Python爬虫之12306-分析请求总概述
python爬虫也学了一段时间了。也爬过不少网站,最后我想用12306抢票器这个项目做一个对之前的学习的效果成见也是一个目标(开始学爬虫的时候,看到说,会爬12306,就会爬80%的网站),本人纯自学。可以弯路走了不少,爬的网站也没有什么实质的价值(不是老师的作业,也不是老板的需求,就是自己的练习),所以嘛,不是有句话说的,人活着,就是为了搞事情。
12306,真的是特别厉害的反爬,请求太难分析了。一些隐藏的参数,被转码的参数。不过分析成功后,你真的会感觉别的网站也就那么回事。
----------------------------登陆
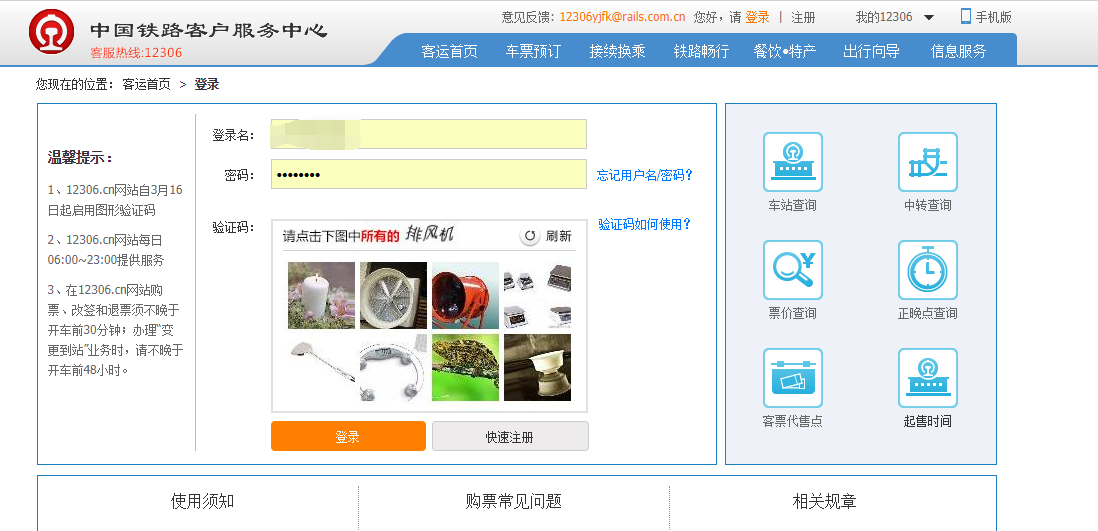
来到登陆页面。有验证码和登陆框。--登陆成功后就跳转了,用Mozilla Firefox浏览器也可以看到跳转以前的请求,但是我的Mozilla Firefox有BUG 别的都可以就是登陆不行。
先看看验证码,点击刷新验证码

链接找到了
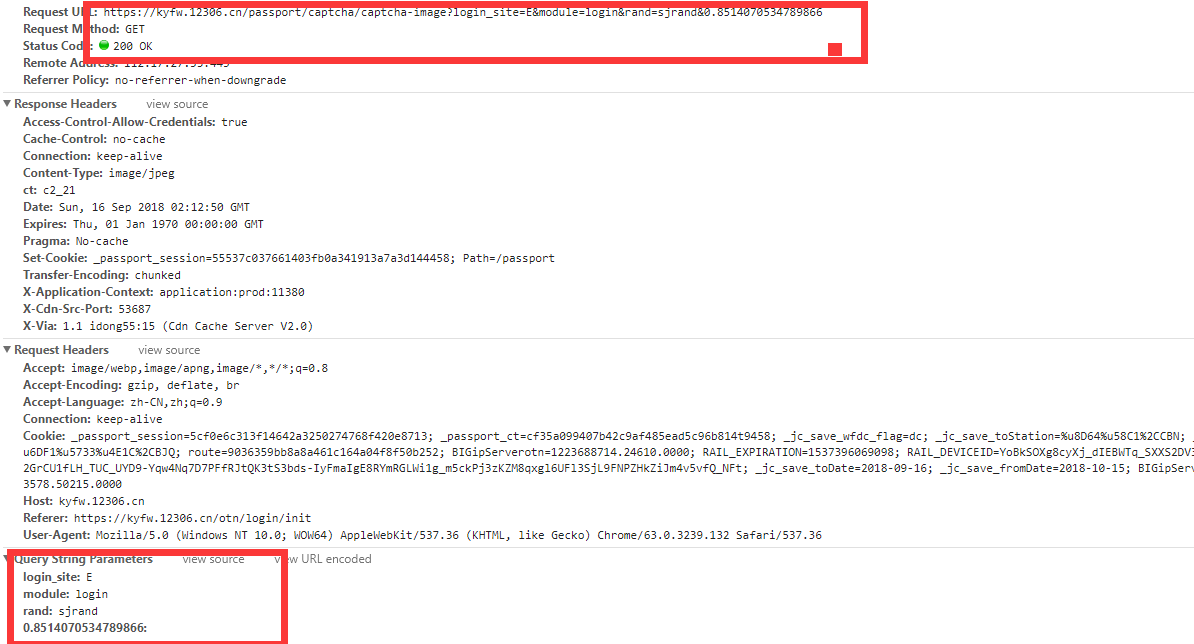
下面4个参数呢 前面3个事固定的也不懂代表什么意思。就看到一个 login 我想可能是代表登陆的验证码吧。第4个是个随机数。可是我反复刷新后,觉得不带那个也可以。没难度‘
验证码验证:
