DM SQL关联列 like 优化案例
1.1、sql优化背景
达梦一哥们找我优化条SQL,反馈在DM8数据库执行时间很慢出不来结果, 监控工具显示这条SQL的执行时间需要20多万毫秒,安排。
1.2、慢sql和执行时间
select a.col1 as d_id,
a.col2 as s_id,
a.col3 as bm,
a.col4,
a.col5,
(select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
a.col6 as dzzlxr,
a.col7 as dzzlxdh,
(select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
a.col8,
date_format(a.col9, '%Y-%m-%d %H:%i:%s') as gx,
a.col10 as cid,
a.col11 as tp,
(select b.col5 from table1 b where b.col1 = a.col2) as sj,
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
from table1 a
where 1 = 1
and a.col1 in ( /* 这里 in 了 600 个 字符串条件 */ );
100条执行成功, 执行耗时1分 28秒 248毫秒. 执行号:1432757809
1.3、慢sql执行计划
1 #NSET2: [1330892675, 12345, 692]
2 #PIPE2: [1330892675, 12345, 692]
3 #PIPE2: [1330892669, 12345, 692]
4 #PIPE2: [1330892663, 12345, 692]
5 #PIPE2: [1330892657, 12345, 692]
6 #PIPE2: [1330892648, 12345, 692]
7 #PRJT2: [4, 12345, 692]; exp_num(17), is_atom(FALSE)
8 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
9 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
10 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
11 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201688.colname,DMTEMPVIEW_22201688.colname]
12 #SPL2: [1330892644, 1, 852]; key_num(2), spool_num(4), is_atom(FALSE), has_variable(0)
13 #PRJT2: [1330892644, 1, 852]; exp_num(3), is_atom(FALSE)
14 #HAGR2: [1330892644, 1, 852]; grp_num(1), sfun_num(3); slave_empty(0) keys(A.ROWID)
15 #NEST LOOP LEFT JOIN2: [1327131762, 71772595, 852]; join condition(DZZ.col11 LIKE exp11) partition_keys_num(0) ret_null(0)
16 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
17 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
18 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
19 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201689.colname,DMTEMPVIEW_22201689.colname]
20 #HASH2 INNER JOIN: [26, 116278, 160]; LKEY_UNIQUE KEY_NUM(1); KEY(DZZ.col1=DY.col1) KEY_NULL_EQU(0)
21 #CSCN2: [1, 12345, 104]; INDEX33571530(table1 as DZZ)
22 #SSCN: [13, 116278, 56]; IDX_DYJBXX_ORGID(table3 as DY)
23 #SPL2: [9, 9876, 740]; key_num(2), spool_num(3), is_atom(FALSE), has_variable(0)
24 #PRJT2: [9, 9876, 740]; exp_num(2), is_atom(FALSE)
25 #HASH RIGHT SEMI JOIN2: [9, 9876, 740]; n_keys(1) KEY(DMTEMPVIEW_22201694.colname=A.col1) KEY_NULL_EQU(0)
26 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
27 #HASH2 INNER JOIN: [9, 9876, 740]; LKEY_UNIQUE KEY_NUM(1); KEY(B.col1=A.col2) KEY_NULL_EQU(0)
28 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as B)
29 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
30 #SPL2: [5, 11618, 740]; key_num(2), spool_num(2), is_atom(FALSE), has_variable(0)
31 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
32 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201695.colname=A.col1) KEY_NULL_EQU(0)
33 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
34 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col22) KEY_NULL_EQU(0)
35 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb3',min),('zb3',max))
36 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
