flask(三)之Flask-SQLAlchemy
01-介绍
Flask-SQLAlchemy是一个Flask扩展,简化了在Flask应用中使用SQLAlchemy的操作。SQLAlchemy提供了高层ORM,也提供了使用数据库原生SQL的低层功能。
# 安装 pip install flask-sqlalchemy
在Flask-SQLAlchemy中,数据库使用URL指定。

应用使用的数据库URL必须保存到Flask配置对象的 SQLALCHEMY_DATABASE_URI 键中。
建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键 设为 False,以便在不需要跟踪对象变化时降低内存消耗。
02-数据库的连接
from flask import Flask
# 1.导入
from flask_sqlalchemy import SQLAlchemy app = Flask(__name__)
#2.定义要连接的数据库
DB_URI = "mysql+pymysql://root:123456@127.0.0.1:3306/learn_sqlalchemy?charset=utf8"
#3.添加到到配置中
app.config['SQLALCHEMY_DATABASE_URI'] = DB_URI
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] =False
# 4.实例化一个对象,将app传进去
db = SQLAlchemy(app) @app.route('/')
def hello_world():
return 'Hello World!' if __name__ == '__main__':
app.run()
03-定义模型
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
username = db.Column(db.String(50),nullable=False) def __repr__(self):
return self.username class Article(db.Model):
__tablename__ = "article"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), nullable=False)
uid = db.Column(db.Integer,db.ForeignKey("user.id"))
author = db.relationship("User",backref='article') def __repr__(self):
return self.title
__tablename__ 定义在数据库中的表名。


04-一对多的关系
例:一个角色对应多个用户:
class Role(db.Model):
# ...
users = db.relationship('User', backref='role') class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
db.relationship()中的第一个参数指的是这个关系的另一端是哪个模型,backref参数向User模型添加一个role属性,从而定义反向关系。

05-操作
# 创建表
db.create_all() # 删除表
db.drop_all() # 插入行
admin_role = Role(name='admin')
user_role= User(username='hyp', role=admin_role) # 对数据库的改动童年过数据库会话管理,在Flask-SQLAlchemy中,会话由 db.session 表示。在写入数据库之前,要先添加到会话中:
db.session.add(admin_role)
db.session.add(user_role)
# 或者
db.session.add_all([admin_role, user_role]) # 为了写入数据库,要调用 commit()方法提交会话:
db.session.commit() # 数据库回话能保证数据库的一致性。数据库回话也可以回滚,调用 db.session.rollback() # 修改行
admin_role.name= 'lcy'
db.session.add(admin_role)
db.session.commit() # 删除行
db.session.delete(admin_role)
db.session.commit() # 注意:删除、更新和插入一样,提交数据会话才执行。 # 查询行
# 每个模型类都提供了query对象。
Role.query.all()
Role.query.filter_by(role=user_role).all() # 查看生成的原生SQL查询语句,只需要把query对象转换成字符串:
str(User.query.filter_by(role=user_role)) # first()方法 只返回第一个结果
user_role = Role.query.filter_by(name='User').first()


06-集成Python Shell
若想把对象添加到入列表中,必须使用 app.shell_context_processor 装饰器创建并注册一个shell上下文处理器。
@app.shell_context_processor
def make_shell_context():
return dict(db=db, User=User, Role=Role)
这个shell上下文处理器函数返回一个字典,包含数据库实例和模型。
07-使用 Flask-Migrate实现数据库迁移
Flask应用还可以使用Flask-Migrate扩展,是对Alembic的轻量级包装。
# 安装 pip install flask-migrate
manage.py
from flask_script import Manager
from flask_migrate_demo import app
from exts import db
import models #这个一定要导入
from flask_migrate import Migrate,MigrateCommand manager = Manager(app)
Migrate(app,db)
manager.add_command("db",MigrateCommand) #把所有命令放到db里面 if __name__ == '__main__':
manager.run()
初始化
python manage.py db init
创建迁移脚本
python manage.py db migrate -m '第一次提交'
生成到数据库
python manage.py db upgrade
08-alembic数据迁移工具
alembic是用来做ORM模型与数据库的迁移与映射。alembic使用方式跟git有点类似,表现在两个方面,第一个,alemibi的所有命令都是以alembic开头;
第二,alembic的迁移文件也是通过版本进行控制的。
