制作语义分割数据集(VOC格式)
环境:python3.8 labelme=5.0.1
1、使用labelme标注工具
直接在命令行安装或者在anaconda下面新建虚拟环境安装(避免污染环境,不用的时候可以直接delete该环境)
直接命令行(base)安装
pip install labelme
labelme
创建虚拟环境安装,python版本选择3.8.x,打开Anaconda Prompt
conda create -n labelme python=3.8
conda activate labelme
pip install labelme
labelme
当前自动安装的版本为labelme-5.0.1
标注信息图如下

2:使用Labelme官方提供的脚本json_to_dataset.py把json转换为png形式,对于多分类的数据标注,需要在下面路径找到json_to_dataset.py修改:
虚拟环境下的路径为(具体情况具体分析):
C:\Users\siyu\miniconda3\envs\labelme\Lib\site-packages\labelme\cli
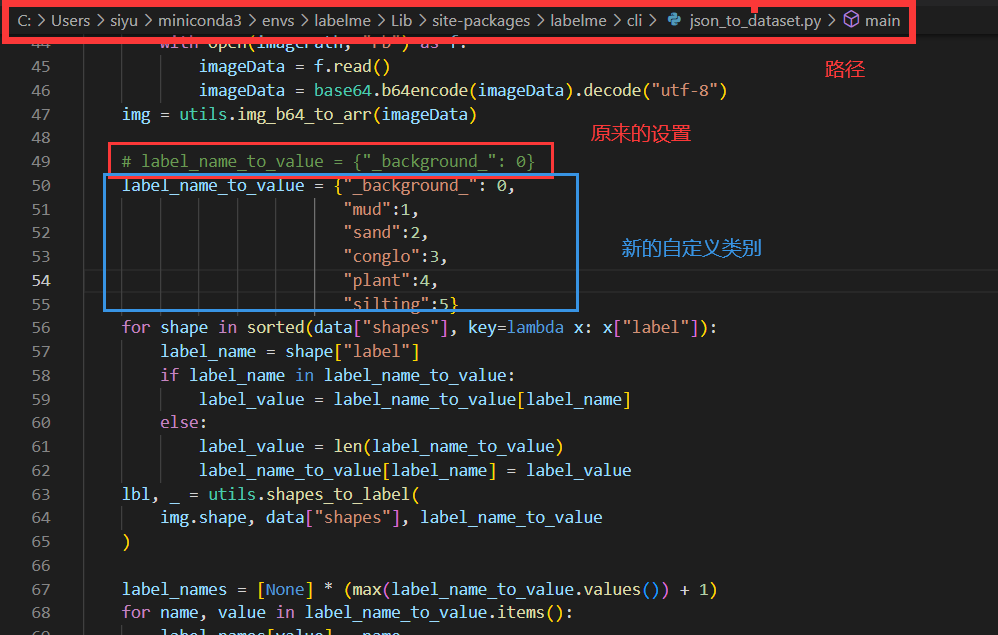
运行脚本执行转换json操作,以下代码名为labelme_json_to_png.py
# -*- coding: utf-8 -*- import os
# json文件的存储路径
json_folder = r"E:/Dataset/3" # 获取文件夹内的文件名
FileNameList = os.listdir(json_folder)
for i in range(len(FileNameList)):
# 判断当前文件是否为json文件
if(os.path.splitext(FileNameList[i])[1] == ".json"):
json_file = json_folder + "\\" + FileNameList[i]
# 用程序执行命令,将该json文件转为png
os.system(r"python C:\Users\siyu\miniconda3\envs\labelme\Lib\site-packages\labelme\cli\json_to_dataset.py " + json_file)
运行上述代码
生成的文件
3:把数据整理为images,segmentations对应的文件夹
脚本如下:spilit_labelme_dataset.py
1 # -*- coding: utf-8 -*-
2 import os
3 import numpy as np
4 import json
5 import shutil
6
7 def find_dir_path(path, keyword_name, dir_list):
8 files = os.listdir(path)
9 for file_name in files:
10 file_path = os.path.join(path, file_name)
11 if os.path.isdir(file_path) and keyword_name not in file_path:
12 find_dir_path(file_path, keyword_name, dir_list)
13 elif os.path.isdir(file_path) and keyword_name in file_path:
14 dir_list.append(file_path)
15
16
17 all_result_path = []
18 src_path = r'E:\DataSet\3'
19 label_save_path = r'E:\DataSet\MyDataset\SegmentationClass'
20 image_save_path = r'E:\DataSet\MyDataset\JPEGImages'
21 find_dir_path(src_path, '_json', all_result_path) # 找出所有带着关键词(_json)的所有目标文件夹
22 #print(all_result_path)
23
24
25 for dir_path in all_result_path:
26 # print(dir_path)
27 file_name = dir_path.split('\\')[-1]