37 #SPL2: [5, 11618, 740]; key_num(2), spool_num(1), is_atom(FALSE), has_variable(0)
38 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
39 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201696.colname=A.col1) KEY_NULL_EQU(0)
40 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
41 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col21) KEY_NULL_EQU(0)
42 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb2',min),('zb2',max))
43 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
44 #SPL2: [5, 11618, 740]; key_num(2), spool_num(0), is_atom(FALSE), has_variable(0)
45 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
46 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201697.colname=A.col1) KEY_NULL_EQU(0)
47 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
48 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col20) KEY_NULL_EQU(0)
49 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb1',min),('zb1',max))
50 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
1.4、涉及表的数据量
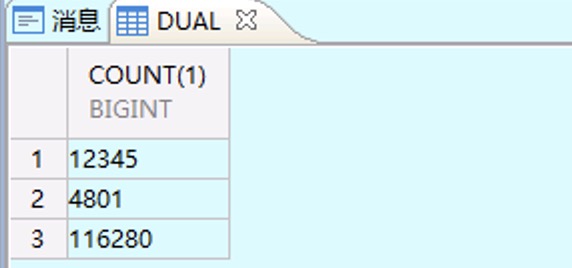
select count(1) from table1
union all
select count(1) from table2
union all
select count(1) from table3;
1.5、分析过程
用瞪眼大法观察,目测是这几段标量子查询导致慢的(啥是瞪眼大法?问就是优化这么多案例的经验)
(select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
(select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
每段标量子查询测试后,发现是最后一段标量子查询缓慢导致
-- (select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
-- (select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
-- (select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 like concat(a.col11,'%')) as rc
做了个测试,如果将 like 改成 = 的话,非常快出结果
(select count(*) from table3 dy left join table1 dzz on dy.col1 = dzz.col1 where dzz.col11 = a.col11 ) as rc
dzz.col11 字段是有索引,尝试过各种手段都用不上,只能改写SQL。
2.1、SQL等价改写
我想法就是将 like 关联这种模糊态查询改成 = 这种确定态的精准匹配逻辑,想了好几个小时都没什么头绪。
后面只能去翻翻落总博客,卧槽,还没想到真的给我看到类似的case ,瞬间有了灵感做了下面改写:
select a.col1 as d_id,
a.col2 as s_id,
a.col3 as bm,
a.col4,
a.col5,
(select b.col1 from table2 b where b.col_itname = 'zb1' and b.col1 = a.col20) as bb,
a.col6 as dzzlxr,
a.col7 as dzzlxdh,
(select b.col1 from table2 b where b.col_itname = 'zb2' and b.col1 = a.col21) as bc,
(select b.col1 from table2 b where b.col_itname = 'zb3' and b.col1 = a.col22) as cb,
a.col8,
date_format(a.col9, '%Y-%m-%d %H:%i:%s') as gx,
a.col10 as cid,
a.col11 as tp,
(select b.col5 from table1 b where b.col1 = a.col2) as sj,
b.cnt as rc
from table1 a
LEFT JOIN (
SELECT COUNT(*) cnt,
dzz.col11
FROM table3 dy
LEFT JOIN table1 dzz
ON dy.col1 = dzz.col1
GROUP BY dzz.col11
) b ON SUBSTR(b.col11, 1, LENGTH(a.col11)) = a.col11
where 1 = 1
and a.col1 in (
-- 这里 in 了 600 个 字符串条件
);
100条执行成功, 执行耗时5秒 326毫秒. 执行号:1435485506
改写完后5秒左右就能出结果了,差集比对后也是等价,呦西。
2.2、SQL改写后执行计划
1 #NSET2: [524737849, 358862, 740]
2 #PIPE2: [524737849, 358862, 740]
3 #PIPE2: [524737843, 358862, 740]
4 #PIPE2: [524737837, 358862, 740]
5 #PIPE2: [524737831, 358862, 740]
6 #PRJT2: [524737822, 358862, 740]; exp_num(16), is_atom(FALSE)
7 #NEST LOOP LEFT JOIN2: [524737822, 358862, 740]; join condition(A.col11 = exp11) partition_keys_num(0) ret_null(0)
