Spark Java API 之 CountVectorizer
Spark Java API 之 CountVectorizer
由于在Spark中文本处理与分析的一些机器学习算法的输入并不是文本数据,而是数值型向量。因此,需要进行转换。而将文本数据转换成数值型的向量有很多种方法,CountVectorizer是其中之一。
A CountVectorizer converts a collection of text documents into a vector representing the word count of text documents.
在构建向量时,有两个重要的参数:VocabSize和MinDF。前者表示词典的大小,后者表示当文档中某个Term出现的次数小于MinDF时,则不计入词典(该Term不属于词典中的 单词)。
比如说现在有两篇文档:【"w1", "w2", "w4", "w5", "w2"】,【"w1", "w2", "w3"】
CountVectorizer cv = new CountVectorizer().setInputCol("text").setOutputCol("feature")
.setVocabSize(3).setMinDF(2);
根据上面代码中的参数设置,词典大小为3,即一共可以有三个Term。由于在所有的文档中,"w1"出现2次,"w2"出现2次,因此计入词典。而"w3"、"w4"、"w5"只出现一次,不属于词典中的单词(Term)。如下图所示:词典中只有两个Term
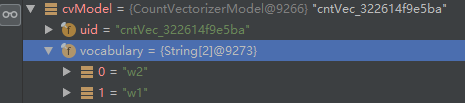
When the dictionary is not defined CountVectorizer iterates over the dataset twice to prepare
the dictionary based on frequency and size.
CountVectorizer 首先扫描Dataset(文本数据)生成词典,然后再次扫描生成向量模型(CountVectorizerModel)
在构造Dataset 时,需要指定模式。用模式来解释Dataset中每一行的数据。
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())
});
A field inside a StructType. param: name The name of this field. param: dataType The data type of this field. param: nullable Indicates if values of this field can be
nullvalues. param: metadata The metadata of this field. The metadata should be preserved during transformation if the content of the column is not modified
第一个参数是:名称;第二个参数是dataType 数据类型;第三个参数是标识该字段的值是否可以为空;第四个参数为字段的元数据信息。
整个示例代码:
import org.apache.spark.ml.feature.CountVectorizer;
import org.apache.spark.ml.feature.CountVectorizerModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import java.util.Arrays;
import java.util.List;
public class CounterVectorExample {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("CountVectorizer").master("spark://172.25.129.170:7077").getOrCreate();
List<Row> data = Arrays.asList(
// RowFactory.create(Arrays.asList("a", "b", "c")),
// RowFactory.create(Arrays.asList("a", "b", "b", "c", "a")),
// RowFactory.create(Arrays.asList("a", "b", "a", "b"))
RowFactory.create(Arrays.asList("w1", "w2", "w3")),
RowFactory.create(Arrays.asList("w1", "w2", "w4", "w5", "w2"))
);
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true), false, Metadata.empty())
});
Dataset<Row> df = spark.createDataFrame(data, schema);
CountVectorizer cv = new CountVectorizer().setInputCol("text").setOutputCol("feature")
.setVocabSize(3).setMinDF(2);
CountVectorizerModel cvModel = cv.fit(df);
//prior dictionary
CountVectorizerModel cvm = new CountVectorizerModel(new String[]{"a", "b", "c"}).setInputCol("text")
.setOutputCol("feature");
// cvm.
cvModel.transform(df).show(false);
spark.stop();
}
}
输出结果默认是以稀疏向量表示:
A sparse vector represented by an index array and a value array.
param: size size of the vector. param: indices index array, assume to be strictly increasing. param: values value array, must have the same length as the index array.
第一个字段代表:向量长度,由于这里词典中只有2个Term,因此转换出来的向量长度为2;第二个字段:索引下标;第三个字段:索引位置处相应的向量元素值。由上图中位置0处的Term是 w2,位置1处的Term是w1,因此,输出:
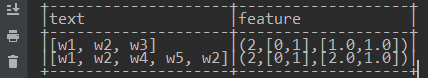
当然,我们也可以预先定义词典:在构造CountVectorizerModel的时候指定词典:【"w1", "w2", "w3"】
//prior dictionary
CountVectorizerModel cvm = new CountVectorizerModel(new String[]{"w1", "w2", "w3"}).setInputCol("text").setOutputCol("feature");
cvm.transform(df).show(false);
对于文本:[w1,w2,w3],每个Term都在词典中,且出现了一次,因此稀疏特征向量表示为:(3,[0,1,2],[1.0,1.0,1.0])。其中,3代表向量的长度为3维向量;[0,1,2]表示向量的索引;[1.0,1.0,1.0]表示,在相应的索引处,每个元素值为1.0(即各个Term只出现了一次)。而对于文本[w1, w2, w4, w5, w2],因为w4和w5不在词典中,w1出现一次,w2出现2次,故其特征如下:

可以看出:对于CountVectorizerModel,向量长度就是词典的大小。
系列文章:
原文:https://www.cnblogs.com/hapjin/p/9899164.html
Spark Java API 之 CountVectorizer的更多相关文章
- Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离 在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称.聚类分析需要一个距离,用来衡量两 ...
