Elasticsearch: Indexing SQL databases. The easy way
Elasticsearchis a great search engine, flexible, fast and fun. So how can I get started with it? This post will go through how to get contents from a SQL database into Elasticsearch.
Elasticsearch has a set of pluggable services called rivers. A river runs inside an Elasticsearch node, and imports content into the index. There are rivers for twitter, redis, files, and of course, SQL databases. The river-jdbc plugin connects to SQL databases using JDBC adapters. In this post we will use PostgreSQL, since it is freely available, and populate it with some contents that also are freely available.
So let’s get started
- Download and install Elasticsearch
- Start elasticsearch by running bin/elasticsearch from the installation folder
- Install the river-jdbc plugin for Elasticsearch version 1.00RC
1./bin/plugin -install river-jdbc -url <em><a href="http://bit.ly/1dKqNJy">http://bit.ly/1dKqNJy</a> </em>
- Download the PostgreSQL JDBC jar file and copy into the plugins/river-jdbc folder. You should probably get the latest version which is for JDBC 41
- Install PostgreSQL http://www.postgresql.org/download/
- Import the booktown database. Download the sql file from booktown database
- Restart Elasticsearch
- Start PostgreSQL
By this time you should have Elasticsearch and PostgreSQL running, and river-jdbc ready to use.
Now we need to put some contents into the database, using psql, the PostgreSQL command line tool.
|
1
|
psql -U postgres -f booktown.sql
|
To execute commands to Elasticsearch we will use an online service which functions as a mixture of Gist, the code snippet sharing service and Sense, a Google Chrome plugin developer console for Elasticsearch. The service is hosted by http://qbox.io, who provide hosted Elasticsearch services.
Check that everything was correctly installed by opening a browser tohttp://sense.qbox.io/gist/8361346733fceefd7f364f0ae1ebe7efa856779e
Select the top most line in the left-hand pane, press CTRL+Enter on your keyboard. You may also click on the little triangle that appears to the right, if you are more of a mouse click kind of person.
You should now see a status message, showing the version of Elasticsearch, node name and such.
Now let’s stop fiddling around the porridge and create a river for our database:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
curl -XPUT "http://localhost:9200/_river/mybooks/_meta" -d'
{
"type": "jdbc",
"jdbc": {
"driver": "org.postgresql.Driver",
"url": "jdbc:postgresql://localhost:5432/booktown",
"user": "postgres",
"password": "postgres",
"index": "booktown",
"type": "books",
"sql": "select * from authors"
}
}'
|
This will create a “one-shot” river that connects to PostgreSQL on Elasticsearch startup, and pulls the contents from the authors table into the booktown index. The index parameter controls what index the data will be put into, and the type parameter decides the type in the Elasticsearch index. To verify the river was correctly uploaded execute
|
1
|
GET /_river/mybooks/_meta
|
Restart Elasticsearch, and watch the log for status messages from river-jdbc. Connection problems, SQL errors or other problems should appear in the log . If everything went OK, you should see something like …SimpleRiverMouth] bulk [1] success [19 items]
Time has come to check out what we got.
|
1
|
GET /booktown/_search
|
You should now see all the contents from the authors table. The number of items reported under “hits” -> “total” are the same as what we just saw in the log: 19.
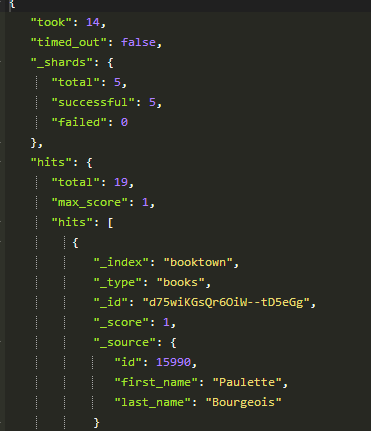
But looking more closely at the data, we can see that the _id field has been auto-assigned with some random values. This means that the next time we run the river, all the contents will be re-added.
Luckily, river-jdbc support somespecially labeled fields, that let us control how the contents should be indexed.
Reading up on the docs, we change the SQL definition in our river to
|
1
2
|
select id as _id, first_name,
last_name from authors
|
We need to start afresh and scrap the index we just created:
|
1
|
DELETE /booktown
|
Restart Elasticsearch. Now you should see a meaningful id in your data.
At this time we could start toying around with queries, mappings and analyzers. But, that’s not much fun with this little content. We need to join in some tables and get some more interesting data. We can join in the books table, and get all the books for all authors.
|
1
2
3
|
SELECT authors.id as _id, authors.last_name, authors.first_name,
books.id, books.title, books.subject_id
FROM public.authors left join public.books on books.author_id = authors.id
|
Delete the index, restart Elasticsearch and examine the data. Now you see that we only get one book per author. Executing the SQL statement in pgadmin returns 22 rows, while in Elasticsearch we get 19. This is on account of the _id field, on each attempt to index an existing record with the same _id as a new one, it will be overwritten.
River-jdbc supports Structured objects, which allows us to create arbitrarily structured JSON documents simply by using SQL aliases. The _id column is used for identity, structured objects will be appended to existing data. This is perhaps best shown by an example:
|
1
2
3
4
|
SELECT authors.id as _id, authors.last_name, authors.first_name,
books.id as \"Books.id\", books.title as \"Books.title\",
books.subject_id as \"Books.subject_id\"
FROM public.authors left join public.books on books.author_id = authors.id order by authors.id
|
Again, delete the index, restart Elasticsearch, wait a few seconds before you search, and you will find structured data in the search results.
