【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析
目录
@
0. 论文链接
FCN(https://arxiv.org/abs/1411.4038)
1. 概述
语义分割(semantic segmentation)其实就是对每个像素点进行预测分类(dense prediction)。这也应该是第一个训练对像素进行预测并且采用了有监督预训练的端到端FCN网络,可以对任意尺寸的输入利用现有的网络对其进行密集预测(dense prediction)。学习和推理能在全图通过密集的前馈计算和反向传播一次执行(whole-image-ata-time)。网内上采样层能在像素级别预测和通过下采样池化学习。作者提出了一种利用了结合深、粗层的语义(semantic)信息和浅、细层的表征(appearance)信息的特征谱的跨层网络结构(skip architecture)。
2. Adapting classifiers for dense prediction
因为之前的分类网络通常只能固定输入图片尺寸,然后输出概率,并没有空间信息。但是全连接层同样用卷积层进行表示,具体就是在用与输入分类网络FC层尺度大小相同卷积核从而获得与FC层相同维度的输出(比较经典也比较简单,不细举例了),换成全卷积层就可以接受任意尺度的输入并且输出一个分类图(classification map),具体可以看下图:
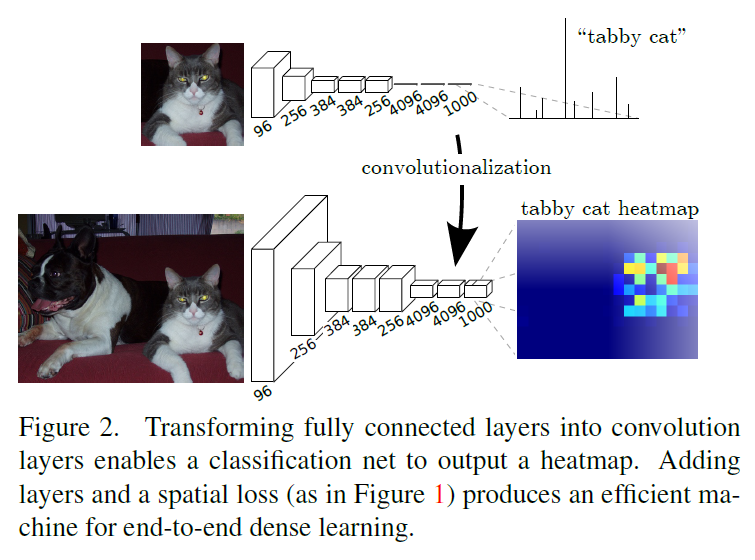
值得注意的是全卷积层最后输出的classification map相当于原来网络在某些特定patch上进行预测(可以想象成一个滑动窗口),但是很多计算都在这些patch的overlap上,浪费很多计算资源与时间,而全卷积层的效率是很高的。
3. upsampling
之前的对分类网络的改动,还是有一个问题的,比如output map相比原图维度是减少了很多的,因为在网络过程中通常会做一些 subsample来让卷积核变得更小,让计算量相对合理,所以我们需要通过一些手段使coarse output维度增加获得dense prediction的分割输出,文章中说了一句 感受野的步长等于输入尺寸与输出尺寸的系数比。接下来文章中介绍了三种upsample的方法。
3.1 Shift-and-stitch
这里首先推荐这位中科大学长的一篇博客,讲解的很不错,我也加了他的微信,为人也很好呢~在这我就简述一下Shift-and-stitch。
Shift-and-stitch是从coarse outputs到dense predictions的一种trick,文章在《Overfeat: Integrated recognition, localization and detection using convolutional networks》中被提到。他的方法为(直接看英文原版更清晰一些):

这里注意,通常需要在输入加相应的padding,来让他进行“shift”,引用上面中科大学长的文章内容:

为表述简洁,用 “ 像素 i ” 表示“ 值为 i 的像素 ”
红色 output中的像素1对应shifted input(0,0) 的红色部分, 而对应 original image 的部分,也即receptive field仅仅为像素[1], 所以 receptive field 的中心为像素[1], 该位置填上红色output中像素 1 的值。
