Numerical Optimization: Understanding L-BFGS
http://aria42.com/blog/2014/12/understanding-lbfgs/
Numerical optimization is at the core of much of machine learning. Once you’ve defined your model and have a dataset ready, estimating the parameters of your model typically boils down to minimizing some multivariate function
f(x), where the input x is in some high-dimensional space and corresponds to model parameters. In other words, if you solve:
then x∗ is the ‘best’ choice for model parameters according to how you’ve set your objective.1
In this post, I’ll focus on the motivation for the L-BFGS algorithm for unconstrained function minimization, which is very popular for ML problems where ‘batch’ optimization makes sense. For larger problems, online methods based around stochastic gradient descent have gained popularity, since they require fewer passes over data to converge. In a later post, I might cover some of these techniques, including my personal favorite AdaDelta.
Note: Throughout the post, I’ll assume you remember multivariable calculus. So if you don’t recall what a gradient or Hessian is, you’ll want to bone up first.
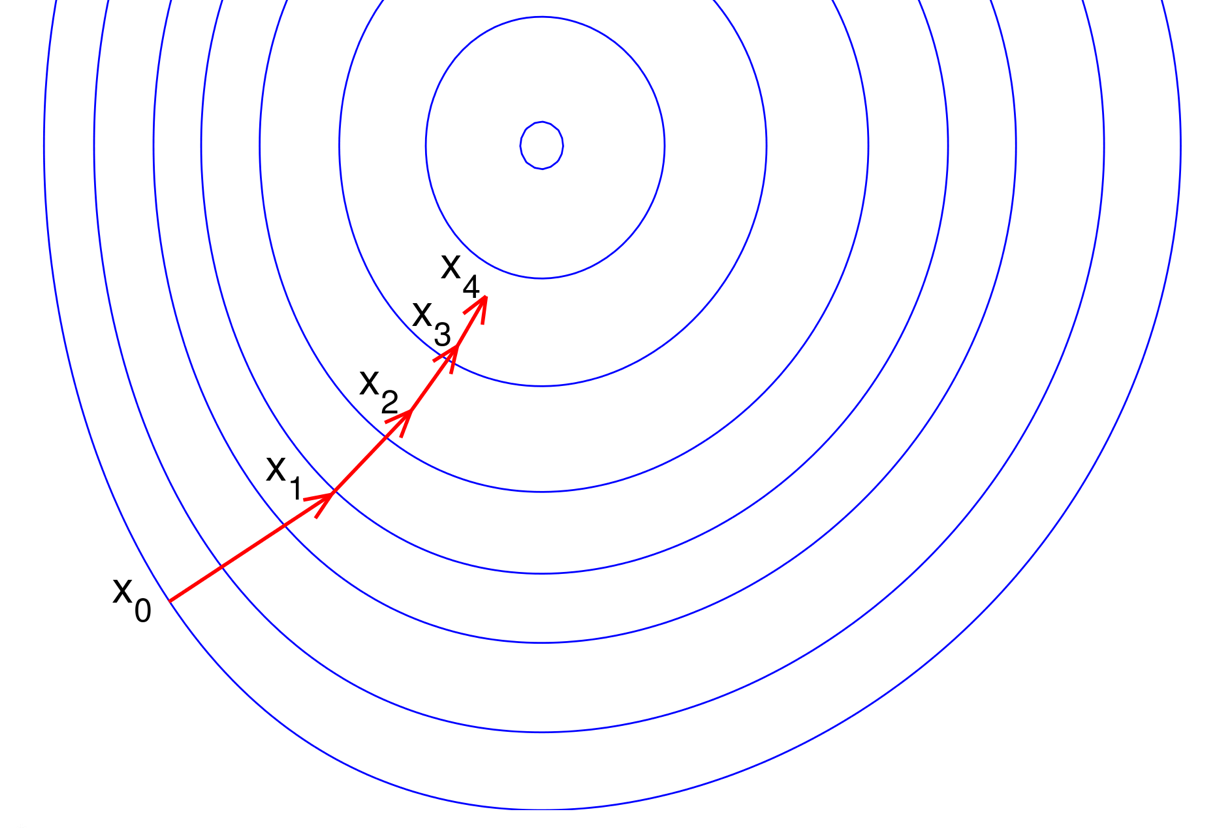
Newton’s Method
Most numerical optimization procedures are iterative algorithms which consider a sequence of ‘guesses’ xn which ultimately converge to x∗ the true global minimizer of f. Suppose, we have an estimate xn and we want our next estimate xn+1 to have the property that f(xn+1)<f(xn).