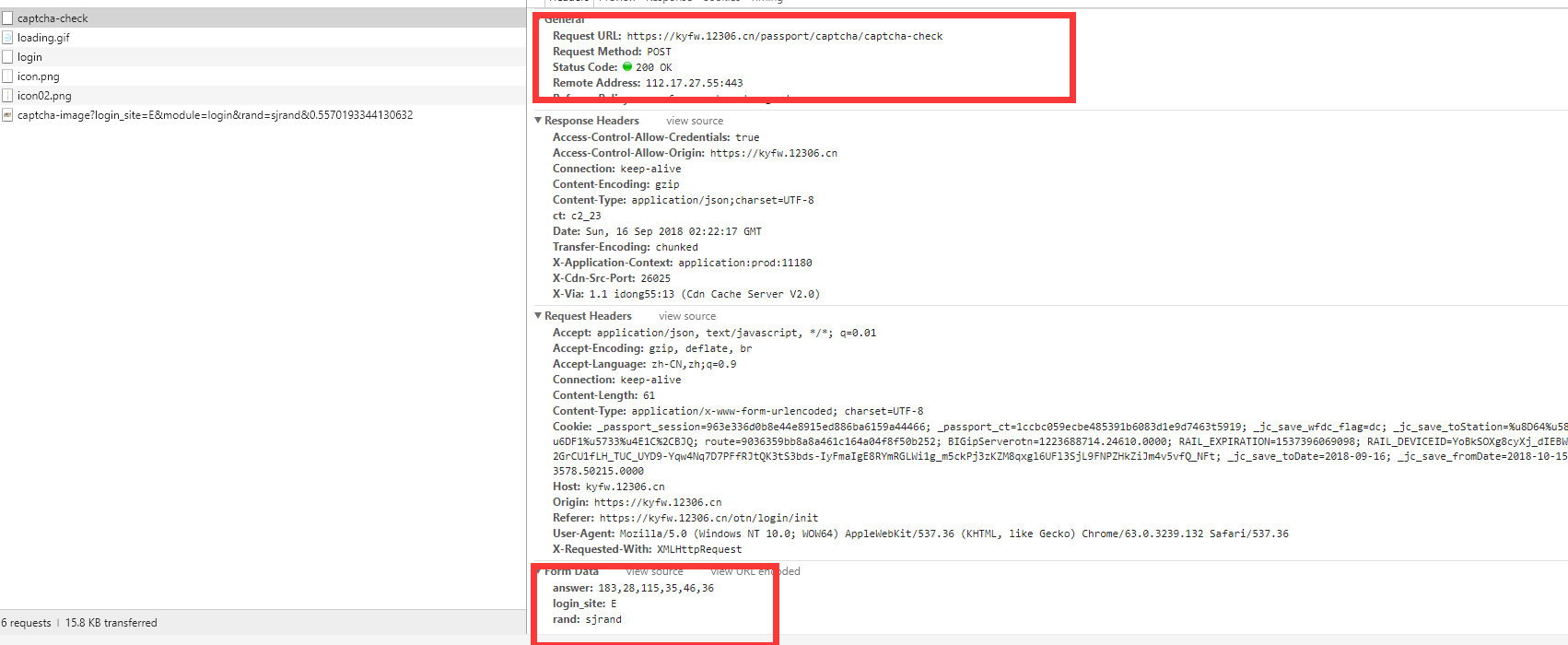
选择正确以后,多了:https://kyfw.12306.cn/passport/captcha/captcha-check 这个POST请求 3个参数
answer 这个呢就是代表 你点的坐标,我这里点了3下 恰好有6个坐标。
后面2个 不知道 应该是固定的
看看返回的
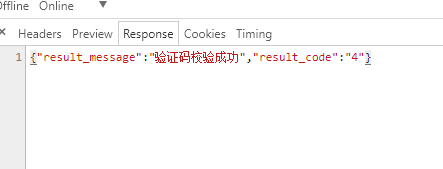
验证成功
登陆
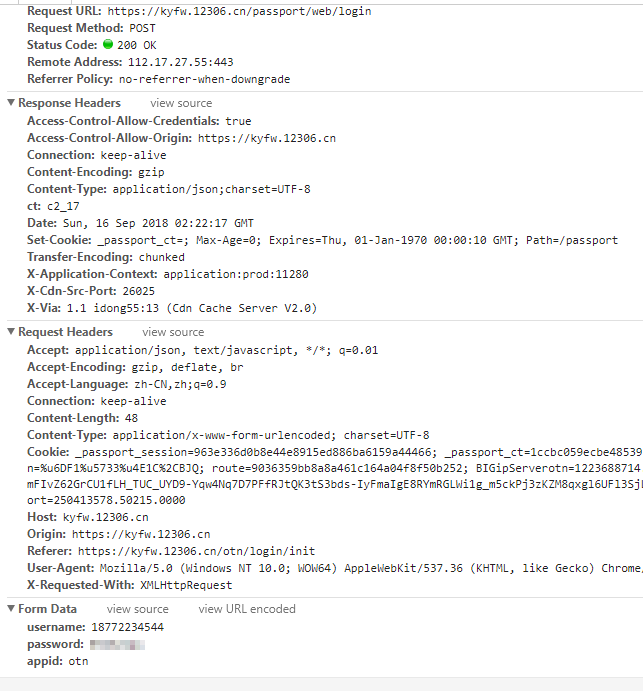

我输入错的 返回就是这个 对的就返回正确。
总结:登陆没难度
----------------------------查票
查票链接:https://kyfw.12306.cn/otn/leftTicket/init
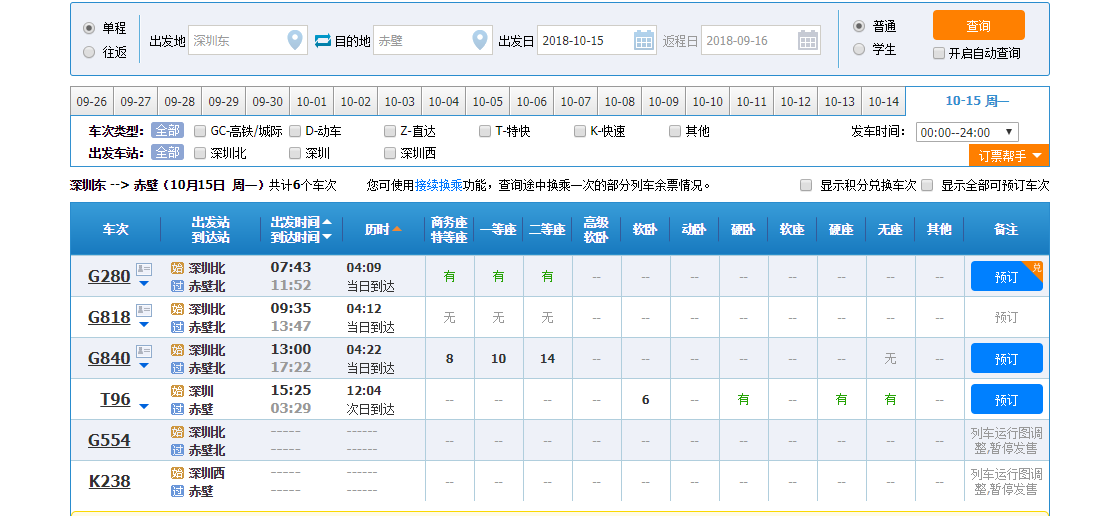
输入 出发地,目的地 ,时间后。点击查询
多出了这个请求
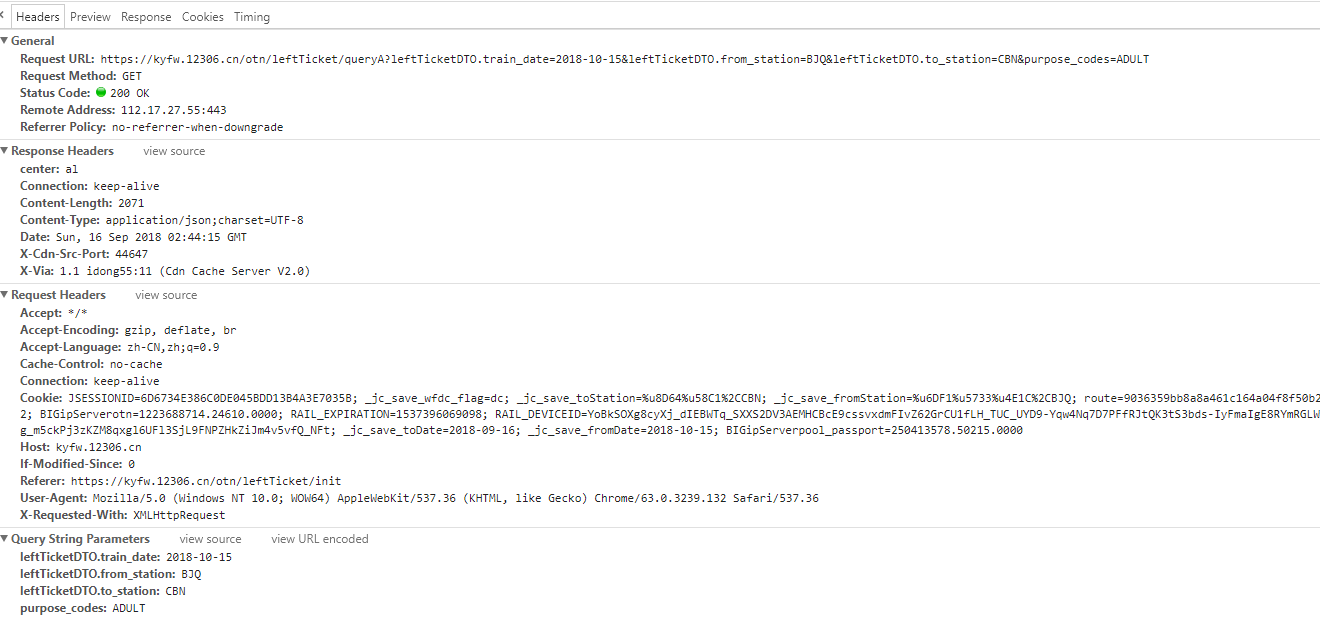
看看返回
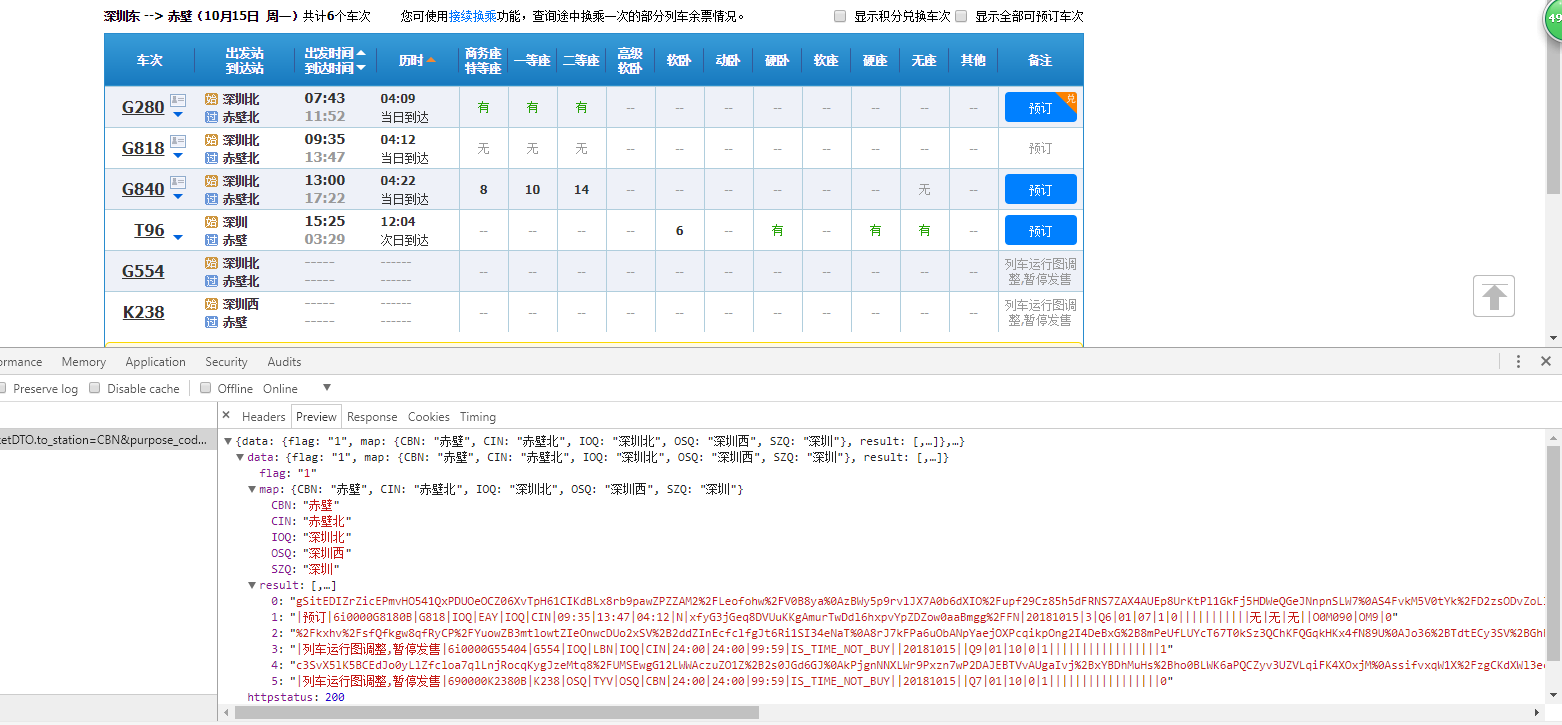
这不就是列车余票吗
但是CBN 为什么是赤壁呢
看看这个JS文件 就知道了

所有的车站名都用英文大写表示了
----------------------------产生订单
