Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下:
hostname ipaddress subnet mask geteway
1、 master 192.168.146.200 255.255.255.0 192.168.146.2
2、 slave1 192.168.146.201 255.255.255.0 192.168.146.2
3、 slave2 192.168.146.202 255.255.255.0 192.168.146.2
1、下载 kafka 压缩包
官网下载地址:http://kafka.apache.org/downloads
2、搭建zookeeper集群
由于 kafka 集群的运行需要 zookeeper,所以我们要首先进行 zookeeper 集群的搭建。
关于搭建的教程,我在上一篇博客已经介绍了:https://www.cnblogs.com/ysocean/p/9860529.html
3、解压 kafka
将下载的 kafka 压缩文件上传到集群中的每台机器相应目录,执行如下命令进行解压。
tar -zxf kafka_2.12-2.0.0.tgz
4、修改配置文件 server.properties
broker.id=0
listeners=PLAINTEXT://192.168.146.200:9092
zookeeper.connect=192.168.146.200:2181,192.168.146.201:2181,192.168.146.202:2181
第一个 broker.id 后面的值和搭建 zookeeper 集群中 myid 一样,是一个集群中唯一的数,要求是正数。需要保证kafka集群中设置的都不一样。
第二个设置监听器,后面的 IP 地址对应当前的 ip 地址。
第三个是配置 zookeeper 集群的 IP 地址。
该配置文件的其余设置可以默认,具体会在后面博客进行介绍。
5、启动 kafka
/usr/local/software/kafka_2.12-2.0.0/bin/kafka-server-start.sh /usr/local/software/kafka_2.12-2.0.0/config/server.properties &
该命令虽然是后台启动服务,但是日志仍然会打印到控制台。
想要完全后台启动,执行如下命令:
/usr/local/software/kafka_2.12-2.0.0/bin/kafka-server-start.sh /usr/local/software/kafka_2.12-2.0.0/config/server.properties 1>/dev/null 2>&1 &
