HBase集群快速部署摘要
HBase快速部署摘要
相关软件版本
系统:CentOS-7-1810
JDK:7u79
Hadoop:2.7.2
ZooKeeper:3.4.10
HBase:1.3.3
静态IP
位置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容
BOOTPROTO=static
ONBOOT=yes
DNS1=192.168.56.1
GATEWAY=192.168.56.1
IPADDR=192.168.56.101
BOOTPROTO:IP获取方式,ONBOOT:是否启用,DNS1:网关IP,GATEWAY:网关IP,IPADDR:本机IP
重启服务
service network restart
查看IP
ip addr
防火墙
临时关闭
systemctl stop firewalld
查看状态
systemctl status firewalld
永久关闭
systemctl disable firewalld
查看状态
systemctl list-unit-files | grep firewalld
一般使用临时关闭+永久关闭
主机名
查看
hostname
临时修改
hostname slave0
永久修改
vi /etc/hostname
/etc/hostname中单存一个主机名,一般使用临时关闭+永久关闭
域名解析
文件
vi /etc/hosts
追加
192.168.25.10 slave0
192.168.25.11 slave1
192.168.25.12 slave2
格式:IP(空格)域名
免密登录
生成秘钥
ssh-keygen -t rsa
试验(配置免密登录自己)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
分发到要免密登录的虚拟机上
scp ~/.ssh/id_rsa.pub slave1:~
scp ~/.ssh/id_rsa.pub slave2:~
要免密登录的虚拟机将公钥追加到authorized_keys 文件中
mkdir .ssh
cd .ssh
touch authorized_keys
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
是生成秘钥的主机能免密登录到接收公钥的主机上
SSH免DNS验证
配置文件
vi /etc/ssh/sshd_config
将UseDNS设置为no,并取消注释
重启SSH服务
service sshd restart
时间同步
安装ntpdate
yum install -y ntpdate
同步时间
ntpdate -u ntp.aliyun.com
设置定时任务
查看路径
which ntpdate
文件
vi /etc/crontab
定时任务配置,10分钟同步一次(追加)
*/10 * * * * root /usr/sbin/ntpdate -u ntp.aliyun.com
禁用邮件提醒
文件
vi /etc/profile
配置(追加)
unset MAILCHECK
更新
source /etc/profile
不用./直接执行程序
文件
vi /etc/profile
配置(追加)
# 文件可以直接执行
export PATH=.:$PATH
更新
source /etc/profile
Java
创建目录/opt/software和/opt/module
mkdir -p /opt/software
mkdir -p /opt/module
上传安装包到/opt/software
解压
tar -zxvf jdk-7u79-linux-x64.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
更新
source /etc/profile
验证
java -version
Hadoop
规划
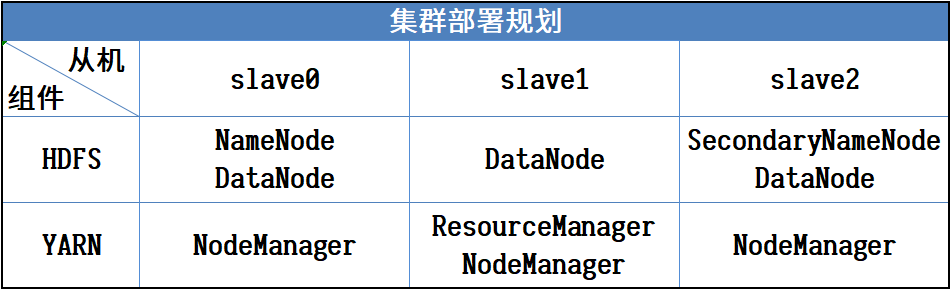
上传安装包到/opt/software
解压
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
更新
source /etc/profile
配置文件
配置目录:安装目录/etc/hadoop/
hadoop-env.sh(末尾插入)
yarn-env.sh(前面插入)
mapred-env.sh(前面插入)
export JAVA_HOME=/opt/module/jdk1.7.0_79
core-site.xml
<configuration>
<!-- 指定HDFS中NameNode进程所在的节点信息 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave0:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定HDFS文件副本数量(集群中有3个从节点,默认为3) -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定HDFS中SecondaryNameNode进程所在的节点信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 设置Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager进程所在的节点信息 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
</configuration>
mapred-site.xml
复制
cat mapred-site.xml.template >> mapred-site.xml
配置
<configuration>
<!-- 指定MapReduce运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
分发运行
分发
scp -rq /opt/module/hadoop-2.7.2/ slave1:/opt/module/
