spark和scala的搭建
Scala--部署安装步骤
(1)上传并解压安装scala安装包
例:tar -zxvf scala--** -C 指定位置
(2)设置环境变量
vim /etc/profile
export SCALA_HOME=spark软件包位置
export PATH=$PATH:${SCALA_HOME}/bin

source /etc/profile使环境变量生效
(3)验证scala 启动成功

spark--部署与安装
(1)上传并解压安装spark安装包
tar -zxvf / export/ software/ spark-** -C 指定位置
(2)设置环境变量
vim /etc/profile
export SPARK_HOME=spark软件包位置
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin

(3)修改配置文件
A.先备份文件cp spark env.sh.template spark-env.sh
B.修改配置文件-spark-env.sh
添加一下内容:
export SCALA_HOME=spark软件包位置
export JAVA_HOME=java软件包位置
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=hadoop软件包位置
(#)export SPARK_MASTER_WEBUI_PORT=8080
(#)export SPARK_MASTER_PORT=7070
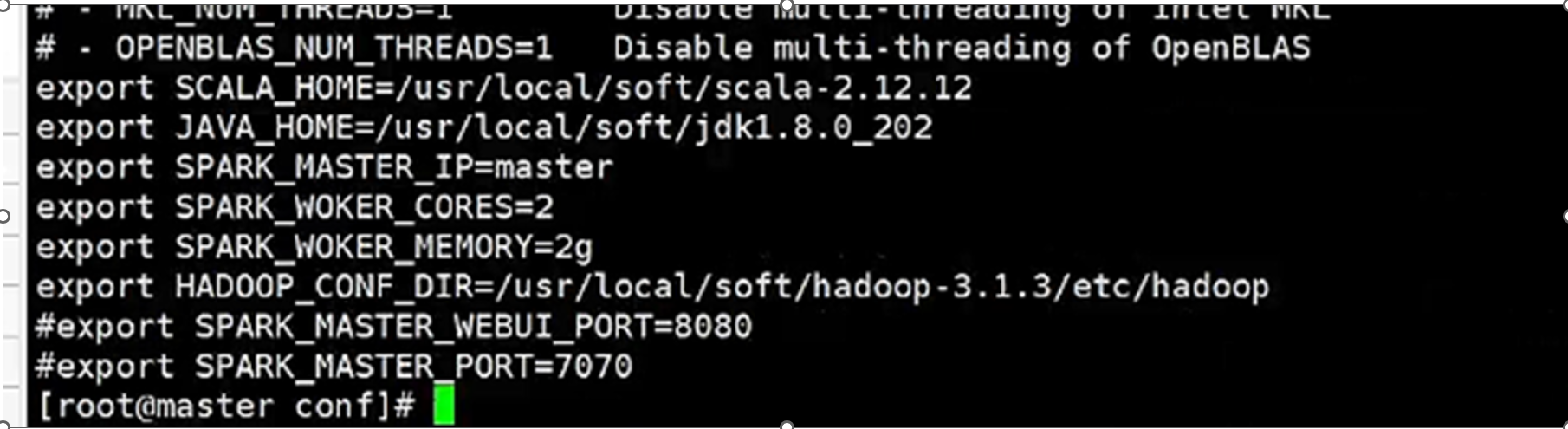
(3.1)在conf/创建slaves文件,指定master,slave1,slave2

(4)分发文件 --分别通过scp命令将软件包拷贝到节点(slave1,slave2)
scp -r spark slave1:目的地
scp -r spark slave1:目的地
(5)分别在slave1 slave2上设置环境变量