在没有登陆的时候点击预定。会弹出需要登陆的页面
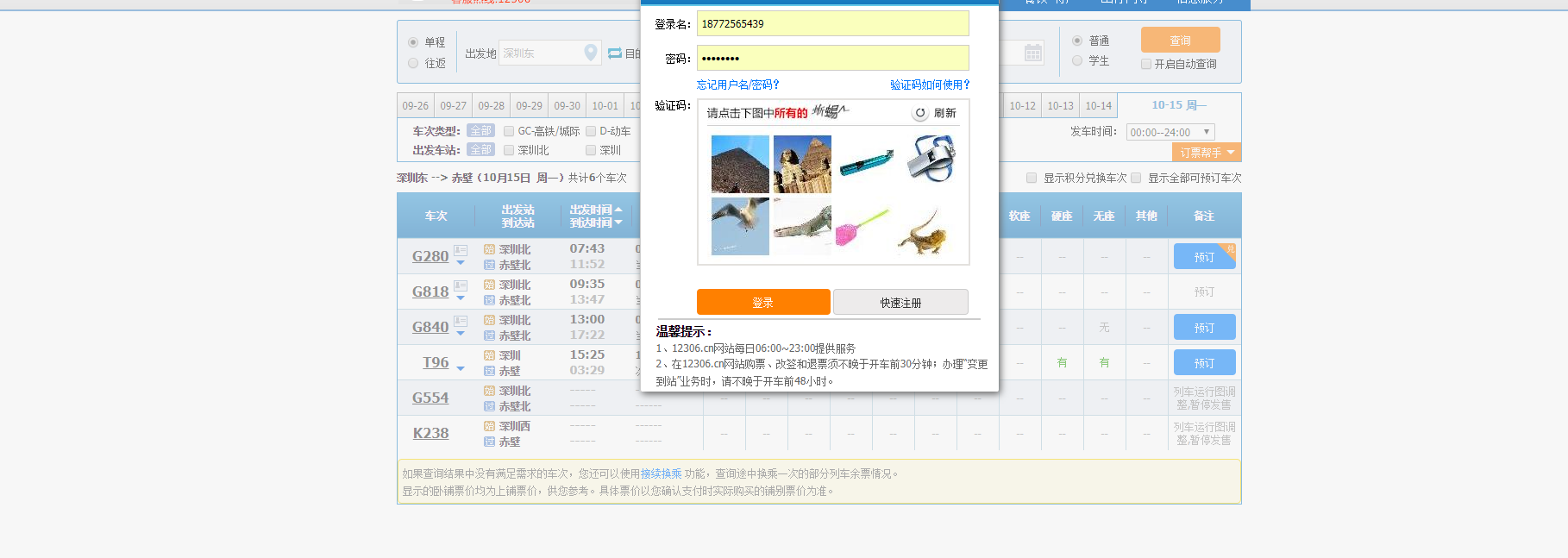
还会多出这个请求

看到LOGIN这个单词,肯定和登陆有关 就是验证登陆状态吧,
用Mozilla Firefox浏览器的就会发现当flag为 true的时候也就你成功登陆之后 才会跳转
成功登陆后来到订单页面
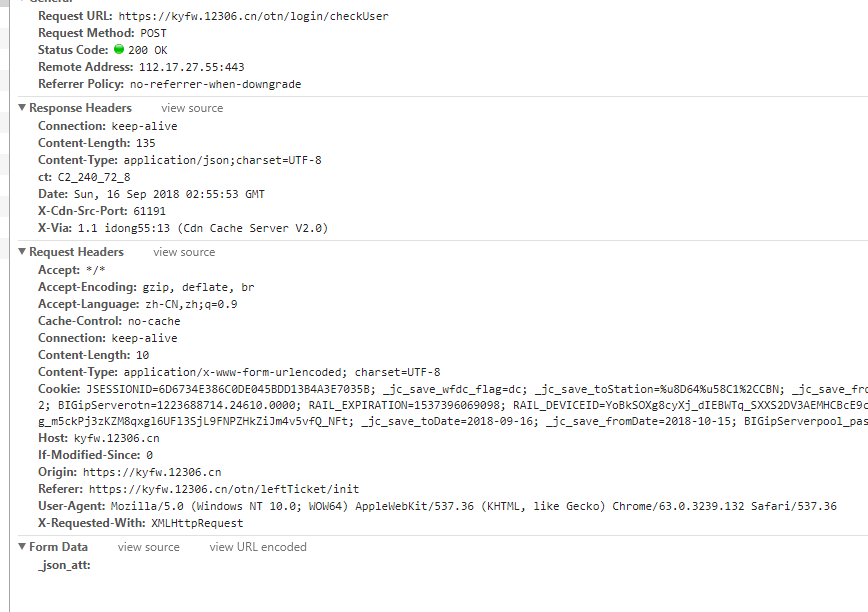
https://kyfw.12306.cn/otn/confirmPassenger/initDc
看到了联系人的请求

有个参数
REPEAT_SUBMIT_TOKEN
这个参数是什么意思 我也不知道。。。
要找这个对应的值,可就找的好苦

在这里

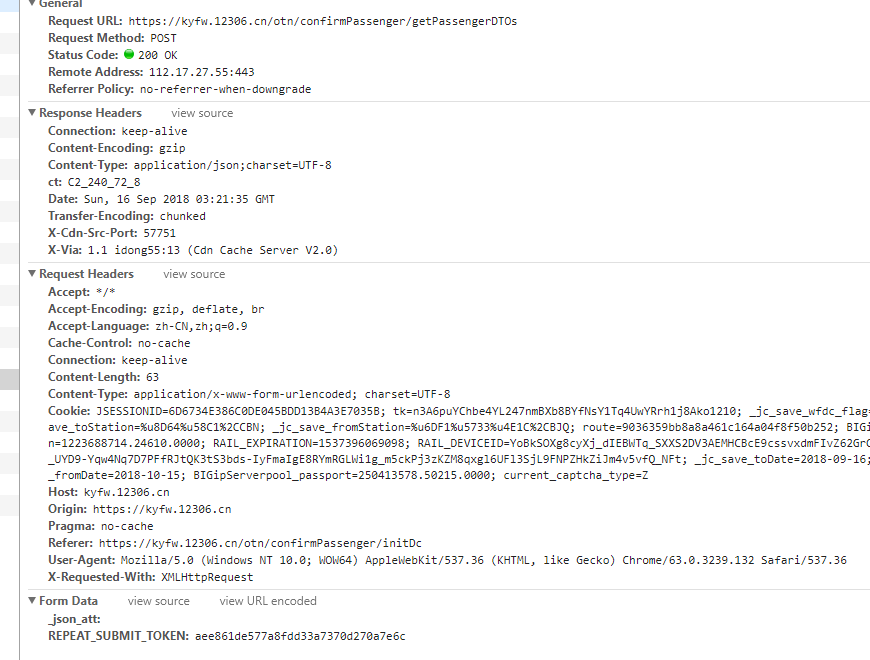
选择一个联系人后 点击提交
来分析第一个

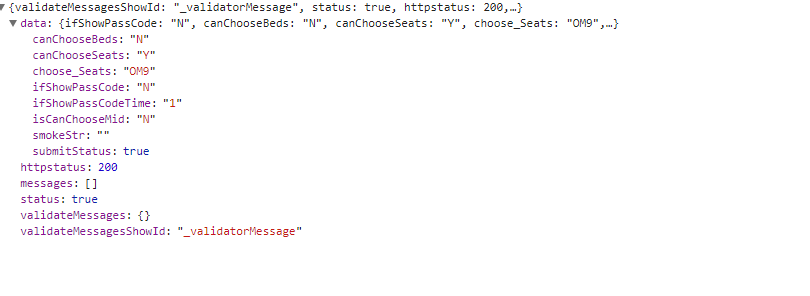
返回的什么 我不知道 我们看看请求的参数

第一个 第二个是固定的
第3个 第4个是乘客信息 第4个
tour_flag:dc 我开始以为是动车的意思 ,结果我想多了 是购票类型 dc为单程
REPEAT_SUBMIT_TOKEN这个都知道在哪里了吧
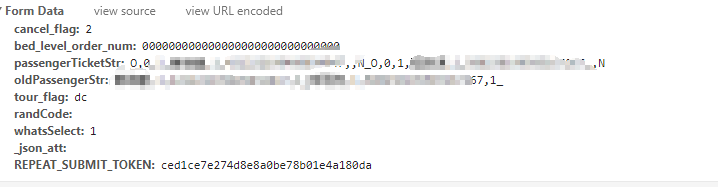