scp -rq /opt/module/hadoop-2.7.2/ slave2:/opt/module/
格式化(第一次)
bin/hdfs namenode -format
启动
slave0 : HDFS
sbin/start-dfs.sh
slave1 : YARN
sbin/start-yarn.sh
停止
slave1 : YARN
sbin/stop-yarn.sh
slave0 : HDFS
sbin/stop-dfs.sh
ZooKeeper
上传安装包到/opt/software
解压
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
更新
source /etc/profile
创建文件夹
在/opt/module/zookeeper-3.4.10/目录下创建data/zkData目录
mkdir -p data/zkData
配置文件
在安装目录/conf文件夹下
复制模板文件
cat zoo_sample.cfg >> zoo.cfg
zoo.cfg
修改
dataDir=/opt/module/zookeeper-3.4.10/data/zkData
在末尾追加
# 集群
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
在/opt/module/zookeeper-3.4.10/data/zkData/目录下创建myid文件
cd /opt/module/zookeeper-3.4.10/data/zkData/
touch myid
分发运行
分发时修改/opt/module/zookeeper-3.4.10/data/zkData/目录下的myid文件,就一个编号,分别与zoo.cfg中追加的内容对应,比如:slave0的myid内容就是1,slave1的myid内容就是2
vi /opt/module/zookeeper-3.4.10/data/zkData/myid
分发
scp -rq /opt/module/zookeeper-3.4.10/ slave1:/opt/module/
scp -rq /opt/module/zookeeper-3.4.10/ slave2:/opt/module/
运行
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh start
停止
分别在三台虚拟机上ZooKeeper的安装目录里执行
bin/zkServer.sh stop
HBase
上传安装包到/opt/software
解压
tar -zvxf hbase-1.3.3-bin.tar.gz -C /opt/module/
环境变量/etc/profile(追加)
# HBASE_HOME
export HBASE_HOME=/opt/module/hbase-1.3.3
export PATH=$PATH:$HBASE_HOME/bin
更新
source /etc/profile
配置
跳转到/opt/module/hbase-1.3.3/conf/目录
cd /opt/module/hbase-1.3.3/conf/
hbase-env.sh(前面插入)
# JDK路径
export JAVA_HOME=/opt/module/jdk1.7.0_79
# 设置使用外置的ZooKeeper
export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<!-- 设置最大时钟偏移,以降低对时间同步的要求 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 指定HDFS实例地址 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://slave0:9000/hbase</value>
</property>
<!-- 启用分布式集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper集群节点 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave0,slave1,slave2</value>
</property>
<!-- ZooKeeper配置:设置ZooKeeper数据目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/data/zkData</value>
</property>
</configuration>
regionservers 文件(添加集群的所有主机的域名)
slave0
slave1
slave2
复制Hadoop的core-site.xml和hdfs-site.xml到HBase的conf目录下
cp /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase-1.3.3/conf/
cp /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.3.3/conf/
分发和运行
分发
scp -rq /opt/module/hbase-1.3.3/ slave1:/opt/module/
scp -rq /opt/module/hbase-1.3.3/ slave2:/opt/module/
运行(在NameNode节点主机上,slave0,HBase安装目录下)
bin/start-hbase.sh
停止
bin/stop-hbase.sh
HBase集群快速部署摘要的更多相关文章
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- 在 Kubernetes 集群快速部署 KubeSphere 容器平台
KubeSphere 不仅支持部署在 Linux 之上,还支持在已有 Kubernetes 集群之上部署 KubeSphere,自动纳管 Kubernetes 集群的已有资源与容器. 前提条件 Kub ...