8 #NEST LOOP INDEX JOIN2: [4, 12345, 692]
9 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
10 #BLKUP2: [3, 1, 0]; INDEX33571964(A)
11 #SSEK2: [3, 1, 0]; scan_type(ASC), INDEX33571964(table1 as A), scan_range[DMTEMPVIEW_22201592.colname,DMTEMPVIEW_22201592.colname]
12 #PRJT2: [33, 1162, 48]; exp_num(2), is_atom(FALSE)
13 #HAGR2: [33, 1162, 48]; grp_num(1), sfun_num(1); slave_empty(0) keys(DZZ.col11)
14 #HASH RIGHT JOIN2: [25, 116278, 48]; key_num(1), ret_null(0), KEY(DZZ.col1=DY.col1)
15 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as DZZ)
16 #SSCN: [13, 116278, 48]; IDX_DYJBXX_ORGID(table3 as DY)
17 #SPL2: [9, 9876, 740]; key_num(2), spool_num(3), is_atom(FALSE), has_variable(0)
18 #PRJT2: [9, 9876, 740]; exp_num(2), is_atom(FALSE)
19 #HASH RIGHT SEMI JOIN2: [9, 9876, 740]; n_keys(1) KEY(DMTEMPVIEW_22201597.colname=A.col1) KEY_NULL_EQU(0)
20 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
21 #HASH2 INNER JOIN: [9, 9876, 740]; LKEY_UNIQUE KEY_NUM(1); KEY(B.col1=A.col2) KEY_NULL_EQU(0)
22 #CSCN2: [1, 12345, 96]; INDEX33571530(table1 as B)
23 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
24 #SPL2: [5, 11618, 740]; key_num(2), spool_num(2), is_atom(FALSE), has_variable(0)
25 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
26 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201598.colname=A.col1) KEY_NULL_EQU(0)
27 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
28 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col22) KEY_NULL_EQU(0)
29 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb3',min),('zb3',max))
30 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
31 #SPL2: [5, 11618, 740]; key_num(2), spool_num(1), is_atom(FALSE), has_variable(0)
32 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
33 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201599.colname=A.col1) KEY_NULL_EQU(0)
34 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
35 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col21) KEY_NULL_EQU(0)
36 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb2',min),('zb2',max))
37 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
38 #SPL2: [5, 11618, 740]; key_num(2), spool_num(0), is_atom(FALSE), has_variable(0)
39 #PRJT2: [5, 11618, 740]; exp_num(2), is_atom(FALSE)
40 #HASH RIGHT SEMI JOIN2: [5, 11618, 740]; n_keys(1) KEY(DMTEMPVIEW_22201600.colname=A.col1) KEY_NULL_EQU(0)
41 #CONST VALUE LIST: [1, 600, 48]; row_num(600), col_num(1),
42 #HASH2 INNER JOIN: [5, 11618, 740]; KEY_NUM(1); KEY(B.col1=A.col20) KEY_NULL_EQU(0)
43 #SSEK2: [1, 120, 96]; scan_type(ASC), INDEX33572004(table2 as B), scan_range[('zb1',min),('zb1',max))
44 #CSCN2: [2, 12345, 644]; INDEX33571530(table1 as A)
2.3、 总结
像这种用 like 做关联很明显是业务涉及不规范,不符合三范式要求。
在业务设计初期,尽量满足好三范式设计,后续才能少点用 like 这种模糊态的查询操作。
业务允许的情况下,尽量使用 = 精确匹配来代替like。
DM SQL关联列 like 优化案例的更多相关文章
- SQL 优化案例 1
create or replace procedure SP_GET_NEWEST_CAPTCHA( v_ACCOUNT_ID in VARCHAR2, --接收短信的手机号 v_Tail_num i ...
- SQL 优化案例
create or replace procedure SP_GET_NEWEST_CAPTCHA( v_ACCOUNT_ID in VARCHAR2, --接收短信的手机号 v_Tail_num i ...