2张就用,隔开吧 这是我想的。最好就买1张
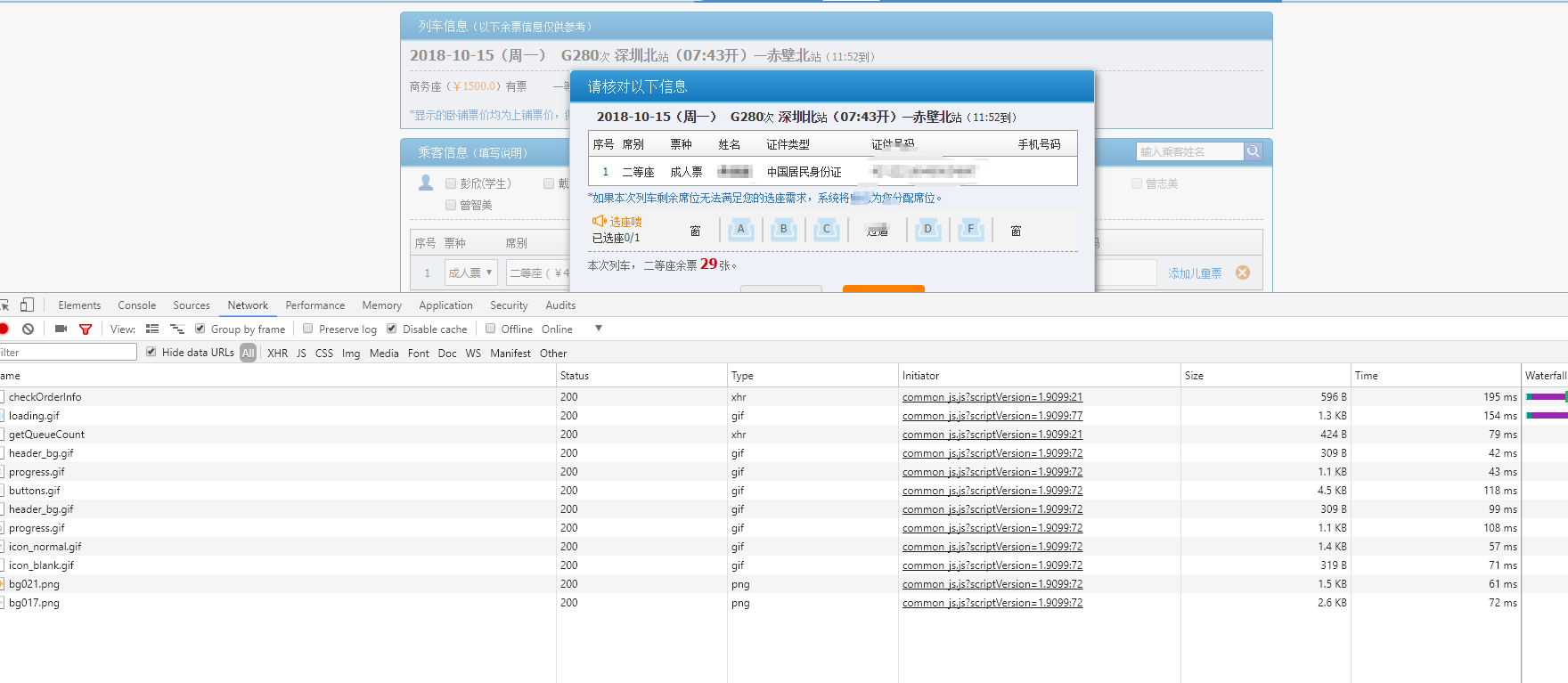
下一个请求
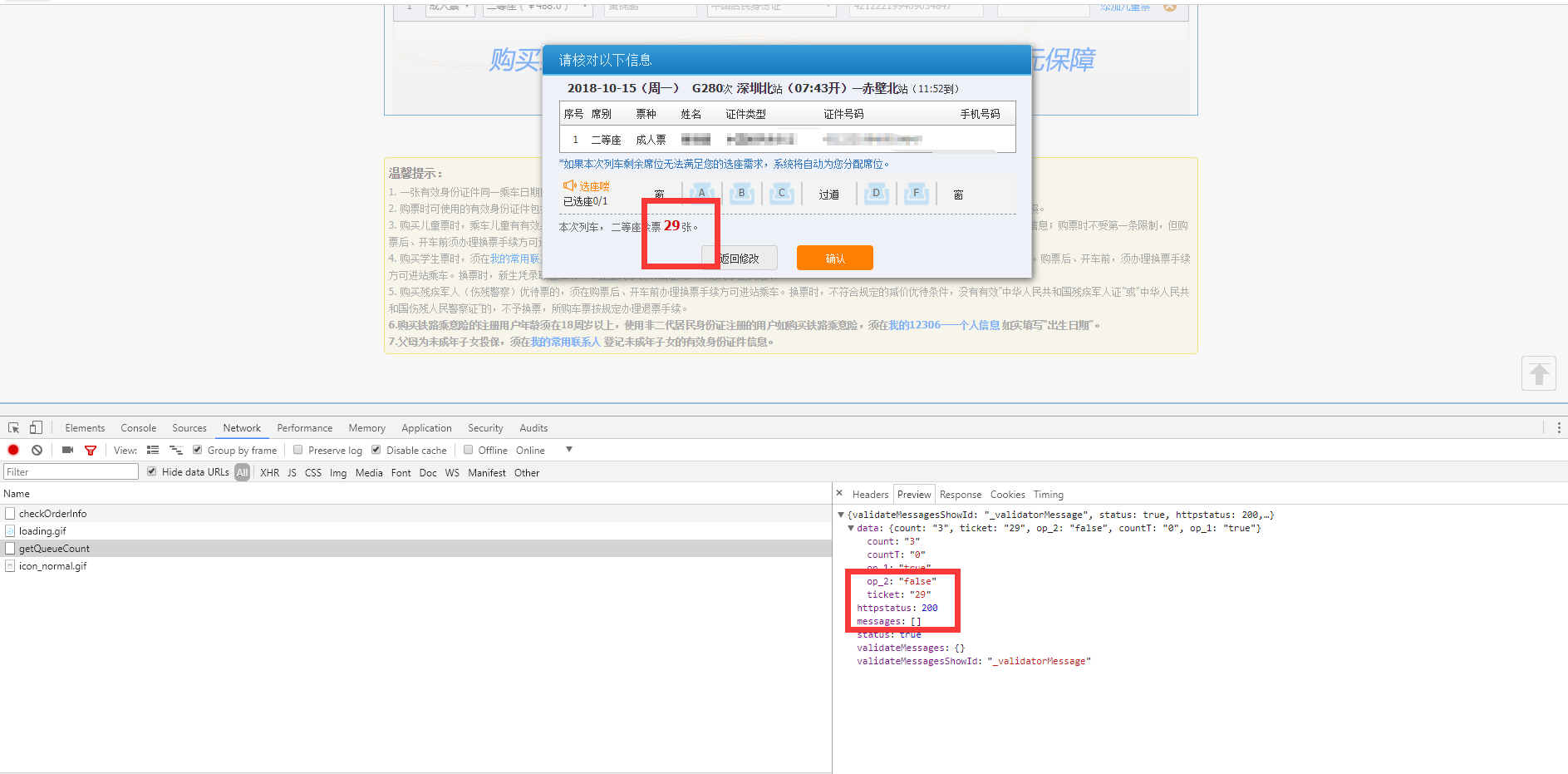
count 好像是表示座位类型 多试试就知道 余票是29张。
看看请求参数
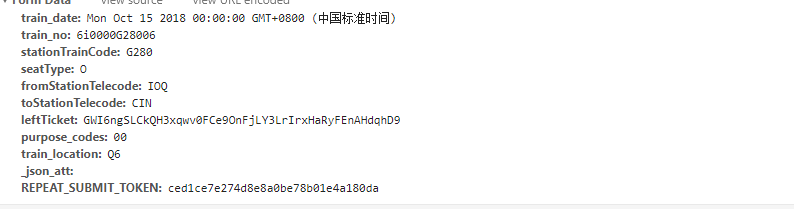
train_date
train_no #火车编号
stationTrainCode #火车列号
seatType #座位类型 1是硬座,2是软座,3是硬卧,4是软卧,O是高铁二等座,M是高铁一等座,
fromStationTelecode #出发站
toStationTelecode #目的站
leftTicket #也是和REPEAT_SUBMIT_TOKEN一样或得
purpose_codes = 00
train_location = PB
_json_att
就差最后一步了
点击提交订单
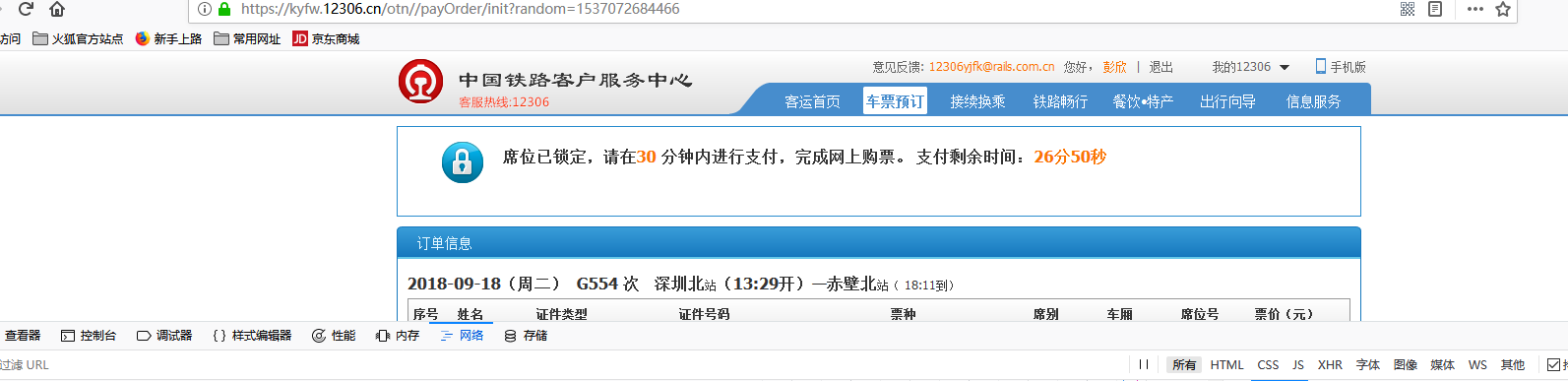
分析这些
刚刚下了个迷你的火狐
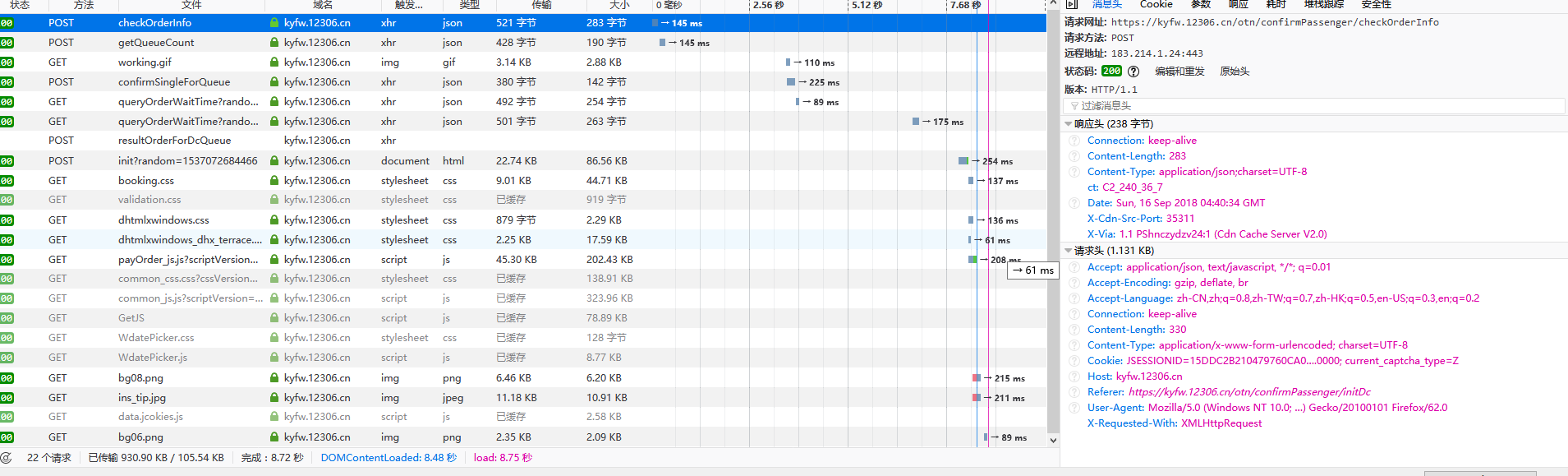
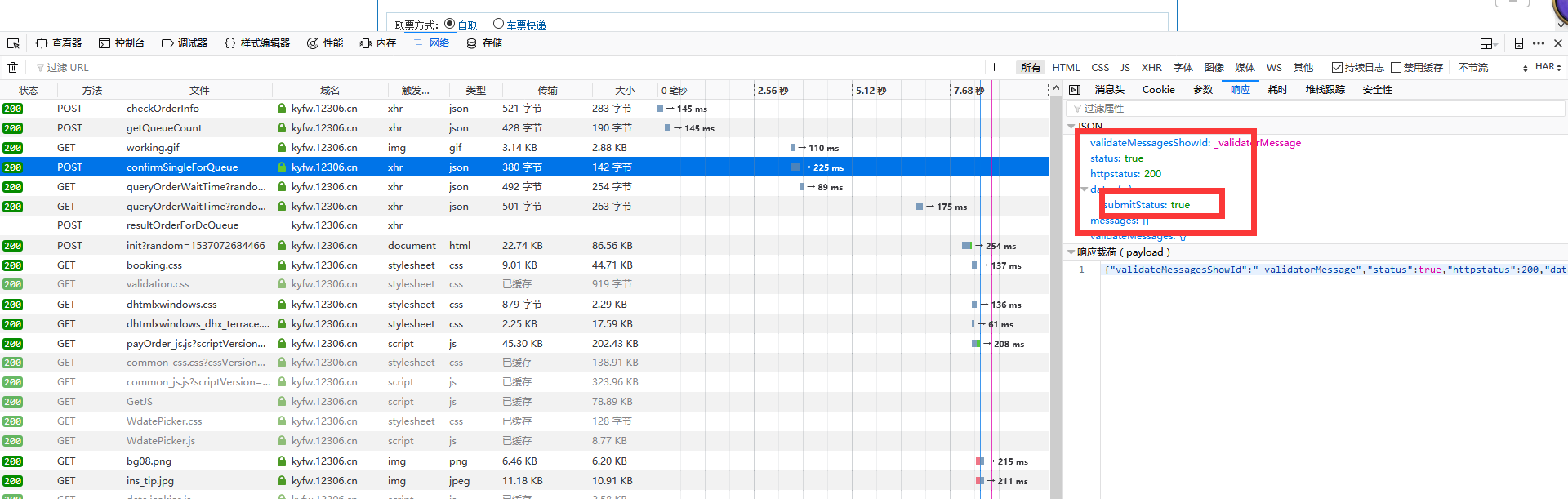
返回"data":{"submitStatus":true}说明请求成功,出票成功,如果为其他就是扣票失败