Newton’s method is centered around a quadratic approximation of f for points near xn. Assuming that f is twice-differentiable, we can use a quadratic approximation of f for points ‘near’ a fixed pointx using a Taylor expansion:
where ∇f(x) and ∇2f(x) are the gradient and Hessian of f at the point xn. This approximation holds in the limit as ||Δx||→0. This is a generalization of the single-dimensional Taylor polynomial expansion you might remember from Calculus.
In order to simplify much of the notation, we’re going to think of our iterative algorithm of producing a sequence of such quadratic approximations hn. Without loss of generality, we can write xn+1=xn+Δx and re-write the above equation,
where gn and Hn represent the gradient and Hessian of f at xn.
We want to choose Δx to minimize this local quadratic approximation of f at xn. Differentiating with respect to Δx above yields:
Recall that any Δx which yields ∂hn(Δx)∂Δx=0 is a local extrema of hn(⋅). If we assume that Hn ispostive semi-definite (psd) then we know this Δx is also a global minimum for hn(⋅). Solving for Δx:2
This suggests H−1ngn as a good direction to move xn towards. In practice, we set xn+1=xn−α(H−1ngn) for a value of α where f(xn+1) is ‘sufficiently’ smaller than f(xn).
Iterative Algorithm
The above suggests an iterative algorithm:
The computation of the α step-size can use any number of line search algorithms. The simplest of these is backtracking line search, where you simply try smaller and smaller values of α until the function value is ‘small enough’.
In terms of software engineering, we can treat NewtonRaphson as a blackbox for any twice-differentiable function which satisfies the Java interface:
public interface TwiceDifferentiableFunction {
// compute f(x)
public double valueAt(double[] x);
// compute grad f(x)
public double[] gradientAt(double[] x);
// compute inverse hessian H^-1
public double[][] inverseHessian(double[] x);
}With quite a bit of tedious math, you can prove that for a convex function, the above procedure will converge to a unique global minimizer x∗, regardless of the choice of x0. For non-convex functions that arise in ML (almost all latent variable models or deep nets), the procedure still works but is only guranteed to converge to a local minimum. In practice, for non-convex optimization, users need to pay more attention to initialization and other algorithm details.
Huge Hessians
The central issue with NewtonRaphson is that we need to be able to compute the inverse Hessian matrix.3 Note that for ML applications, the dimensionality of the input to f typically corresponds to model parameters. It’s not unusual to have hundreds of millions of parameters or in some vision applications even billions of parameters. For these reasons, computing the hessian or its inverse is often impractical. For many functions, the hessian may not even be analytically computable, let along representable.
Because of these reasons, NewtonRaphson is rarely used in practice to optimize functions corresponding to large problems. Luckily, the above algorithm can still work even if H−1n doesn’t correspond to the exact inverse hessian at xn, but is instead a good approximation.
Quasi-Newton
Suppose that instead of requiring H−1n be the inverse hessian at xn, we think of it as an approximation of this information. We can generalize NewtonRaphson to take a QuasiUpdate policy which is responsible for producing a sequence of H−1n.
We’ve assumed that QuasiUpdate only requires the former inverse hessian estimate as well tas the input and gradient differences (sn and yn respectively). Note that if QuasiUpdate just returns∇2f(xn+1), we recover exact NewtonRaphson.
In terms of software, we can blackbox optimize an arbitrary differentiable function (with no need to be able to compute a second derivative) using QuasiNewton assuming we get a quasi-newton approximation update policy. In Java this might look like this,
public interface DifferentiableFunction {
// compute f(x)
public double valueAt(double[] x);
// compute grad f(x)
public double[] gradientAt(double[] x);
}
public interface QuasiNewtonApproximation {
// update the H^{-1} estimate (using x_{n+1}-x_n and grad_{n+1}-grad_n)
public void update(double[] deltaX, double[] deltaGrad);
// H^{-1} (direction) using the current H^{-1} estimate
public double[] inverseHessianMultiply(double[] direction);
}Note that the only use we have of the hessian is via it’s product with the gradient direction. This will become useful for the L-BFGS algorithm described below, since we don’t need to represent the Hessian approximation in memory. If you want to see these abstractions in action, here’s a link to aJava 8 and golang implementation I’ve written.