- 黄色 output 中的像素4 对应 shifted input (1,0)的黄色部分, 而对应 original image 的部分,也即receptive field为像素 [3,4] , 所以 receptive field 的中心为像素 [4], 该位置填上黄色output中像素 4 的值。
以此类推..注意: 我们注意到黄色 output 中的像素 5 与红色 output 中的像素5对应的receptive field 中心是重叠的,所以将黄色 output 中的像素 5 标为灰色,表示不予考虑。同理其他ouput 中的灰色区域也代表 receptive field中心重叠的像素。
这里需要说明一下的是, 感受野的中心可以简单的理解成:给定一个矩形,求他的中心, 小数需要向上/下取整,所以上图2x2的感受野,在其实四个值都可以作为“中心”, 在论文《RECURRENT CONVOLUTIONAL NEURAL NETWORKS FOR SCENE PARSING》中,他举得例子是没有上图中“灰色块”的,如果按照灰色块里的数值计算,会发现他对“感受野中心”定义是不同的,有的是左下有的是右下,而在论文中,他则是忽略了灰色块, 我的理解是论文里是按照右下的规则,在灰色地方,感受野的中心成了padding的0,不是原图的像素,因此需要去掉,因此这样恰好可以拼成原图大小,不会多像素也不会少像素,如下图。

(关于中科大学长的观点目前还不知道他从哪得到的,也没看FCN中的源码,以后补充)
3.2 decreasing subsampling
上述采用的shift-and-stitch方案,需要反复计算 \(f*f\) 个输入,造成计算效率的降低。而 decreasing subsampling 方法提供了另外的一种思路,减小传统网络中降采样操作,从而实现 coarse output 的 dense prediction。
考虑其中某一层具有stride = s,后面卷积层具有卷积核权重 fij。现在我们设置原本stride = 1避免降采样的出现,形成上采样结果。然而直接对这样的上采样结果进行按照原本卷积核操作并不能得到相等于 shift-and-stitch的结果。因为这样的卷积核仅仅能看到上采样结果的一小部分,所以我们扩大原本的卷积核:
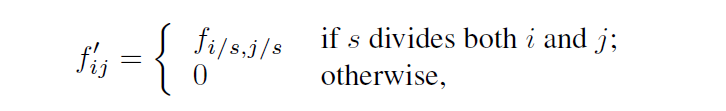
值得注意的是,这样的操作方式会造成一种 trade-off:卷积核如果需要看到更精细的信息,往往需要较小的感受野且需要更多的操作。这样的一种方式,使得感受野固定成一种较大的 input size,不能完成精细的定位分割信息。
3.3 Deconvolution(backwards strided convolution)
所谓的Deconvolution在操作上其实就是简单的把卷积forward与backward交换过来,因此上采样可以通过计算所有像素(pixel-wise)的loss反向传播达到in-network for end-to-end learning。值得注意的是,反卷积核并不是固定的,而是可以学习的,一些堆叠的反卷积层跟激活函数可以学一个非线性上采样(upsampling),作者采用了Deconvolution + skip的网络结构。
4. Segmentation Architecture
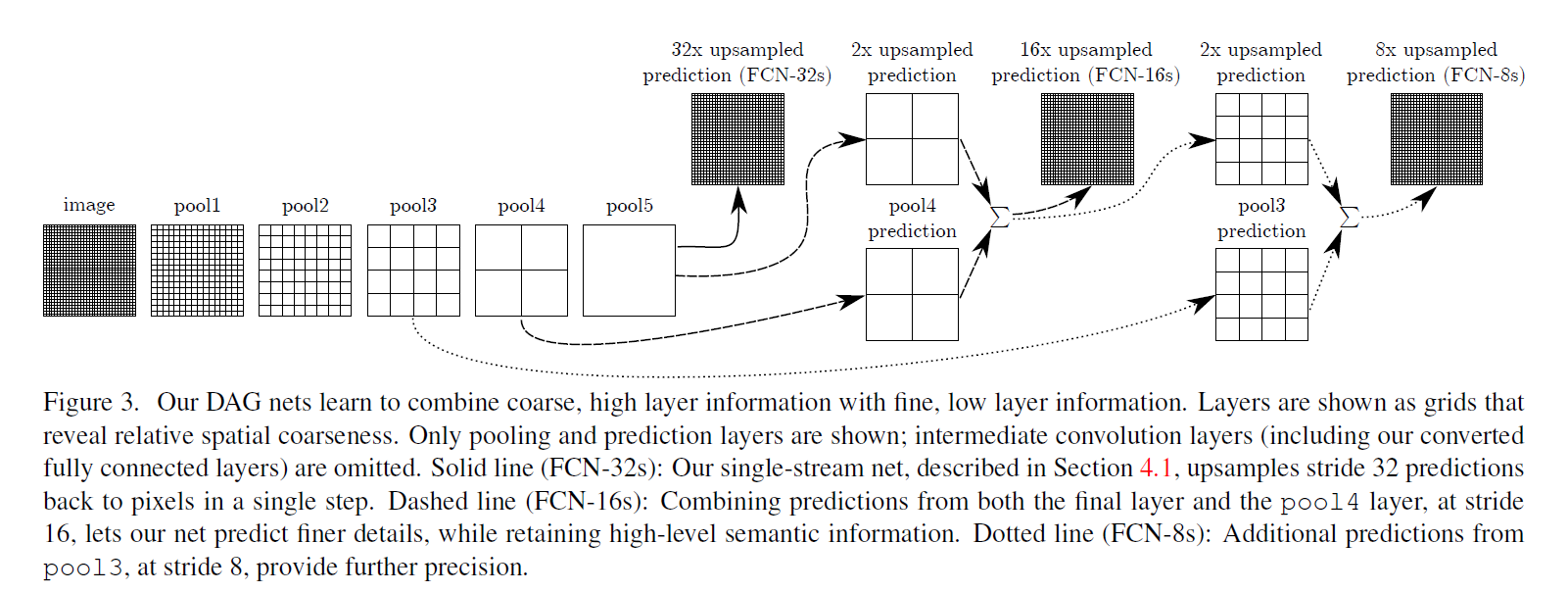