- 在 IntelliJ IDEA 中配置 Spark(Java API) 运行环境
1. 新建Maven项目 初始Maven项目完成后,初始的配置(pom.xml)如下: 2. 配置Maven 向项目里新建Spark Core库 <?xml version="1.0& ...
- spark (java API) 在Intellij IDEA中开发并运行
概述:Spark 程序开发,调试和运行,intellij idea开发Spark java程序. 分两部分,第一部分基于intellij idea开发Spark实例程序并在intellij IDEA中 ...
- spark java API 实现二次排序
package com.spark.sort; import java.io.Serializable; import scala.math.Ordered; public class SecondS ...
- spark java api数据分析实战
1 spark关键包 <!--spark--> <dependency> <groupId>fakepath</groupId> <artifac ...
- 【Spark Java API】broadcast、accumulator
转载自:http://www.jianshu.com/p/082ef79c63c1 broadcast 官方文档描述: Broadcast a read-only variable to the cl ...
- Spark基础与Java Api介绍
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3832405.html 一.Spark简介 1.什么是Spark 发源于AMPLab实验室的分布式内存计 ...
- 利用SparkLauncher 类以JAVA API 编程的方式提交Spark job
一.环境说明和使用软件的版本说明: hadoop-version:hadoop-2.9.0.tar.gz spark-version:spark-2.2.0-bin-hadoop2.7.tgz jav ...
- Spark:java api实现word count统计
方案一:使用reduceByKey 数据word.txt 张三 李四 王五 李四 王五 李四 王五 李四 王五 王五 李四 李四 李四 李四 李四 代码: import org.apache.spar ...
随机推荐
- HRBUST - 2069-萌萌哒十五酱的衣服~-multiset-lower_bound
众所周知,十五酱有很多的衣服,而且十五酱东西收拾的非常糟糕. 所以十五酱经常找不到合适的衣服穿,于是她觉得收拾一下屋子,把衣服配成一套一套的~(即一件衬衫一件裤子. 十五酱一共有n件衣服,有衬衫有裤子 ...
- MyBatis 学习总结 01 快速入门
本文测试源码下载地址: http://onl5wa4sd.bkt.clouddn.com/MyBatis0918.rar 一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级 ...
- split函数用法
split函数详解 split翻译为分裂. split()就是将一个字符串分裂成多个字符串组成的列表. split()当不带参数时以空格进行分割,当代参数时,以该参数进行分割. //---当不带 ...
- 在pycharm中查看内建函数源码
鼠标放在内建函数上,Ctrl+B,看源码
- Neutron :默认通过 dnsmasq 实现 DHCP 功能----Namespace
Neutron 提供 DHCP 服务的组件是 DHCP agent. DHCP agent 在网络节点运行上,默认通过 dnsmasq 实现 DHCP 功能. 配置 DHCP agent DHCP ...
- 原生Ajax XMLHttpRequest对象
一.Ajax请求 - 现在常见的前后端分离项目中,一般都是服务器返回静态页面后浏览器加载完页面,运行script中的js代码,通过ajax向后端api发送异步请求获取数据,然后调用回调函数,将数据添加 ...
- PHP 5.0~5.6 各版本兼容性的 cURL 文件上传
不同版本PHP之间cURL的区别 PHP的cURL支持通过给CURL_POSTFIELDS传递关联数组(而不是字符串)来生成multipart/form-data的POST请求. 传统上,PHP的cU ...
- windows 比较文件命令--fc
dos环境下的比较文件命令 win7帮助 D:\test>fc /? 比较两个文件或两个文件集并显示它们之间 的不同 FC [/A] [/C] [/L] [/LBn] [/N] [/OFF[LI ...
- vue.js实战——splice使用
Vue在检测到数组变化时,并不是直接重新渲染整个列表,而是最大化地复用DOM元素.替换的数组中含有相同元素的项不会被重新渲染,因此可以大胆地用新数组来替换就数组,不用担心性能问题. 需要注意的是,以下 ...
- MySQL之 InnoDB记录结构(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
以下内容来自掘金小册 MySQL 是怎样运行的:从根儿上理解 MySQL 版权归原作者所有! 页是MySQL中磁盘和内存交互的基本单位,也是MySQL是管理存储空间的基本单位. 指定和修改行格式的语法 ...