# 安装 pip install alembic
使用:
# model.py from sqlalchemy import Column,Integer,String,create_engine
from sqlalchemy.ext.declarative import declarative_base DB_URI = "mysql+pymysql://root:123456@127.0.0.1:3306/alembic_demo?charset=utf8" engine = create_engine(DB_URI) Base = declarative_base(engine) class User(Base):
__tablename__ = 'user'
id = Column(Integer,primary_key=True,autoincrement=True)
username = Column(String(50),nullable=False)
在终端初始化,创建一个仓库
alembic init learn_alembic
修改配置文件,指定连接的数据库
# alembic.ini sqlalchemy.url = mysql+pymysql://root:123456@127.0.0.1:3306/alembic_demo?charset=utf8
将models所在的目录路径添加到env.py,并指定target_metadata
import sys,os
# 1.__file__:当前文件(env.py)
#2.os.path.dirname(__file__):获取当前文件的目录
#3.os.path.dirname(os.path.dirname(__file__)):获取当前文件目录的上一级目录
#4.sys.path: python寻找导入的包的所有路径
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
import models target_metadata = models.Base.metadata
生成迁移脚本
alembic revision --autogenerate -m "第一次提交"
将生成的迁移脚本映射到数据库中
alembic upgrade head
以后如果想要添加或修改模型,重复最后两步即可。
常用命令:
init:创建一个alembic仓库
rebision:创建一个新的版本文件
--autogenerate:自动将当前模型的修改,生成迁移脚本
-m:本次迁移做了哪些修改
upgrade:将指定版本的迁移文件映射到数据库中,会执行版本文件中的upgrade函数
head:代表当前的迁移脚本的版本号
downgrade:会执行指定版本的迁移文件中的downgrade函数
heads:展示当前可用的heads脚本文件
history:列出所有的迁移版本及其信息
current:展示当前数据库中的版本号
经典错误 1.FAILED:Target databases is not up to date. 原因:主要是heads和current不相同。current落后于heads的版本 解决办法:将current移动到head上。alembic upgrade head 2.FAILED:Can't locate revision identified by 'xxxxxxx' 原因:数据库中存的版本号不在迁移脚本文件中 解决办法:删除数据的alembic_version表中的数据,重新执行alembic upgrade head
用alembic工具:数据库中会自动生成一张表alembic_version
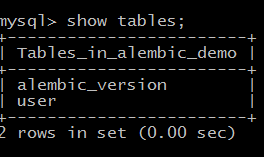
在数据库中可以查看当前的版本号
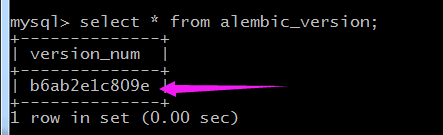
在cmd终端也可以通过current命令查看
alembic current
Flask-SQLAlchemy下使用alembic:
1. config.py
DB_URI = "mysql+pymysql://root:123456@127.0.0.1:3306/flask_alembic_demo?charset=utf8" SQLALCHEMY_DATABASE_URI = DB_URI
(2)flask_alembic_demo.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import config app = Flask(__name__)
app.config.from_object(config) db = SQLAlchemy(app) class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
username = db.Column(db.String(50),nullable=False) @app.route('/')
def hello_world():
return 'Hello World!' if __name__ == '__main__':
app.run()
(3)初始化
alembic init alembic
(4)alembic.ini
sqlalchemy.url = mysql+pymysql://root:123456@127.0.0.1:3306/flask_alembic_demo?charset=utf8
(5)env.py
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
import flask_alembic_demo # 用的是db.Model
target_metadata = flask_alembic_demo.db.Model.metadata
(6)生成迁移脚本
alembic revision --autogenerate -m "first commit"
(7)upgrade到数据库
alembic upgrade head
(8)添加字段
假入想添加一个字段age
class User(db.Model):
__tablename__ = 'user'
id = db.Column(db.Integer,primary_key=True,autoincrement=True)
username = db.Column(db.String(50),nullable=False)
age = db.Column(db.Integer)
重复步骤即可
alembic revision --autogenerate -m "add column age" alembic upgrade head
flask(三)之Flask-SQLAlchemy的更多相关文章
- python 全栈开发,Day142(flask标准目录结构, flask使用SQLAlchemy,flask离线脚本,flask多app应用,flask-script,flask-migrate,pipreqs)
昨日内容回顾 1. 简述flask上下文管理 - threading.local - 偏函数 - 栈 2. 原生SQL和ORM有什么优缺点? 开发效率: ORM > 原生SQL 执行效率: 原生 ...