作者训练了一个per-pixel multinomial logistic loss,用VGG16跟GooLeNet做backbone,其中GoogLeNet只用最后的loss layer 并且把最后的average pooling layer去掉。作者把每个网络去掉最后的分类层,把全连接层变成全卷积层,另外,在每个coarse output locations加了一个21维通道的1x1卷积,然后接着一层deconv层来把coarse output 转换成 pixel-dense outputs。从classification 到 segmentation 的Fine-tuning很重要,通过BP来fine-tuning整个网络,如果只fine-tuning分类器只有70%的性能,作者提出一个skip architecture来结合finer与coarse的特征,如下图:
每个网络的效果图跟结果:

转自:https://www.jianshu.com/p/0beea071b9b1
网络框架如下:
整体的网络框架基于正常的CNN,将最后的全连接网络改为了卷积。
这样做的效果是:
1)网络得以接受任意维度的输入,不需要变成224x224了;
2)最后本该是1000x1x1维的特征变成了1000xWxH维,这个w和h就是热点图的尺寸。关于这个热点图,应该是有1000张热点图,可以看出整张图片的不同区域都激活了哪种分类的输出。在上述结构的基础上,将1000维变成21维(20种分类+背景类),再接一个反卷积层。
这样做的效果就是:
1)输出了21张热点图,然后通过反卷积网络变成了21张大小等于原图的Mask;
2)21张Mask出来之后就可以和真实数据做逐像素的损失函数了,进行训练。
这样做还有一些缺点:
1)先得到的热点图的尺寸和最后一层卷积的特征图尺寸是相当的,在作者采用的VGG16中,尺寸为原图的1/32,这就让一层反卷积网络实现32倍的放大,结果可想而知是粗糙(coarse)的。作者后来采用了skip的方法做了精细化,但或许直接采用多层的反卷积就可以有不错的效果。
2)这一段写的过程中被删掉了,因为写着写着发现了问题,我把删掉的放到后面,可以作为思路记录。训练的时候每个点的预测值就是一个21维的向量,做交叉熵损失函数。最后预测结果采用max算法。嗯这是一个提醒自己训练和测试不同的好例子。
其实21张Mask出来之后他有采用一个最大值算法,使得最后输出的MAsk就一张,包括了每个点最可能的预测。这种方式有个缺陷就是它相当于把每个点的非极大预测值变成了0。之后loss具体是交叉熵还是单纯的3-2(这个不太可能)不太清楚,就以交叉熵来说,他的损失函数就是不合理的,因为可能本身该点像素预测第二名就是对的,但这下又要推倒重来。接下来是Skip结构,是将pool3和pool4层的特征引到输出。
具体来说,pool3和pool4层特征图的大小是pool5层的4、2倍,所以最后的热点图要先反卷积扩大为2倍、4倍再相加,然后再反卷积扩大为16倍、8倍。得到原图尺寸。
这样做是为了让Mask更加精细,之前说过这个方法或许可以被替代。
接下来是训练过程:
其实上面说的比较清楚了,就是利用FCN得到图像的热点图,然后通过反卷积的方式得到与原图像尺寸相同的Mask,每个像素均包含21类的预测值,然后利用这个进行训练。测试方式是取21预测值的最大为结果。
但是还有一些细节需要说明:
- 作者采用了VGG网络,默认大小是224x224,在pool5层后输出尺寸变为1/32,为7x7,之后进行7x7的卷积,可以得出,最后热点图的大小并不是原图尺寸/32,而是\(h_1 = (h-192)/32\)。这就有2个问题:
1)图像尺寸不能小于224,否则输出不足1.