28 key_word = file_name[:-5]
29 # print(key_word)
30 label_file = dir_path + "\\" + "label.png"
31 new_label_save_path = label_save_path + "\\" + key_word + ".png" # 复制生成的label.png到新的文件夹segmentations
32 # print(label_file,new_label_save_path)
33 shutil.copyfile(label_file, new_label_save_path)
34
35 img_dir = os.path.dirname(dir_path) # 复制原图到新的文件夹images
36 img_file = img_dir + "\\" + key_word + ".jpg"
37 new_img_save_path = image_save_path + "\\" + key_word + ".jpg"
38 shutil.copyfile(img_file, new_img_save_path)
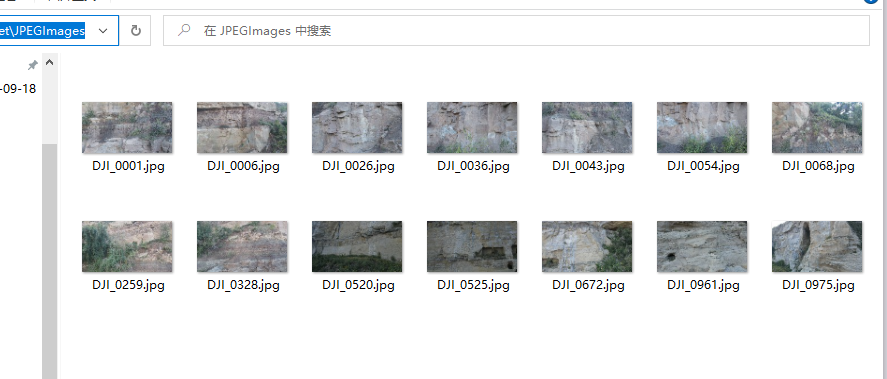
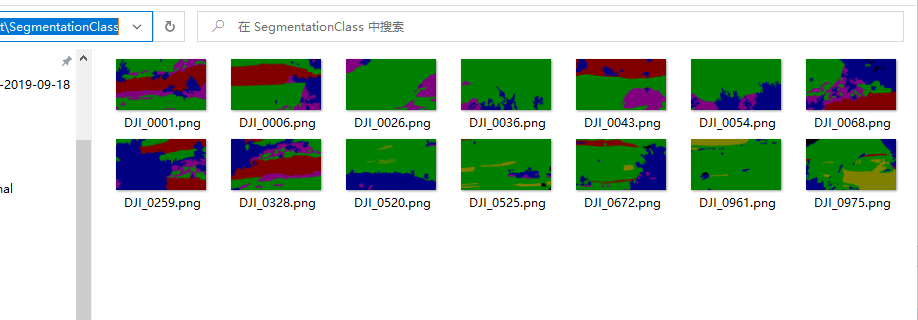
整理后如下图所示
4: 把png转换为label图
前面的用命令行转化的是8为掩码图像,不利于我们操作,因此转化为灰度图
1 from PIL import Image
2 import cv2
3 import matplotlib.pyplot as plt
4 import numpy as np
5
6 root="E:/DataSet/MyDataset/SegmentationClass"
7 fname="DJI_0001"
8
9 # root="./dataset"
10 # fname="DJI_0001_0_0"
11
12 # 使用PIL,就是windows的照片查看器
13 # im = Image.open('%s/%s.png' % (root, fname))
14 # print(im.load()[230,216])
15 # im.show()
16
17
18 im = Image.open('%s/%s.png' % (root, fname))
19 im.show()
20 im = np.array(im)
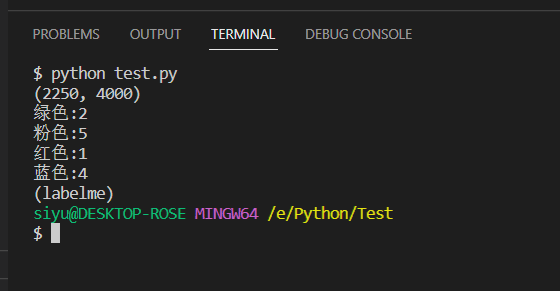
21 print(im.shape)
22 print("绿色:{0}".format(im[20][126]))
23 print("粉色:{0}".format(im[173][2972]))
24 print("红色:{0}".format(im[1097][661]))
25 print("蓝色:{0}".format(im[745][164]))
运行上述代码可以看到以及变成图像大小的矩阵
在此给出一些查看图片以及具体位置像素的方法
1. 使用PIL库读取图片
# 使用PIL,就是windows的照片查看器
im = Image.open('%s/%s.png' % (root, fname))
print(im.load()[230,216]) #读取像素值
im.show()
2. 使用matplotlib读取并显示图片
# 带坐标和像素值!!好极了
import matplotlib.pyplot as plt
im = plt.imread('%s/%s.png' % (root, fname))
plt.imshow(im)
plt.show()
3. 使用opencv读取图片
import cv2 # opencv显示
img = cv2.imread('%s/%s.png' % (root, fname),)
cv2.namedWindow('Image', cv2.WINDOW_NORMAL )#cv2.WINDOW_AUTOSIZE)
cv2.imshow('Image',img)
cv2.waitKey(0)
5: 划分验证集和测试集
划分验证集与测试集的脚本voc.annotation.py
import os