Behave like a Hessian
What form should QuasiUpdate take? Well, if we have QuasiUpdate always return the identity matrix (ignoring its inputs), then this corresponds to simple gradient descent, since the search direction is always ∇fn. While this actually yields a valid procedure which will converge to x∗ for convex f, intuitively this choice of QuasiUpdate isn’t attempting to capture second-order information about f.
Let’s think about our choice of Hn as an approximation for f near xn:
Secant Condition
A good property for hn(d) is that its gradient agrees with f at xn and xn−1. In other words, we’d like to ensure:
Using both of the equations above:
Using the gradient of hn+1(⋅) and canceling terms we get
This yields the so-called “secant conditions” which ensures that Hn+1 behaves like the Hessian at least for the diference (xn−xn−1). Assuming Hn is invertible (which is true if it is psd), then multiplying both sides by H−1n yields
where yn+1 is the difference in gradients and sn+1 is the difference in inputs.
Symmetric
Recall that the a hessian represents the matrix of 2nd order partial derivatives: H(i,j)=∂f/∂xi∂xj. The hessian is symmetric since the order of differentiation doesn’t matter.
The BFGS Update
Intuitively, we want Hn to satisfy the two conditions above:
- Secant condition holds for sn and yn
- Hn is symmetric
Given the two conditions above, we’d like to take the most conservative change relative to Hn−1. This is reminiscent of the MIRA update, where we have conditions on any good solution but all other things equal, want the ‘smallest’ change.
The norm used here ∥⋅∥ is the weighted frobenius norm.4 The solution to this optimization problem is given by
where ρn=(yTnsn)−1. Proving this is relatively involved and mostly symbol crunching. I don’t know of any intuitive way to derive this unfortunately.

This update is known as the Broyden–Fletcher–Goldfarb–Shanno (BFGS) update, named after the original authors. Some things worth noting about this update:
H−1n+1 is positive semi-definite (psd) when H−1n is. Assuming our initial guess of H0 is psd, it follows by induction each inverse Hessian estimate is as well. Since we can choose any H−10we want, including the I matrix, this is easy to ensure.
The above also specifies a recurrence relationship between H−1n+1 and H−1n. We only need the history of sn and yn to re-construct H−1n.
The last point is significant since it will yield a procedural algorithm for computing H−1nd, for a direction d, without ever forming the H−1n matrix. Repeatedly applying the recurrence above we have
Since the only use for H−1n is via the product H−1ngn, we only need the above procedure to use the BFGS approximation in QuasiNewton.
L-BFGS: BFGS on a memory budget
The BFGS quasi-newton approximation has the benefit of not requiring us to be able to analytically compute the Hessian of a function. However, we still must maintain a history of the sn and ynvectors for each iteration. Since one of the core-concerns of the NewtonRaphson algorithm were the memory requirements associated with maintaining an Hessian, the BFGS Quasi-Newton algorithm doesn’t address that since our memory use can grow without bound.
The L-BFGS algorithm, named for limited BFGS, simply truncates the BFGSMultiply update to use the last m input differences and gradient differences. This means, we only need to store sn,sn−1,…,sn−m−1 and yn,yn−1,…,yn−m−1 to compute the update. The center product can still use any symmetric psd matrix H−10, which can also depend on any {sk} or {yk}.
L-BFGS variants
There are lots of variants of L-BFGS which get used in practice. For non-differentiable functions, there is an othant-wise varient which is suitable for training L1 regularized loss.
One of the main reasons to not use L-BFGS is in very large data-settings where an online approach can converge faster. There are in fact online variants of L-BFGS, but to my knowledge, none have consistently out-performed SGD variants (including AdaGrad or AdaDelta) for sufficiently large data sets.