其中1>/dev/null 2>&1 是将命令产生的输入和错误都输入到空设备,也就是不输出的意思。/dev/null代表空设备。
执行完毕后,输入 jps ,出现 kafka 的进程,则证明启动成功。
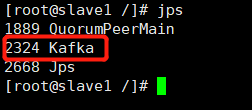
6、创建 topic
集群启动成功后,我们通过创建一个名字为 test,partitions为3,replication为3的topic。
进入到bin 目录下,执行如下命令:
./kafka-topics.sh --create --zookeeper 192.168.146.200:2181,192.168.146.201:2181,192.168.146.202:2181 --partitions 3 --replication-factor 3 --topic test
7、向 topic 发送消息
进入到 bin 目录下,执行如下命令:
./kafka-console-producer.sh --broker-list 192.168.146.200:9092,192.168.146.201:9092,192.168.146.202:9092 --topic test

输入 hello kafka ,然后 enter 键,即向名为 test 的topic 发送了一条消息:hello kafka
8、kafka 可视化工具
为了更好的看到上一步创建的 topic,以及发送的消息。这里介绍一个 kafka 可视化工具——Kafka Tools,官网下载地址:http://www.kafkatool.com/download.html
安装过程很简单,都是点击下一步即可。然后打开该工具,进行如下配置:
点击 File ---> Add cluster
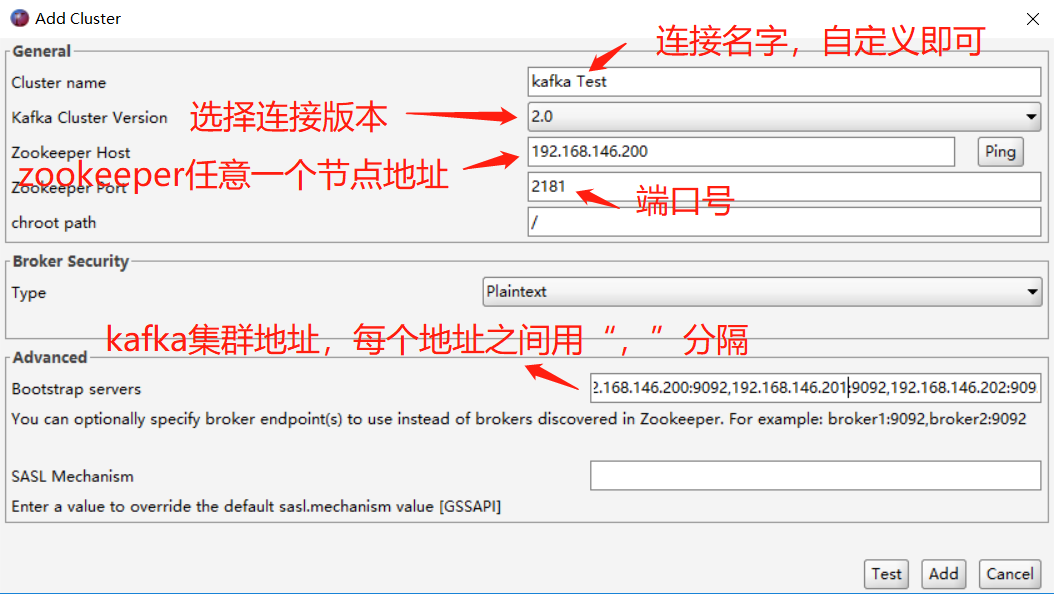
然后点击有下家的 Add 按钮即可。
点开刚刚创建的连接,出现如下界面:
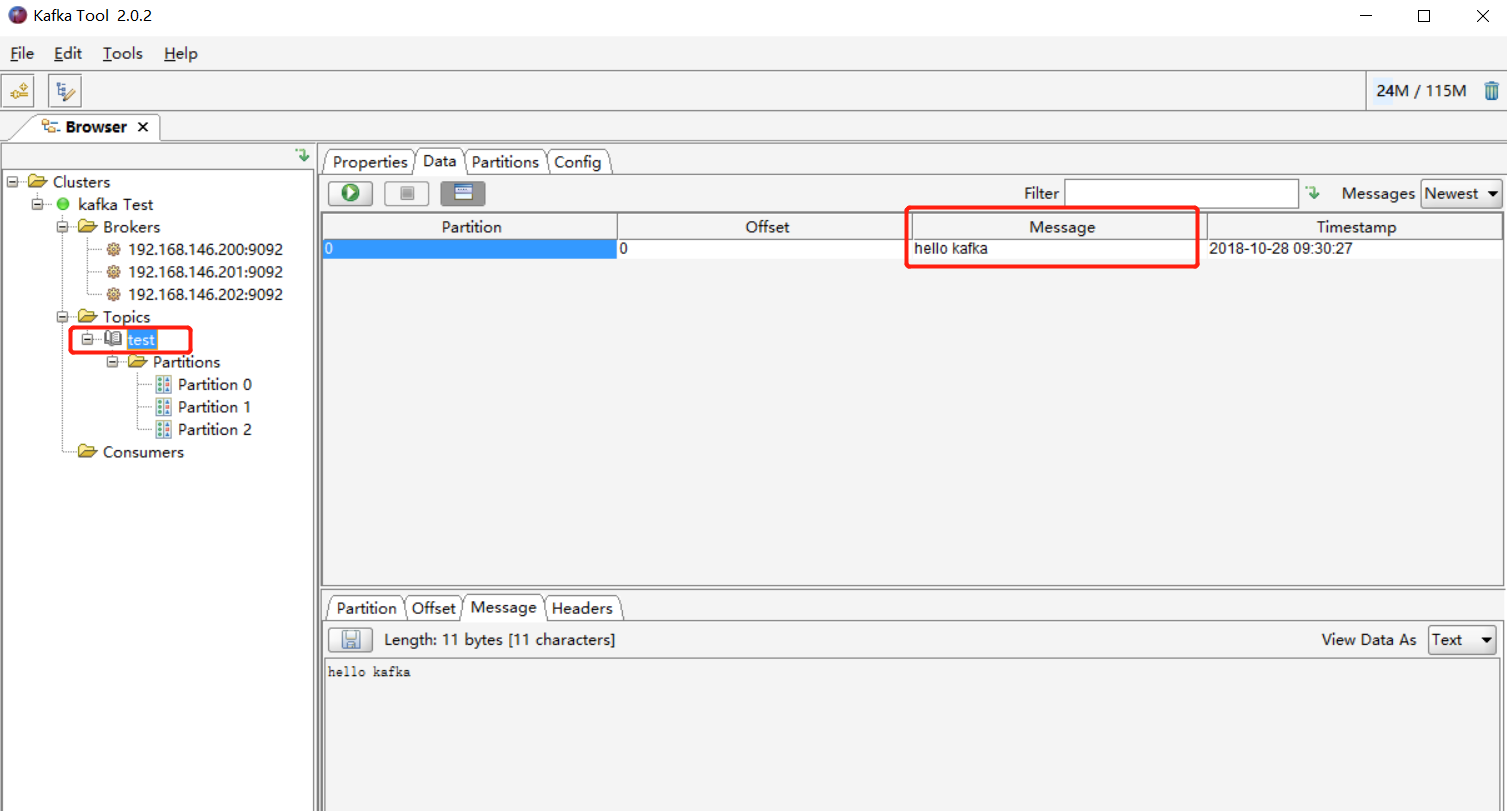
test 便是我们上一步创建的 topic 名称,里面有一条消息 hello kafka。
Kafka 详解(二)------集群搭建的更多相关文章
- elasticsearch系列三:索引详解(分词器、文档管理、路由详解(集群))
一.分词器 1. 认识分词器 1.1 Analyzer 分析器 在ES中一个Analyzer 由下面三种组件组合而成: character filter :字符过滤器,对文本进行字符过滤处理,如 ...