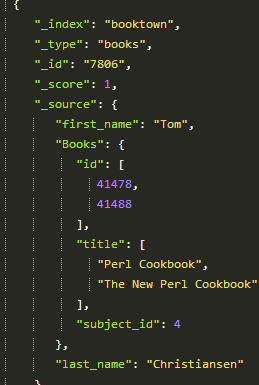
Now we have seen that it is quite easy to get data into Elasticsearch using river-jdbc. We have also seen how it can handle updates. That gets us quite far. Unfortunately, it doesn’t handle deletions. If a record is deleted from the database, it will not automatically be deleted from the index. There have been some attempts to create support for it, but in the latest release it has been completely dropped.
This is due to the river plugin system having some serious problems, and it will perhaps be deprecated some time after the 1.0 release, at least not actively promoted as “the way”. (see the “semi-offical statement” at Linkedin Elasticsearch group). While it is extremely easy to use rivers to get data, there are a lot of problems in having a data integration process running in the same space as Elasticsearch itself. Architecturally, it is perhaps more correct to leave the search engine to itself, and build integrations systems on the side.
Among the recommended alternatives are:
>Use an ETL tool like Talend
>Create your own script
>Edit the source application to send updates to Elasticsearch
Jörg Prante, who is the man behind river-jdbc, recently started creating a replacement calledGatherer.
It is a gathering framework plugin for fetching and indexing data to Elasticsearch, with scalable components.
Anyway, we have data in our index! Rivers may have their problems when used on a large scale, but you would be hard pressed to find anything easier to get started with. Getting data into the index easily is essential when exploring ideas and concepts, creating POCs or just fooling around.
This post has run out of space, but perhaps we can look at some interesting queries next time?
Elasticsearch: Indexing SQL databases. The easy way的更多相关文章
- [Android 开发教程(1)]-- Saving Data in SQL Databases
Saving data to a database is ideal for repeating or structured data, such as contact information. Th ...
- ElasticSearch安装SQL插件
ElasticSearch安装SQL插件下载地址(中国大佬开发的,膜拜ing):https://github.com/NLPchina/elasticsearch-sql 1.记得选择和自己Elast ...
- 十四、.net core(.NET 6)搭建ElasticSearch(ES)系列之给ElasticSearch添加SQL插件和浏览器插件
给ES添加SQL插件的方法: 下载SQL插件地址:https://github.com/NLPchina/elasticsearch-sql 当前最新的是7.12版本,我的ES是7.13版本,暂且将 ...
- Android学习笔记——保存数据到SQL数据库中(Saving Data in SQL Databases)
知识点: 1.使用SQL Helper创建数据库 2.数据的增删查改(PRDU:Put.Read.Delete.Update) 背景知识: 上篇文章学习了保存文件,今天学习的是保存数据到SQL数据库中 ...
- 安装支持elasticsearch使用sql查询插件
一.ElasticSearch-SQL介绍 ElasticSearch-SQL(后续简称es-sql)是ElasticSearch的一个插件,提供了es 的类sql查询的相关接口.支持绝大多数的sql ...
- Exam 70-762 Developing SQL Databases
这个考试还是很有用的,教了很多有用的东西,不错,虽然考试需要很多钱,不过值的尝试.虽然用了sql server 这么多年但是对于事务.多并发的优化还是处于小学生的水平,通过这次考试争取让自己提一个档次 ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块) 通过SparkSQL导入的数据可以来自MySQL数据库.Json数据.Csv数据等,通过load这些数据可以对其做一系列计算 下面通过程序代码来 ...
随机推荐
- 今天在看UWP蓝牙的例子
private async void InitializeRfcommServer() { ListenButton.IsEnabled = false; DisconnectButton.IsEna ...
- SpringMVC学习系列-后记 解决GET请求时中文乱码的问题
SpringMVC学习系列-后记 解决GET请求时中文乱码的问题 之前项目中的web.xml中的编码设置: <filter> <filter-name>CharacterEnc ...
- lgy -oracle
PL/SQL Developer 和 instantclient客户端安装配置(图文) 一: PL/SQL Developer 安装 下载安装文件安装,我这里的版本号是PLSQL7.1.4.1391, ...
- Eclipse tooltip变黑的修正
- 安卓手机已保存WiFi密码查看助手(开源)
一.需求分析 最近电脑需要连接WiFi,却发现WiFi密码给忘记了.而手机里有保存过的WiFi密码,但是在手机的设置界面看不到. 虽然已经有一些可以查看WiFi密码的app,但是主要还是担心密码被那些 ...
- Window 对象
Window 对象 Window 对象表示浏览器中打开的窗口. 如果文档包含框架(<frame> 或 <iframe> 标签),浏览器会为 HTML 文档创建一个 window ...
- windows live Writer test
package com.newegg.shopping.util.listener; import javax.servlet.http.HttpSessionAttributeListener; i ...
- Javascript 代码格式化(JsFormat)
JsFormat 在GitHub 上的地址: https://github.com/jdc0589/JsFormat 这是一个sublime text 2 的插件. 安装: 先安装 sublime p ...
- 前端面试——css篇
css盒子模型 在W3C模型中: 总宽度 = margin-left + border-left + padding-left + width + padding-right + border-rig ...
- 后台运行程序screen or nohup
后台运行 方法1 & 方法2:screen screen –S lnmp à起个名字 进去后运行程序 Ctrl+ad à退出lnmp屏幕 Scree –ls à查看 Screen –r x ...