- SQL Server标量函数改写内联表值函数优化案例
问题SQL: SELECT TOP 1001 ha.HuntApplicationID , ha.PartyNumber , mht.Name AS MasterHuntTypeName , htly ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- 学习SQL关联查询
通过一个小问题来学习SQL关联查询 原话题: 是关于一个left join的,没有技术难度,但不想清楚不一定能回答出正确答案来: TabA表有三个字段Id,Col1,Col2 且里面有一条数据1,1, ...
- Hive优化案例
1.Hadoop计算框架的特点 数据量大不是问题,数据倾斜是个问题. jobs数比较多的作业效率相对比较低,比如即使有几百万的表,如果多次关联多次汇总,产生十几个jobs,耗时很长.原因是map re ...
- SQL业务审核与优化
审核 什么是业务审核 类似与code review 评审业务Schema和SQL设计 偏重关注性能 是业务优化的主要入口之一 审核提前发现问题,进行优化 上 ...
- 数据库优化案例——————某市中心医院HIS系统
记得在自己学习数据库知识的时候特别喜欢看案例,因为优化的手段是容易掌握的,但是整体的优化思想是很难学会的.这也是为什么自己特别喜欢看案例,今天也开始分享自己做的优化案例. 最近一直很忙,博客产出也少的 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- mysql如何执行关联查询与优化
mysql如何执行关联查询与优化 一.前言 在数据库中执行查询(select)在我们工作中是非常常见的,工作中离不开CRUD,在执行查询(select)时,多表关联也非常常见,我们用的也比较多,那么m ...
随机推荐
- Nuxt.js 应用中的 render:response 事件钩子
title: Nuxt.js 应用中的 render:response 事件钩子 date: 2024/11/29 updated: 2024/11/29 author: cmdragon excer ...
- 【处理元组有关的题型的技巧】codeforces 1677 A. Tokitsukaze and Strange Inequality
题意 第一行输入一个正整数 \(T(1 \leq T \leq 1000)\),代表共有 \(T\) 组测试用例,对于每组测试用例: 第一行输入一个正整数 \(n(4 \leq n \leq 5000 ...
- ABAP开发规范V1.0
1. 概要 1.1目的 该文档定义了在开发与维护ABAP程序过程中必须遵守的规范与标准.该文档应当被视为一个动态的文档,该文档会根据需要进行增补和修订. 开发规范的重要作用在于保持整个开发团队的开发风 ...
- cas5开启Restful接口验证
POM文件中加入rest依赖: <!-- Restful support --> <dependency> <groupId>org.apereo.cas< ...
- Shiro简单入门+个人理解(2)
今天开始了Shiro认证及授权的部分,认证及授权是Shiro的主要功能,虽然Shiro还具有加密等功能,但在实际开发时,很少会使用到,在公司一般都有自己的一套加密方式,具体我就不说话了,毕竟有保密协议 ...
- LocalLLaMA 客户端试验
LM Studio. 可以直接下 hg 模型(实际使用需要自己修改成中国镜像). 有 local server, 符合 openai api 规范. 遗憾的是不支持选择显卡导致无法使用. Farada ...
- 【C#】【平时作业】习题-11-ADO.NET
选择题 1.下列ASP.NET语句(B)正确地创建了一个与mySQL数据库和服务器的连接. A.SqlConnection con1 = new Connection("Data Sourc ...
- 配置 HTTP/HTTPS 网络代理
使用Docker的过程中,因为网络原因,通常需要使用 HTTP/HTTPS 代理来加速镜像拉取.构建和使用.下面是常见的三种场景. 为 dockerd 设置网络代理 "docker pu ...
- Qt音视频开发30-Onvif事件订阅
一.前言 能够接收摄像机的报警事件,比如几乎所有的摄像机后面会增加报警输入输出接口,如果用户外接了报警输入,则当触发报警以后,对应的事件也会通过onvif传出去,这样就相当于兼容了所有onvif摄像机 ...
- MySQL数据库驱动mysql-connector-java与数据库版本的匹配
jar包的下载地址:https://dev.mysql.com/downloads/file/?id=477058 之前我的MySQL数据库驱动mysql-connector-java版本号为5.1. ...