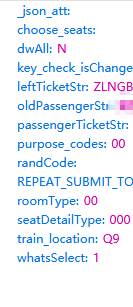
这些参数 除了联系人信息都可以和REPEAT_SUBMIT_TOKEN这个参数一样获得。
写博客也是不易
这个没用任何语言 纯分析 一些细致的参数 在JS里面有声明。
最后 告诉大家 也给自己打气
加油
做生活里的小强
Python爬虫之12306-分析请求总概述的更多相关文章
- python爬虫之12306网站--火车票信息查询
python爬虫之12306网站--火车票信息查询 思路: 1.火车票信息查询是基于车站信息查询,先完成车站信息查询,然后根据车站信息查询生成的url地址去查询当前已知出发站和目的站的所有车次车票信息 ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- python爬虫之12306网站--车站信息查询
python爬虫查询车站信息 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息进行处理 python爬虫查询全拼相同的车站 目录: 1.找到要查询的url 2.对信息进行分析 3.对信息 ...
- python爬虫框架(1)--框架概述
框架概述 其中比较好用的是 Scrapy 和PySpider.pyspider上手更简单,操作更加简便,因为它增加了 WEB 界面,写爬虫迅速,集成了phantomjs,可以用来抓取js渲染的页面.S ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
- python爬虫——词云分析最热门电影《后来的我们》
1 模块库使用说明 1.1 requests库 requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更 ...
- python爬虫--模拟12306登录
模拟12306登录 超级鹰: #!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Ch ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- Python爬虫-02:HTTPS请求与响应,以及抓包工具Fiddler的使用
目录 1. HTTP和HTTPS 1.1. HTTP的请求和响应流程:打开一个网页的过程 1.2. URL 2. 客户端HTTP请求 3. Fiddler抓包工具的使用 3.1. 工作原理 3.2. ...
随机推荐
- Eclipse中快捷键Ctrl + Alt + 向上箭头 或者 Ctrl + Alt + 向下箭头与Windows冲突