- flask系列四之SQLAlchemy
一.SQLAlchemy简介 (1)flask_sqlalchemy是一套ORM框架. (2)ORM(Object Relationship Mapping):模型关系映射 (3)ORM的好处:可以让 ...
- 第三篇 Flask 中的 request
第三篇 Flask 中的 request 每个框架中都有处理请求的机制(request),但是每个框架的处理方式和机制是不同的 为了了解Flask的request中都有什么东西,首先我们要写一个前 ...
- flask插件系列之SQLAlchemy基础使用
sqlalchemy是一个操作关系型数据库的ORM工具.下面研究一下单独使用和其在flask框架中的使用方法. 直接使用sqlalchemy操作数据库 安装sqlalchemy pip install ...
- flask的orm框架(SQLAlchemy)-操作数据
# 原创,转载请留言联系 Flask-SQLAlchemy 实现增加数据 用 sqlalchemy 添加数据时,一定要注意,不仅仅要连接到数据表,并且你的创建表的类也必须写进来.而且字段和约束条件要吻 ...
- flask的orm框架(SQLAlchemy)-创建表
# 转载请留言联系 ORM 是什么? ORM,Object-Relation Mapping.意思就是对象-关系映射.ORM 主要实现模型对象到关系数据库数据的映射. 优点 : 只需要面向对象编程, ...
- flask(三)
1.cbv的用法 from flask import Flask,views app = Flask(__name__) class Login(views.MethodView ): def get ...
- Flask01 初识flask、创建flask应用、flask启动配置
1 什么是flask Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 . 百度百科:点击前往 中文文档: ...
- flask第一章 flask启动 路由视图 FlaskRequest jinja2 FlaskSession
一.简单了解flask web框架 优点: 小而精,组件只有session,第三方机构强烈支持flask,极其简单 缺点: 由于第三方软件的关系,稳定性相对较差,flask-session 扩展知识: ...
随机推荐
- Perl系列文章
0.Perl书籍推荐 Perl书籍下载 密码:kkqx 下面是一些我学习Perl过程中读过完整的或部分章节的觉得好的书. 入门级别1:<Perl语言入门>即小骆驼 入门级别2:<In ...
- .NET Core[MVC] 利用特性捕捉异常
声明:本方式适用于MVC.本代码只适用于.NET Core MVC. 先创建一个类继承ExceptionFilterAttribute这个抽象类,并override它的方法OnException. 代 ...
- Linux学习笔记之MySql的安装(CentOS)
一.移除mariadb 由于CentOS默认安装了mariadb,所以在安装MySql之前先移除mariadb,使用命令:yum remove mariadb-libs.x86_64,如下图所示: 二 ...
- mybatis_16逆向工程
简介 简单点说,就是通过数据库中的单表,自动生成java代码. Mybatis官方提供了逆向工程 可以针对单表自动生成mybatis代码(mapper.java\mapper.xml\po类) 企业开 ...
- Android项目刮刮奖详解(二)
Android项目刮刮奖详解(一) 前言 上期我们简单地实现了一个画板的功能,用户可以在上面乱写乱画,其实,刮刮奖也是如此,用户刮奖的时候也是乱写乱画的. 刮刮奖原理 一共有两层画布,底层画布存放中奖 ...
- Activiti(二) springBoot2集成activiti,集成activiti在线设计器
摘要 本篇随笔主要记录springBoot2集成activiti流程引擎,并且嵌入activiti的在线设计器,可以通过浏览器直接编辑出我们需要的流程,不需要通过eclipse或者IDEA的actiB ...
- Adaptive Placeholders
https://wisdmlabs.com/blog/create-adaptive-placeholders-using-css/ https://circleci.com/blog/adaptiv ...
- Node的简介
从开始学习node到现在已经有半年多了,中间没有做过什么实际工作中的项目,所以感觉自己的知识有些匮乏,但是我还是要写这些文章,因为工作中的需要用node来开发后台环境,再加上我对这些知识记得不多,都是 ...
- Vue一个案例引发「内容分发slot」的最全总结
今天我们继续来说说 Vue,目前一直在自学 Vue 然后也开始做一个项目实战,我一直认为在实战中去发现问题然后解决问题的学习方式是最好的,所以我在学习一些 Vue 的理论之后,就开始自己利用业余时间做 ...
- mssql sqlserver 指定特定值排在表前面
转自:http://www.maomao365.com/?p=7141 摘要: 下文讲述sql脚本编写中,将 特定值排在最前面的方法分享, 实验环境:sqlserver 2008 R2 例:将数据表中 ...