import random #-------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# 修改train_percent用于改变验证集的比例 9:1
#
# 当前该库将测试集当作验证集使用,不单独划分测试集
#-------------------------------------------------------#
trainval_percent = 0.9
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
dataset_path = './MyDataset/' if __name__ == "__main__":
random.seed(0)
print("Generate txt in ImageSets.")
segfilepath = os.path.join(dataset_path, 'SegmentationClass')
saveBasePath = os.path.join(dataset_path, 'ImageSets/Segmentation') if not os.path.exists(saveBasePath):
os.makedirs(saveBasePath) temp_seg = os.listdir(segfilepath)
total_seg = []
for seg in temp_seg:
if seg.endswith(".png"):
total_seg.append(seg) num = len(total_seg)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr) print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w') for i in list:
name=total_seg[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name) ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
6: 将图片划分为更小的图片(可选项)
import cv2
import os
import numpy as np
from PIL import Image def mkdir(path):
folder=os.path.exists(path)
if not folder:
os.makedirs(path) #原始图片的h,w
def cutImg(img,cutSize,fileName):
'''
img 是图像矩阵,cutSize是裁剪大小(正方形),fileName
'''
sumWidth = img.shape[1] #图片宽、高
sumHeight = img.shape[0]
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
rnumber=int(sumWidth/cutSize)
cnumber=int(sumHeight/cutSize) print("裁剪所得{0}列图片,{1}行图片.".format(rnumber,cnumber))
for i in range(rnumber):
for j in range(cnumber):
# imgs=img[j*cutSize:(j+1)*cutSize,i*cutSize:(i+1)*cutSize] #裁剪png时使用
imgs=img[j*cutSize:(j+1)*cutSize,i*cutSize:(i+1)*cutSize,:] #裁剪jpg时使用,三通道
a=[j,i,imgs.shape]
# 裁剪png时使用
# cv2.imwrite(SAVE_DIR+os.path.splitext(fileName)[0]+'_'+str(j)+'_'+str(i)+os.path.splitext(fileName)[1],img[j*cutSize:(j+1)*cutSize,i*cutSize:(i+1)*cutSize])
# 裁剪jpg时使用,三通道
cv2.imwrite(SAVE_DIR+os.path.splitext(fileName)[0]+'_'+str(j)+'_'+str(i)+os.path.splitext(fileName)[1],img[j*cutSize:(j+1)*cutSize,i*cutSize:(i+1)*cutSize,:])