2)skip结构中,fc7与pool4层之间不是2倍关系。
对于这一问题的解决方式是:
1)图像在输入过程中被pad了100,最终尺寸变为\(h_1 = (h+6)/32\),从而可以接受任意尺寸图像。
2)对fc7反卷积x2后进行crop裁剪。(因为他多了6)
5. Metric
转自:https://blog.csdn.net/mieleizhi0522/article/details/81914000


【Semantic segmentation】Fully Convolutional Networks for Semantic Segmentation 论文解析的更多相关文章
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 论文笔记(4):Fully Convolutional Networks for Semantic Segmentation
一.FCN中的CNN 首先回顾CNN测试图片类别的过程,如下图: 主要由卷积,pool与全连接构成,这里把卷积与pool都看作图中绿色的convolution,全连接为图中蓝色的fully conne ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 【网络结构可视化】Visualizing and Understanding Convolutional Networks(ZF-Net) 论文解析
目录 0. 论文地址 1. 概述 2. 可视化结构 2.1 Unpooling 2.2 Rectification: 2.3 Filtering: 3. Feature Visualization 4 ...
- 中文版 R-FCN: Object Detection via Region-based Fully Convolutional Networks
R-FCN: Object Detection via Region-based Fully Convolutional Networks 摘要 我们提出了基于区域的全卷积网络,以实现准确和高效的目标 ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
随机推荐
- cpuspeed和irqbalance服务器的两大性能杀手
启用 irqbalance 服务,既可以提升性能,又可以降低能耗. irqbalance 用于优化中断分配,它会自动收集系统数据以分析使用模式,并依据系统负载状况将工作状态置于 Performance ...
- 基于HTTP协议的轻量级开源简单队列服务:HTTPSQS 笔记
队列服务就是为了提高相应速度,把耗时或者不需要即时处理的流程放到异步处理过程中,HTTPSQS就是这样一个服务. 更详细的可以参考 http://blog.s135.com/httpsqs/,这里记录 ...
- 前端开发 - JavaScript - 上
1.js引入 <!DOCTYPE html> <html lang="cn"> <head> <meta charset="UT ...
- mysql表的完整性约束
概览 为了防止不符合规范的数据进入数据库,在用户对数据进行插入.修改.删除等操作时,DBMS自动按照一定的约束条件对数据进行监测, 使不符合规范的数据不能进入数据库,以确保数据库中存储的数据正确.有效 ...
- Navicat工具、pymysql模块、数据备份
IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navicat工具,这个工具本质上就是一个socket客户端,可视化的连接mys ...
- 前端 javascript 数据类型 字符串
字符串是由字符组成的数组,但在JavaScript中字符串是不可变的:可以访问字符串任意位置的文本,但是JavaScript并未提供修改已知字符串内容的方法. obj.charAt(n) 返回字符串中 ...
- 缓存系统MemCached的Java客户端优化历程
Memcached 是什么? Memcached是一种集中式Cache,支持分布式横向扩展.这里需要解释说明一下,很多开发者觉得Memcached是一种分布式缓存系统,但是其实Memcached服务端 ...
- Spark日志级别修改
摘要 在学习使用Spark的过程中,总是想对内部运行过程作深入的了解,其中DEBUG和TRACE级别的日志可以为我们提供详细和有用的信息,那么如何进行合理设置呢,不复杂但也绝不是将一个INFO换为TR ...
- hadoop-3.0.0-beta1分布式安装
楼主是从Hadoop2.x版本过来的,在工作之余自己搭建了一套3.0的版本来耍一耍,此文章的前置环境准备工作省略.主要介绍一些和Hadoop2.x版本不同的安装之处 Hadoop版本:hadoop-3 ...
- PAT 1151 LCA in a Binary Tree[难][二叉树]
1151 LCA in a Binary Tree (30 分) The lowest common ancestor (LCA) of two nodes U and V in a tree is ...