原文地址:https://blog.csdn.net/buaaroid/article/details/50804608 clipse中按ctrl + alt + 向上箭头没有任何反应,按ctrl + ...
- (light oj 1319) Monkey Tradition 中国剩余定理(CRT)
题目链接:http://lightoj.com/volume_showproblem.php?problem=1319 In 'MonkeyLand', there is a traditional ...
- flutter 监听返回键
### 监听手机返回键(双击退出) ``` import 'package:fluttertoast/fluttertoast.dart'; //提示插件 class WillPopScopeTest ...
- 注意:QQ影音视频压缩时长丢失
客户宣传片发来,高清的,比较大,500多M,需要转成小一点的,放在客户网站上,于是用QQ影音转码压缩下,变成低质量的.如下 一切都很顺利,提示进度100%! 这一切都是电脑自动的,又是提示成功的,千想 ...
- codeforces 796A-D
决定在 codeforces 练题啦,决定每个比赛刷前四道...太难就算了 796A Buying A House 题意:给出x轴上的n 个点,每个点有个权值,问离m 点最近的权值小于等于k 的点离m ...
- XXXX is not in the sudoers file. This incident will be reported解决方法
假设你用的是Red Hat系列(包括Fedora和CentOS)的Linux系统.当你执行sudo命令时可能会提示“某某用户 is not in the sudoers file. This inc ...
- 回温js算法
---恢复内容开始--- 一,冒泡排序. 具体算法描述如下: <1>.比较相邻的元素.如果第一个比第二个大,就交换它们两个: <2>.对每一对相邻元素作同样的工作,从开始第一对 ...
- Nginx Http 过滤模块
L69 执行顺序在content阶段后 log阶段前调用的 也就是处理完用户业务后 准备记录处理日志之前 我们可以到nginx http_model.c里查看 数组 执行顺序从下至上顺序执行 copy ...
- 关于小米4电信4g刷入第三方ROM无信号解决办法
from: http://www.yuwantb.com/xiaomi4-lineage-os.html 关于小米4电信4g刷入第三方ROM无信号解决办法 下载这个电信4g补丁包. 链接:http ...
- 【Spring】Spring随笔索引
Spring随笔索引 [Spring]Spring bean的实例化 [Spring]手写Spring MVC [Spring]Spring Data JPA