EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/harrychinese/p/edw_on_hadoop.html).
数据仓库发展已经有二十多年了, 我们先看看数据仓库发展的趋势:
在数据规模小的时候, 采用单节点RDBMS作为存储和执行引擎, 比如Oracle/PostgreSQL/MySQL都行;
当数据规模大了后, 或者时间窗口很紧时, 多采用MPP的解决方案, 比如Teradata/Exedata, 这些MPP多是一体机, 实施成本比较高, 满配后如要做扩容, 哪怕是很小的扩容, 都需投入大量资金, 显得非常不划算. 现在有的互联网企业的数据量非常之大, 即使是采用顶配的一体机, 往往也撑不住.
最近几年, SQL on Hadoop技术发展很快, 尤其是Hive被大量采用之后, 开源社区和商业数据仓库厂商都意识到EDW on Hadoop是未来的方向. 下图是一些现在比较活跃的方案,
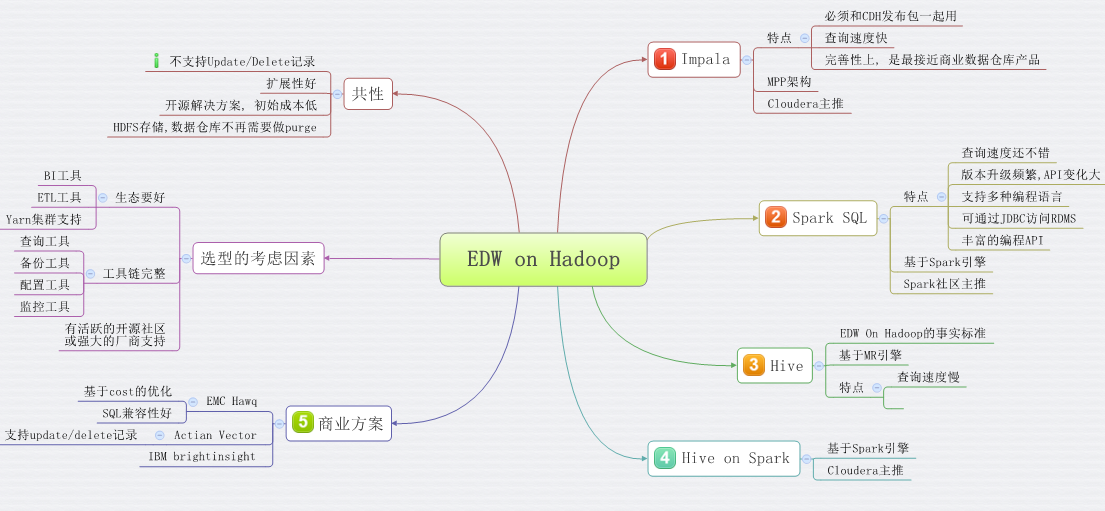
在开源方案中, 我比较看好Impala和Spark SQL, 尤其是Spark SQL. 原因有:
1.使用Spark SQL建构EDW相对容易些: 数据仓库项目中, ETL是非常重要的一环, Spark作为一个高效的计算框架, 借助RDD算子或者SQL写法很胜任ETL的Transform, Extract可以借助Sqoop.
2. Spark SQL性能不错: 在最近1.3版Spark SQL性能已经很不错.
3. Spark, one stack to rule them all: 对于企业而言, spark会给你更多, 将来MLlib应该能替代SAS. 对于开发者而言, 只需要学一门, 就能做好多方面的事情.这有点像Java语言当初的口号,一次编译,到处运行。
4. 社区活跃, 版本迭代快(版本这事, 是优点也是缺点)
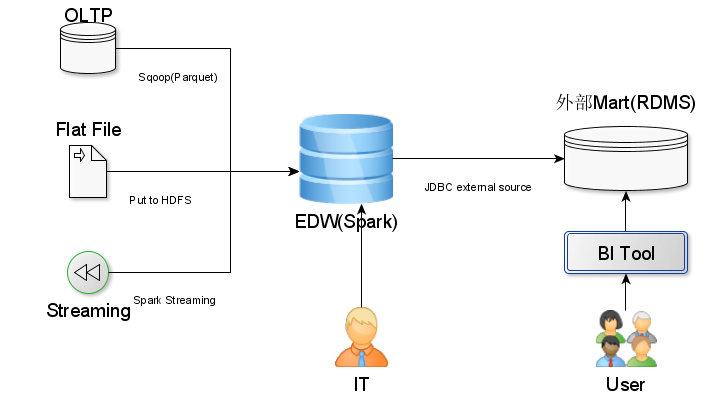
Spark SQL数据仓库架构设计
两张架构图, 第一张是展现EDW的位置, Input有哪些, Output有哪些. Input展现的已经很明显了, 对于EDW输出, 目前传统的BI工具还不支持Spark SQL, 所以我们设计一个外部RDBMS数据集市, Spark数据仓库负责推数据到该数据集市, BI工具直接访问这个数据集市.