vim /etc/profile
export SPARK_HOME=spark软件包位置
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
(6)启动集群:spark/sbin目录下:./start-all.sh
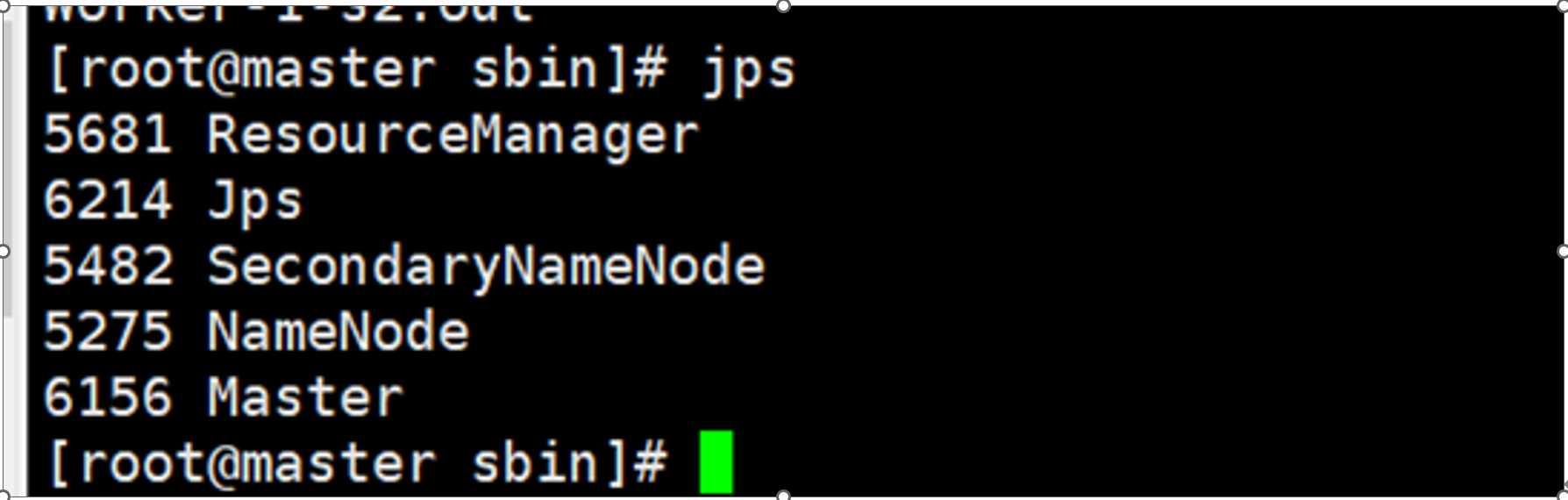
查看节点:
maser:
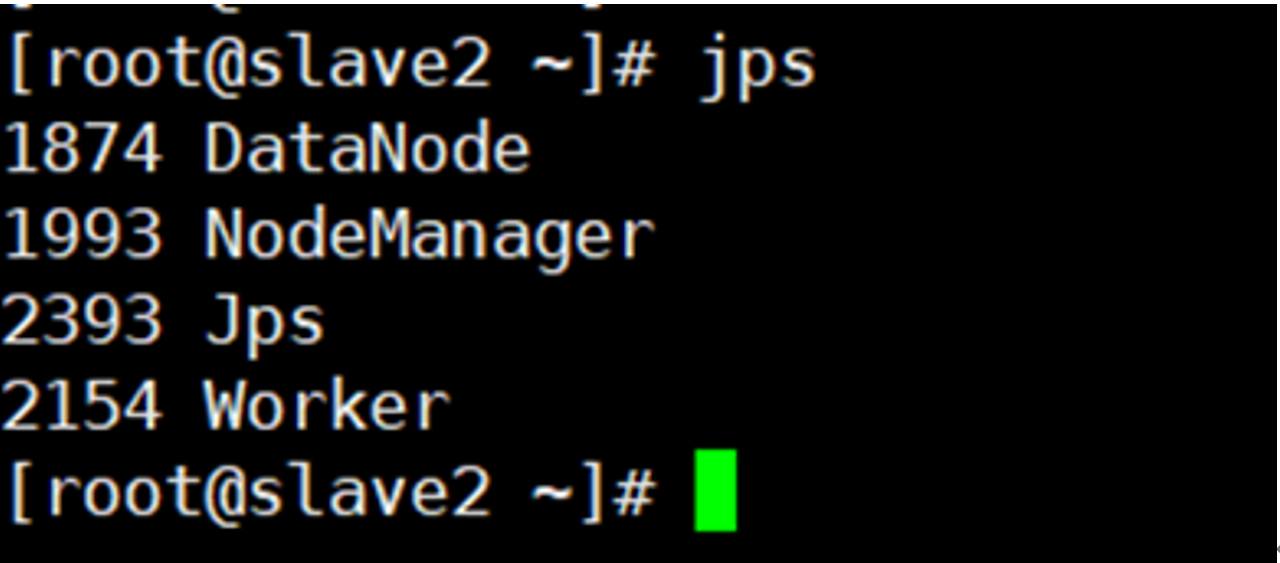
slave1:
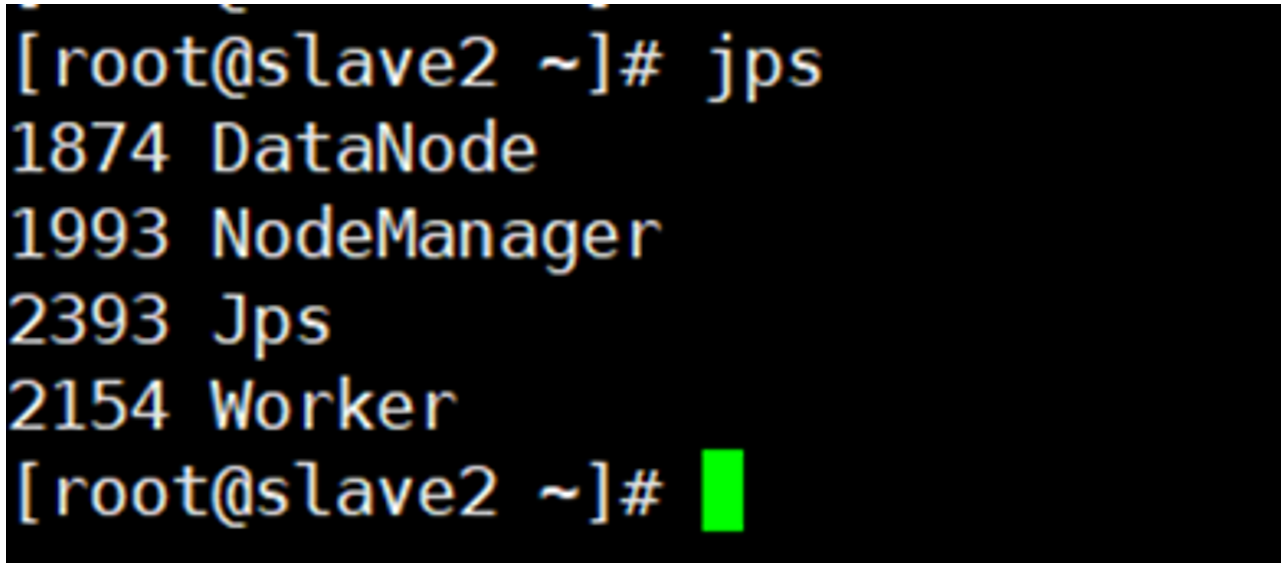
slave2:
spark验证 ---浏览器输入ip:8080
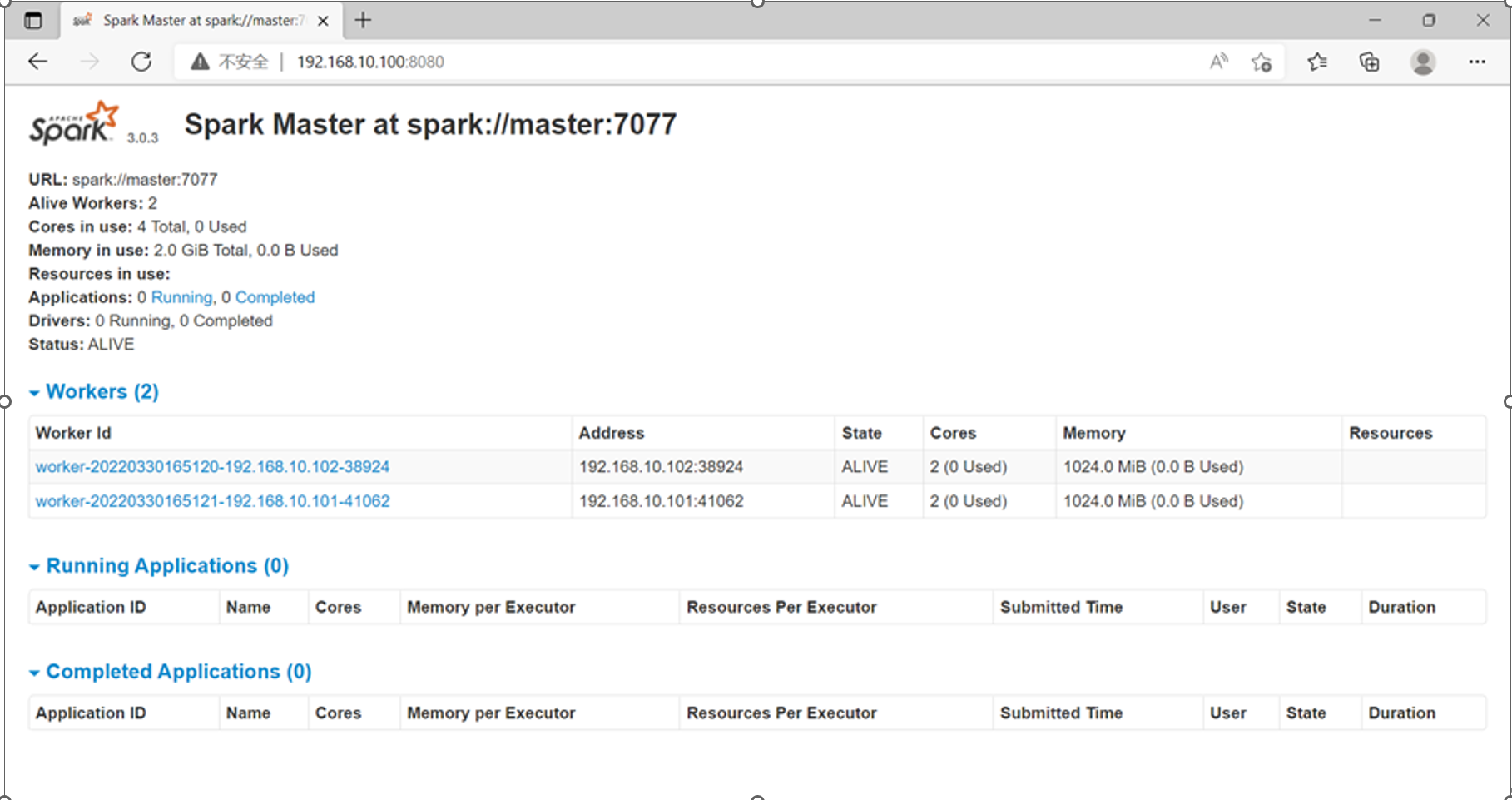
单机伪分布式spark搭建
1.上传并解压安装scala安装包
2.复制模板文件
注:在目录中进入/conf,复制spark-env.sh.template文件为spark-env.sh
3.修改配置文件spark-env.sh
export JAVA_HOME=/root/123/jdk
export HADOOP_HOME=/root/123/hadoop
export HADOOP_CONF_DIR=/root/123/hadoop/etc/hadoop
export SPART_MASTER_IP=master
export SPART_LOCAL_IP=master
4.进入目录下的/sbin启动soark集群
命令: ./start-all.sh
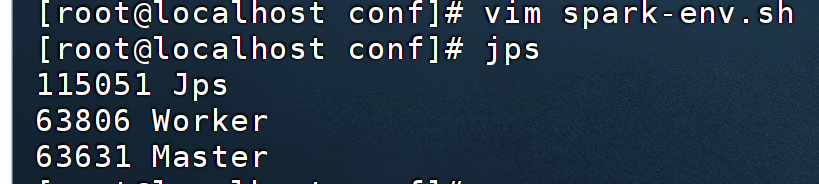
5.jps查看
spark和scala的搭建的更多相关文章
- Spark集群搭建【Spark+Hadoop+Scala+Zookeeper】
1.安装Linux 需要:3台CentOS7虚拟机 IP:192.168.245.130,192.168.245.131,192.168.245.132(类似,尽量保持连续,方便记忆) 注意: 3台虚 ...
