 查看linux版本信息: [loong@localhost ~]$ cat /etc/issue CentOS release 5.8 (Final) Kernel \r on an \m 2. ...
- Creating Physical Standby Using RMAN DUPLICATE...FROM ACTIVE DATABASE执行结果
> run { > allocate channel prmy1 type disk; > allocate channel prmy2 type disk; > alloca ...