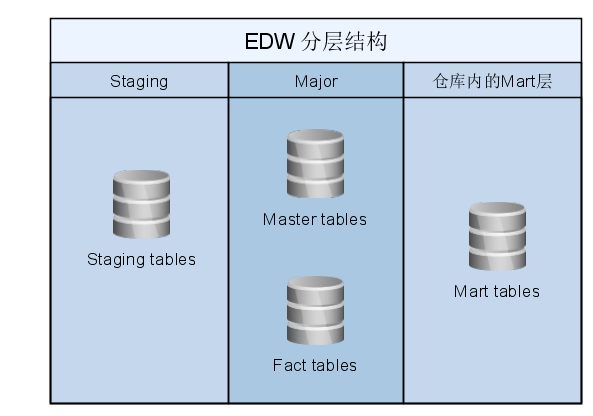
和传统的数据仓库一样, 为了治理需要, 也需要对于Spark EDW分层, 一般三层就足够了.
另外, 我们可考虑设计一个active archive区, 专门归档OLTP数据.
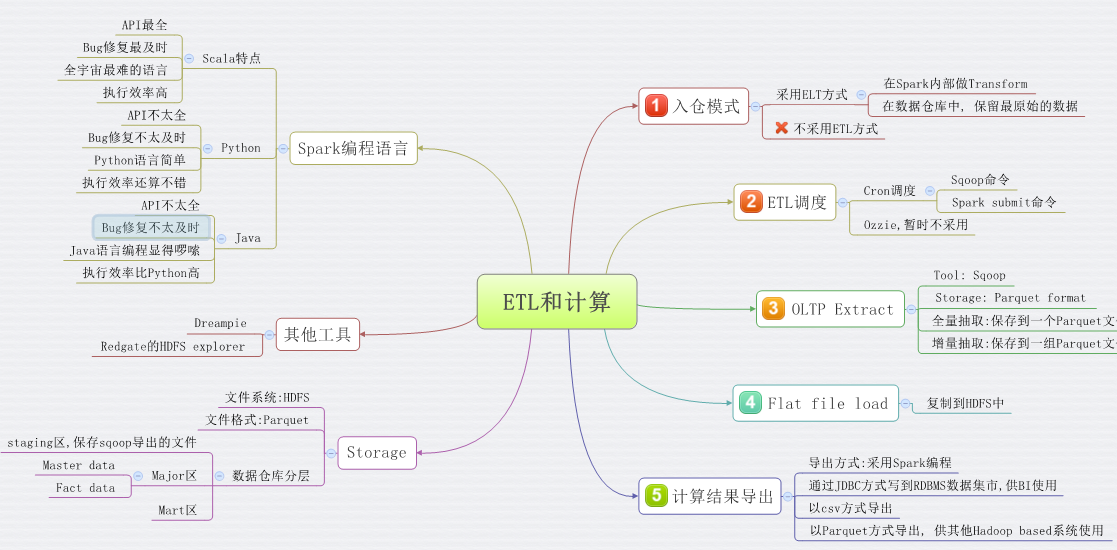
ETL设计思想
每个EDW, ETL工作量都很大, 而且直接影响EDW使用效果.
从大的设计架构看, 推荐采用ELT, 而不是ETL模式. 为什么? 传统ETL最大的好处是, 可以减轻EDW的压力. 对于Hadoop基础上的数据仓库, 但采用ETL的这个好处, 就不明显了, EDW压力可以通过横向扩展, 很容易解决.
对于Extract, 可用Sqoop完成卸载, 推荐采用Parquet格式, 这样Spark SQL可以直接mount这些数据, 也就完整了Load.
Transform在Spark上完成, Spark编程接口非常丰富, 支持Scala/Python/Java编程语言.
至于到底采用哪种开发语言, 我的看法是, 优先采用Python, 无它, Python代码最易读了. 但我们需要清楚的是, Scala API总是最全的, Java 版API次之, Python版的API最少, 另外, API若有bug的话, Python版修复的进度也是最晚的. 但好在Python API现在已经很完善了. 在Spark 1.3版中, Python 的dataFrame缺少createJDBCTable() 编程接口.
简单总结一下
Spark数据仓库的能承担的作用有:
1. 产生BI报表数据
2. 做数据挖掘
3. 作为Active archive
另外, 还能节省不少开销: 省掉了一体机, 省掉了ETL工具, 省掉了SAS分析软件, 省掉高端的存储.
EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考的更多相关文章
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别 Pig
Hadoop生态上几个技术的关系与区别:hive.pig.hbase 关系与区别 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的 ...
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
初接触Hadoop技术的朋友肯定会对它体系下寄生的个个开源项目糊涂了,我敢保证Hive,Pig,HBase这些开源技术会把你搞的有些糊涂,不要紧糊涂的不止你一个,如某个菜鸟的帖子的疑问,when to ...
- Hadoop生态上几个技术的解释:hive、pig、hbase 关系与区别
hadoop生态圈 Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎自己慢慢退出pig的维护之后将它开源贡献到开源社区由所有爱好者来维护.不过现在还是 ...
- 【转载】Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
转自:http://www.linuxidc.com/Linux/2014-03/98978.htm Pig 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了.当初雅虎 ...
- 前端开发工程师 - 05.产品前端架构 - 协作流程 & 接口设计 & 版本管理 & 技术选型 &开发实践
05.产品前端架构 第1章--协作流程 WEB系统 角色定义 协作流程 职责说明 第2章--接口设计 概述 接口规范 规范应用 本地开发 第3章--版本管理 见 Java开发工程师(Web方向) - ...
- 平安银行在开源技术选型上的思考和实践 RocketMQ
小结: 1. https://mp.weixin.qq.com/s/z_c5D8fvHaYvHSczm0nYFA 平安银行在开源技术选型上的思考和实践 平安银行·吴建峰 阿里巴巴中间件 3月7日 随着 ...
- MaxCompute 构建企业云数据仓库CDW的最佳实践建议
在本文中阿里云资深产品专家云郎分享了基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议. 本文内容根据演讲视频以及PPT整理而成. 大家下午好,我是云郎,之前在甲骨文做企业架构师 ...
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
一.概述 根据之前的凡技术必登其官网的原则,我们当然先得找到它的官网:http://hadoop.apache.org/ 1.什么是hadoop 先看官网介绍: The Apache™ Hadoop® ...
- SQL on Hadoop中用到的主要技术——MPP vs Runtime Framework
转载声明 本文转载自盘点SQL on Hadoop中用到的主要技术,个人觉得该文章对于诸如Impala这样的MPP架构的SQL引擎和Runtime Framework架构的Hive/Spark SQL ...
随机推荐
- Solution: Win 10 和 Ubuntu 16.04 LTS双系统, Win 10 不能从grub启动
今年2月份在一台装了Windows的机器上装了Unbuntu 14.04 LTS (双系统, dual-boot, 现已升级到 16.04 LTS). 然而开机时要从grub启动 Windows (选 ...
- Windows系统:桌面,开始菜单和工具栏都不见了
win7桌面,开始菜单和工具栏都不见了 ctrl+alt+del 打开任务管理器 然后文件-运行 --- 输入框里输入 explorer.exe 其实就是打开系统文件夹下的(大约是‘windows ...
- 堆优化的Dijkstra
SPFA在求最短路时不是万能的.在稠密图时用堆优化的dijkstra更加高效: typedef pair<int,int> pii; priority_queue<pii, vect ...
- 机器学习笔记—Logistic回归
本文申明:本系列笔记全部为原创内容,如有转载请申明原地址出处.谢谢 序言:what is logistic regression? Logistics 一词表示adj.逻辑的;[军]后勤学的n.[逻] ...
- js 递归下的循环
的递归下的循环不能使用forEach 可以使用for代替 错误写法 // 获取完整名字 var getFullName = function(code, resultName) { if (code ...
- Microsoft SQL Server Management Studio ------------------------------ 附加数据库 对于 服务器
http://zhidao.baidu.com/link?url=didvEEY86Kap_F9PnRAJMGoLXv63IW1fhElfiOpkkmalJ9mvZoqNULlGKcGHN31y_4z ...
- 【原】javascript数组操作
继续我的第二遍<javascript高级程序设计第三版>,今天要做的笔记是array 一.数组的操作 1.数组的创建: var colors= new Array(); //创建一个数组 ...
- String类中的一些函数使用方法
最常用的就是Length()函数了,求字符串的长度 String s="";int i=s.length();i结果为0. 如果是String s=null;int i=s.len ...
- 20145212 实验四《Andoid开发基础》
20145212 实验四<Andoid开发基础> 实验内容 安装Android Studio 运行安卓AVD模拟器 使用Android运行出模拟手机并显示自己的学号 实验过程 一.安装An ...
- 转换流——OutputStreamWriter类与InputStreamReader类
字节流和字符流的转换类 OutputStreamWriter:是Writer的子类,将输出的字符流变成字节流 InputStreamReader:是Reader的子类,将输入的字节流变成字符流 将字节 ...