- eclipse创建maven管理Spark的scala
说明,由于spark是用scala写的.因此,不管是在看源码还是在写spark有关的代码的时候,都最好是用scala.那么作为一个程序员首先是必须要把手中的宝剑给磨砺了.那就是创建好编写scala的代 ...
- Spark之集群搭建
注意,这种安装方式是集群方式:然后有常用两种运行模式: standalone , on yarn 区别就是在编写 standalone 与 onyarn 的程序时的配置不一样,具体请参照spar2中的 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Spark+IDEA单机版环境搭建+IDEA快捷键
1. IDEA中配置Spark运行环境 请参考博文:http://www.cnblogs.com/jackchen-Net/p/6867838.html 3.1.Project Struct查看项目的 ...
- 一文读懂spark yarn集群搭建
文是超简单的spark yarn配置教程: yarn是hadoop的一个子项目,目的是用于管理分布式计算资源,在yarn上面搭建spark集群需要配置好hadoop和spark.我在搭建集群的时候有3 ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
- Spark—local模式环境搭建
Spark--local模式环境搭建 一.Spark运行模式介绍 1.本地模式(loca模式):spark单机运行,一般用户测试和开发使用 2.Standalone模式:构建一个主从结构(Master ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-63 - Canvas和SVG元素定位
1.简介 今天宏哥分享的在实际测试工作中很少遇到,比较生僻,如果突然遇到我们可能会脑大.懵逼,一时之间不知道怎么办?所以宏哥这里提供一种思路供大家学习和参考. 2.SVG简介 svg也是html5新增 ...
- Java开发环境安装笔记
目录 JDK的版本 Java 8 Java 9 Java 11 (LTS) Java 17 (LTS) Java 21 JDK的环境变量设置 JAVAHOME 和 PATH 环境变量 JAVAPATH ...
- kubernetes中集成istio出现拉取配置中心数据失败导致服务启动失败
荐
由于在k8s使用了grpc,所以这里我们集成istio来实现http2的自动发现以及负载均衡,但是随着节点增加,istio之前同步配置时间边长导致第一次启动时,服务启动拉取配置时istio却还没初始化 ...
- C#模拟键盘输入、键状态和监听键盘消息
模拟键盘输入 模拟键盘输入的功能需要依赖Windows函数实现,这个函数是SendInput,它是专门用来模拟键盘.鼠标等设备输入的函数. 另外和键盘输入相关的函数还有SendKeys,它是Syste ...
- Homebrew 使用
使用 brew install brew uninstall|remove|rm brew list # *显示已安装软件列表 brew upgrade # 更新 Homebrew brew sear ...
- 使用go+gin编写日志中间,实现自动化收集http访问信息,错误信息等,自动化生成日志文件
1.首先在logger包下 点击查看代码 package logger import ( "fmt" "io" "net/http" &qu ...
- 小tips:ECMA-262定义的7种错误类型
七种错误类型如下: Error EvalError RangeError ReferenceError SyntaxError TypeError URIError 其中,Error是基类型(其他六种 ...
- ASP.NET Core Library – Google libphonenumber (Country Dial Code)
前言 Google libphonenumber 是 Java 的, ASP.NET Core 只是 port 过去而已. 以前在 angular2 学习笔记 ( translate, i18n 翻译 ...
- Maven高级——多环境配置与应用
多环境配置与应用 开发步骤 定义多环境 <!--配置多环境--> <profiles> <!--开发环境--> <profile> <id> ...
- Spring —— AOP(面向切面编程)
AOP(Aspect Oriented Programming)简介 面向切面编程,一种编程范式,指导开发者如何组织程序结构 作用:在不惊动原始设计的基础上为其进行功能增强 Spring理念:无入侵式 ...