This assumes there is a unique global minimizer for f. In practice, in practice unless f is convex, the parameters used are whatever pops out the other side of an iterative algorithm. ↩
We know −H−1∇f is a local extrema since the gradient is zero, since the Hessian has positive curvature, we know it’s in fact a local minima. If f is convex, we know the Hessian is always positive semi-definite and we know there is a single unique global minimum. ↩
As we’ll see, we really on require being able to multiply by H−1d for a direction d. ↩
I’ve intentionally left the weighting matrix W used to weight the norm since you get the same solution under many choices. In particular for any positive-definite W such that Wsn=yn, we get the same solution. ↩
Numerical Optimization: Understanding L-BFGS的更多相关文章
- 数值优化(Numerical Optimization)学习系列-无梯度优化(Derivative-Free Optimization)
数值优化(Numerical Optimization)学习系列-无梯度优化(Derivative-Free Optimization) 2015年12月27日 18:51:19 下一步 阅读数 43 ...
- 数值优化(Numerical Optimization)学习系列-文件夹
概述 数值优化对于最优化问题提供了一种迭代算法思路,通过迭代逐渐接近最优解,分别对无约束最优化问题和带约束最优化问题进行求解. 该系列教程能够參考的资料有 1. <Numerical Optim ...
- 数值优化(Numerical Optimization)学习系列-目录
数值优化(Numerical Optimization)学习系列-目录 置顶 2015年12月27日 19:07:11 下一步 阅读数 12291更多 分类专栏: 数值优化 版权声明:本文为博主原 ...
- [转] 数值优化(Numerical Optimization)学习系列-目录
from:https://blog.csdn.net/fangqingan_java/article/details/48951191 概述数值优化对于最优化问题提供了一种迭代算法思路,通过迭代逐渐接 ...
- 支持向量机:Numerical Optimization,SMO算法
http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html 另外一篇:http://www.cnblogs.com/vivouni ...
- paper 8:支持向量机系列五:Numerical Optimization —— 简要介绍求解求解 SVM 的数值优化算法。
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
- BFGS方法
今天看了 Nocedal 写的Numerical Optimization 中关于BFGS方法的介绍. BFGS方法有个近亲,叫做DFP方法.下面先介绍DFP方法. 这个方法的意图是找一种方法对Hes ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- 让apache后端显示真实客户端IP
公司是nginx做代理,后端的web服务用的是apache,然后我现在要分析日志,但是,我的apache日志上显示的是代理服务器的ip地址,不是客户的真实IP 所以这里我需要修改一下,让apache的 ...
- Android怎么使用字体图标 自定义FontTextView字体图标控件-- 使用方法
首先我想说明一下字体图标的好处,最大的好处就是自适应了,而且是使用TextView 不用去切图,是矢量图 灵活调用 第一步我要说明一下一般字体图标的来源,我这里使用的是 --阿里巴巴矢量图标库 -网 ...
- safe RGB colors
RGB是面向机器的一种颜色空间. 虽然它表示\(256 \times 256 \times 256\)种不同的颜色, 但在实际中, 大部分机器都只实现了256种颜色. 安全色(Safe RGB col ...
- Kernel Methods (1) 从简单的例子开始
一个简单的分类问题, 如图左半部分所示. 很明显, 我们需要一个决策边界为椭圆形的非线性分类器. 我们可以利用原来的特征构造新的特征: \((x_1, x_2) \to (x_1^2, \sqrt 2 ...
- 基于Oracle的Mybatis 批量插入
项目中会遇到这样的情况,一次性要插入多条数据到数据库中,有两种插入方法: 方法一: Mybatis本身只支持逐条插入,比较笨的方法,就是遍历一个List,循环中逐条插入,比如下面这段代码 for(Da ...
- Fiddler环境配置教程
原理:安装Fiddler的电脑和将要进行检测的手机(iPhone.Android)加入同一局域网,这样手机上APP的请求就可以被电脑通过Fiddler抓取到. 局域网布置教程: 在将要布置局域网的电脑 ...
- 【HDU 4311】Meeting point-1(前缀和求曼哈顿距离和)
题目链接 正经解法: 给定n个点的坐标,找一个点,到其他点的曼哈顿距离之和最小.n可以是100000.大概要一个O(nlogn)的算法.算曼哈顿距离可以把x和y分开计算排好序后计算前缀和就可以在O(1 ...
- iOS推送后页面跳转
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launc ...
- matplotlib 柱状图、饼图;直方图、盒图
#-*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl m ...
- Eclipse中Jquery报错
在网上看到很多 jQuery-xxx.js 在eclipse中报错的解决方案大多是说 项目右键 Properties->Validation->JSP Content Validator ...