print(imgs.shape)
print(a)
print("裁剪完成,得到{0}张图片.".format(rnumber*cnumber))
print("文件保存在{0}".format(SAVE_DIR)) # 返回原图和标签的URL
def imgPath(fileName):
suffix = os.path.splitext(fileName)[1]
if suffix == ".jpg":
return os.path.splitext(fileName)[0] """调用裁剪函数示例"""
IMG_DIR='E:/DataSet/MyDataset/JPEGImages/'
GT_DIR='E:/DataSet/MyDataset/SegmentationClass/'
CUTSIZE= 512 #裁剪为正方形
SAVE_DIR= './dataset/' # IMG_PATH=[]
# GT_PATH=[] FILE_NAME=[]
IMAGE_GT = [] for fileName in os.listdir(IMG_DIR):
FILE_NAME.append(imgPath(fileName)) for i in FILE_NAME:
IMAGE_GT.append([IMG_DIR+i+'.jpg',GT_DIR+i+'.png']) for i in IMAGE_GT:
jpg = Image.open(i[0])
jpgName = i[0].split('/')[-1]
jpg = np.array(jpg) """裁剪标签图片"""
# png = Image.open(i[1])
# pngName = i[1].split('/')[-1]
# png = np.array(png) cutImg(jpg,CUTSIZE,jpgName)
制作语义分割数据集(VOC格式)的更多相关文章
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet,语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类;目标检测只有两类,目标和非目标,就是在一张图片中找到并用box标注出所有的目标.
from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 阅读数:4369 前言 在这里, ...
- [论文笔记][半监督语义分割]Universal Semi-Supervised Semantic Segmentation
论文原文原文地址 Motivations 传统的训练方式需要针对不同 domain 的数据分别设计模型,十分繁琐(deploy costs) 语义分割数据集标注十分昂贵,费时费力 Contributi ...
- 用python将MSCOCO和Caltech行人检测数据集转化成VOC格式
代码:转换用的代码放在这里 之前用Tensorflow提供的object detection API可以很方便的进行fine-tuning实现所需的特定物体检测模型(看这里).那么现在的主要问题就是数 ...
- 仿照CIFAR-10数据集格式,制作自己的数据集
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50801226 前一篇博客:C/C++ ...
- PyTorch中的MIT ADE20K数据集的语义分割
PyTorch中的MIT ADE20K数据集的语义分割 代码地址:https://github.com/CSAILVision/semantic-segmentation-pytorch Semant ...
- 语义分割之车道线检测Lanenet(tensorflow版)
Lanenet 一个端到端的网络,包含Lanenet+HNet两个网络模型,其中,Lanenet完成对车道线的实例分割,HNet是一个小网络结构,负责预测变换矩阵H,使用转换矩阵H对同属一条车道线的所 ...
- 全卷积网络(FCN)实战:使用FCN实现语义分割
摘要:FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题. 本文分享自华为云社区<全卷积网络(FCN)实战:使用FCN实现语义分割>,作者: AI浩. FCN对图像进行像素级的 ...