- ceph 集群快速部署
1.三台Centos7的主机 [root@ceph-1 ~]# cat /etc/redhat-release CentOS Linux release 7.2.1511 (Core) 2.主机 ...
- HBase单机和集群版部署
1. HBase安装部署 HBase有两种部署模式:单机版模式和集群版模式.无论哪种模式,都需要配置HBase conf目录下的文件.至少,必须在conf/hbase-env.sh文件中添加JAVA_ ...
- Hbase集群部署及shell操作
本文详述了Hbase集群的部署. 集群部署 1.将安装包上传到集群并解压 scp hbase-0.99.2-bin.tar.gz mini1:/root/apps/ tar -zxvf hbase-0 ...
- 使用 Ansible 快速部署 HBase 集群
背景 出于数据安全的考虑,自研了一个低成本的时序数据存储系统,用于存储历史行情数据. 系统借鉴了 InfluxDB 的列存与压缩策略,并基于 HBase 实现了海量存储能力. 由于运维同事缺乏 Had ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- Kubernetes+Flannel 环境中部署HBase集群
2015-12-14注:加入新节点不更改运行节点参数需求已满足,将在后续文章中陆续总结. 注:目前方案不满足加入新节点(master节点或regionserver节点)而不更改已运行节点的参数的需求, ...
- 基于docker快速搭建hbase集群
一.概述 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就像Bigt ...
随机推荐
- Solution -「洛谷 P8477」 「GLR-R3」春分 下界证明?!
前情提要:在「洛谷 P8477」 「GLR-R3」春分中,我们给出了 \(\frac{7}{6}n\pm\mathcal O(1)\) 的解法,但没能给出相关的下界证明.现在我们尝试给出一个未完全 ...
- CDS标准视图:催款范围描述 I_DunningAreaText
视图名称:催款范围描述 I_DunningAreaText 视图类型: 视图代码: 点击查看代码 @EndUserText.label: 'Dunning Area - Text' @Analytic ...
- JS 实现在指定的时间点播放列表中的视频
为了实现在指定的时间点播放列表中的视频,你可以使用JavaScript中的setTimeout或setInterval结合HTML5的<video>元素.但是,由于你需要处理多个时间点,并 ...
- Kubernetes kubeadm部署k8s集群
kubeadm是Kubernetes项目自带的及集群构建工具,负责执行构建一个最小化的可用集群以及将其启动等的必要基本步骤,kubeadm是Kubernetes集 ...
- 第五章 dubbo源码解析目录
第十章 dubbo线程模型 一 netty的线程模型 在netty中存在两种线程:boss线程和worker线程. 1 boss线程 作用: accept客户端的连接: 将接收到的连接注册到一个wor ...
- 安装Docker及相关容器
一,Docker简介百科说:Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化,容器是完全使用沙箱 ...
- 原生JS实现一个日期选择器(DatePicker)组件
这是通过原生HTML/CSS/JavaScript完成一个日期选择器(datepicker)组件,一个纯手搓的组件的开发.主要包括datepicker静态结构的编写.日历数据的计划获取.组件的渲染以及 ...
- JMeter的CLI模式(非GUI模式)常用命令
JMeter的CLI模式(非GUI模式)常用命令 Apache JMeter是一款强大的开源性能测试工具,它支持图形用户界面(GUI)模式和非图形用户界面(CLI,即Command Line Inte ...
- Huggingface使用
目录 1. Transformer模型 1.1 核心组件 1.2 模型结构 1.3 Transformer 使用 1.3.1 使用 Hugging Face Transformers 库 1.3.2 ...
- Net跨平台硬件信息查询库 Hardware.Info:全面获取系统硬件详情
Hardware.Info 是一个基于 .NET Standard 2.0 的跨平台库,提供了硬件信息查询的功能,支持 Windows.Linux 和 macOS 操作系统.该库通过不同平台下的系统接 ...