- Kafka详解二:如何配置Kafka集群
问题导读1.Kafka有哪几种配制方法?2.如何启动一个Consumer实例来消费消息? Kafka集群配置比较简单,为了更好的让大家理解,在这里要分别介绍下面三种配置 单节点:一个broker的集群 ...
- Nginx详解-服务器集群
Nginx是什么 代理服务器:一般是指局域网内部的机器通过代理服务器发送请求到互联网上的服务器,代理服务器一般作用在客户端.应用比如:GoAgent,FQ神器. 一个完整的代理请求过程为:客户端首先 ...
- kafka Centos7.2 单机集群搭建
前提是已经安装好了zk集群 1.下载 kafka_2.11-1.0.0.tgz 下载网址 http://kafka.apache.org/documentation.html 2.解压 tar ...
- 九、kafka伪分布式和集群搭建
伪分布式: 1.先将zk启动,如果是在伪分布式下,kafka已经集成了zk nohup /kafka_2.11-0.10.0.1/bin/zookeeper-server-start.sh /kafk ...
- Session详解及集群共享
Session的介绍 维基百科:会话(session)是一种持久网络协议,在用户(或用户代理)端和服务器端之间创建关联,从而起到交换数据包的作用机制,session在网络协议(例如telnet或FTP ...
- CynosDB技术详解——存储集群管理
本文由腾讯云数据库发表 前言 CynosDB是架构在CynosFS之上的分布式关系数据库系统,为最大化利用存储资源,平衡资源之间的竞争,检查资源使用情况,需要一套高效稳定的分布式集群管理系统(SCM: ...
- kafka详解(二)--kafka为什么快
前言 Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ.Pulsar.Kafka.RabbitMQ 等消息系统 ...
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
随机推荐
- vnc server的安装
vnc是一款使用广泛的服务器管理软件,可以实现图形化管理.我在安装vnc server碰到一些问题,也整理下我的安装步骤,希望对博友们有一些帮助. 1 安装对应的软件包 [root@centos6 ~ ...
- 设计模式总结篇系列:单例模式(SingleTon)
在Java设计模式中,单例模式相对来说算是比较简单的一种构建模式.适用的场景在于:对于定义的一个类,在整个应用程序执行期间只有唯一的一个实例对象.如Android中常见的Application对象. ...
- 痞子衡嵌入式:ARM Cortex-M文件那些事(3)- 工程文件(.ewp)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是嵌入式开发里的project文件. 前面两节课里,痞子衡分别给大家介绍了嵌入式开发中的两种典型input文件:源文件(.c/.h/.s). ...
- springboot(五)过滤器和拦截器
前言 过滤器和拦截器二者都是AOP编程思想的提现,都能实现诸如权限检查.日志记录等.二者有一定的相似之处,不同的地方在于: Filter是servlet规范,只能用在Web程序中,而拦截器是Sprin ...
- 多线程Thread,线程池ThreadPool
首先我们先增加一个公用方法DoSomethingLong(string name),这个方法下面的举例中都有可能用到 #region Private Method /// <summary> ...
- 简述ADO.NET(一)
ADO.NET 宏观定义 传统ADO主要针对紧密连接的客户端/服务器端系统,而 ADO.NET考虑到了断开连接式应用并且引进了 Dateset 它代表任意数量的关联表,其中每个表都包含了行和列的集合的 ...
- asp.net 建多个项目实现三层的实例——读取一张表中的记录条数
学习asp.net两周,通过学习发现,.net和php之间的区别还是蛮大的,比php要复杂一些,开始学习的有些吃力,后来跟着传智播客里的老师学习,渐渐的学到了一些东西. 今天要记录一下.net里的简单 ...
- 红米手机4A怎么样刷入开发版获得ROOT权限
小米的手机或平板不同手机型号一般情况官方都提供两个不同系统,可分为稳定版和开发版,稳定版没有提供root权限管理,开发版中就支持了root权限,在很多工作的时候我们需要使用的一些功能强大的app,都需 ...
- 手机Soc芯片简介
手机SoC(System On a Chip,在一个芯片里面集成CPU.GPU.SP.ISP.RAM内存.Wi-Fi控制器.基带芯片以及音频芯片等)芯片(基于arm架构指令集) 高通骁龙(Snapdr ...
- DAS、SAN和NAS三种存储方式
DAS存储 DAS存储在我们生活中是非常常见的,尤其是在中小企业应用中,DAS是最主要的应用模式,存储系统被直连到应用的服务器中,在中小企业中,许多的数据应用是必须安装在直连的DAS存储器上. DAS ...