- caffe初步实践---------使用训练好的模型完成语义分割任务
caffe刚刚安装配置结束,乘热打铁! (一)环境准备 前面我有两篇文章写到caffe的搭建,第一篇cpu only ,第二篇是在服务器上搭建的,其中第二篇因为硬件环境更佳我们的步骤稍显复杂.其实,第 ...
- R-CNN论文翻译——用于精确物体定位和语义分割的丰富特征层次结构
原文地址 我对深度学习应用于物体检测的开山之作R-CNN的论文进行了主要部分的翻译工作,R-CNN通过引入CNN让物体检测的性能水平上升了一个档次,但该文的想法比较自然原始,估计作者在写作的过程中已经 ...
- 笔记:基于DCNN的图像语义分割综述
写在前面:一篇魏云超博士的综述论文,完整题目为<基于DCNN的图像语义分割综述>,在这里选择性摘抄和理解,以加深自己印象,同时达到对近年来图像语义分割历史学习和了解的目的,博古才能通今!感 ...
随机推荐
- Joker 智能开发平台再推重磅新品,引领开发新潮流
自 Joker 智能开发平台的前端可视化版本惊艳亮相后,便迅速在行业内掀起热潮,其创新的理念与出色的性能,为开发者和企业打造了高效.便捷的开发新路径,备受瞩目与好评.如今,Joker 智能开发平台即将 ...
- windows 稀疏文件 (sparse file) 的一个实用场景——解决 SetEndOfFile 占据磁盘空间引入的性能问题
前言 之前写过一篇文章说明文件空洞:<[apue] 文件中的空洞>,其中提到了 windows 稀疏文件是制造空洞的一种方式,但似乎没什么用处,如果仅仅处理占用磁盘空间的场景,使用SetE ...
- SQL Server 中的事务管理
SQL Server 中的事务是什么? 事务是应该作为一个单元执行的一组 SQL 语句.这意味着事务确保所有命令都成功或都不成功.如果事务中的命令之一失败,则所有命令都失败,并且在数据库中修改的任何数 ...
- 实现领域驱动设计 - 使用ABP框架 - 更新操作实体
用例演示 - 更新 / 操作实体 一旦一个实体被创建,它将被用例更新/操作,直到它从系统中删除.可以有不同类型的用例直接或间接地更改实体 在本节中,我们将讨论更改 Issue 的多个属性的典型更新操作 ...
- 【服务器】Nodejs在局域网配置https访问
[服务器]Node.js在局域网配置https访问 零.需求: 做一个局域网WebRTC视频聊天系统,需要用到HTTPS.因此,配置Node.js使其支持HTTPS访问. 一.解决 在线生成和证书 访 ...
- CSS实现单行显示文本并适应浏览器大小
实现 .text { white-space:nowrap; /*文本不换行*/ overflow: hidden; /*超出文本隐藏*/ text-overflow:ell ...
- 关于TFDMemtable的使用场景【3】处理数据
原因很多: 1.通过TFDMemtable处理数据时,避免影响数据感知 2.处理速度很快. ------------------------------ 从Tdataset读取数据: Procedur ...
- Koin 依赖注入: 在 Android 模块化项目中定义 Room 数据库的最佳实践
前置 本文发布于个人小站:https://wavky.top/db-in-multi-modules/ 欢迎移步至小站,关注更多技术分享,获得更佳阅读体验 (不保证所有技术文章都会同步发表到博客园) ...
- 云备份技术解析:云容灾 CT-CDR 关键技术介绍
本文分享自天翼云开发者社区<云备份技术解析:云容灾 CT-CDR 关键技术介绍>,作者:沈****军 1.CDP+存储快照,实现秒级RPO (1)CDP技术:云容灾CT-CDR(Cloud ...
- RocketMQ消息是如何存储的
RocketMQ的消息存储是一个复杂而高效的过程,设计上充分考虑了性能和扩展性, 消息存储的主要组件包括CommitLog文件.消费队列文件(ConsumerQueue).以及索引文件(IndexFi ...