微博Feed流
一、微博核心业务图
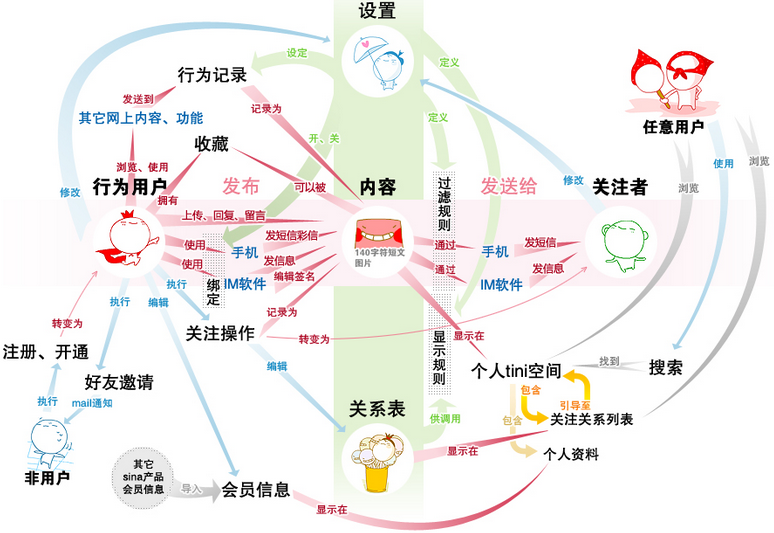
二、微博的架构设计图
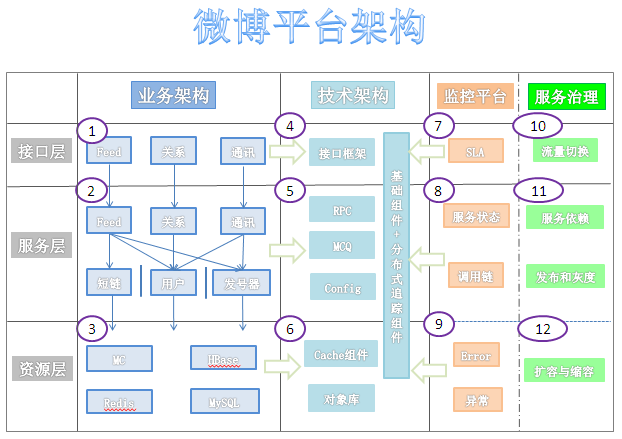
三、简述
先来看看Feed流中的一些概念:
- Feed:Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人微博关注页等等都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流。
- 关注页Timeline:展示其他人Feed消息的页面,比如微博的首页等。
- 个人页Timeline:展示自己发送过的Feed消息的页面,比如微博的个人页等。
Feed流的主要模式:
- 推(Push)
- 拉(Pull)
- 推拉结合(Hybrid)
推模式
又称写扩散。该方式为每个用户维护一个订阅列表,记录该用户订阅的消息索引(一般为消息ID、类型、发表时间等元数据)。每当用户发布消息时,都会去更新其关注者的订阅列表。
优点:存储空间可能不是很大,用户查询自己关注的所有人Feed时,速度快,性能非常高。
缺点:
1. 推送量会非常大。比如微博红人何炅(粉丝1亿+)发一篇微博,如果采用推模式,就会产生一亿+条数据。
2. 资源浪费。试想,一个大量用户的微博系统如果使用推模式,是不是会产生非常巨大的数据呢?更何况活跃用户只有几千万,剩下几个亿的用户他们可能是半年来一次,或者说更短如两周过来一次;这些数据推给他可能根本没有机会看到,存在很大的资源浪费。
拉模式
又称读扩散。该方式为每个用户维护一个Feed列表,记录该用户所有关注的动态索引。只需要用户发表微博时,存储一条微博数据到Feed表中。用户每次查询Feed时都会去查询Feed表,产生:
优点:这种模式实现起来比较简单,只是在查询的时候需要多考虑下缓存的结构;
缺点:
1. 当用户登陆时,必须很快返回数据的时候,运算量非常大。Feeds表会产生很大的压力,对于一个大系统,Feed表会产生比较大的数据,如果粉丝人数比较多,数据库的压力就会非常大。
2. 一般在线的用户,客户端都会定期扫描,又会增加很大的压力,这在查询性能上没有推模式的效率高。
共性问题:不管推模式还是拉模式都存在如果关注数量或者粉丝数量过多,会导致遍历时间太长的问题。综合所有考虑,因为我们要做的是一个要求实时度很高的系统,把不必要系统开销去掉。怎么去解决 ?
推拉结合模式
这是一种折中的解决方案:在线推、离线拉。用户发布状态时,即便微博大V,同时在线的粉丝可能只有几万甚至几千。推拉模式只推给在线的粉丝,离线的粉丝上线后手动拉取状态即可同步内容。同时,每个用户都会维护一个类似发件箱与收件箱的东西,来保存自己发过的状态和Feed状态,以完成推和拉。
微博是一个广场,所有人都可以关注、发送、转载等,相比较限制人数为5000人的朋友圈,其复杂程度高于朋友圈的timeline,因此考虑到时效性和内存的代价,应该会把用户分为热用户和冷用户,并针对不同用户采取不同的方式。
参考文章:
https://www.cnblogs.com/zl0372/articles/feed_6.html
https://juejin.im/entry/5b166320f265da6e61788a25
https://www.cnblogs.com/sunli/archive/2010/08/24/twitter_feeds_push_pull.html
https://www.cnblogs.com/taozi32/p/9955007.html
微博Feed流的更多相关文章
- feed 流数据请求时机的两个思路
最近 SF 首页 进行了大改版,效果如下: 其他地方都没什么难点,中间的 feed 流思考了不少时间,效果需要类似微博或者知乎 feed 流.之前一直没有做过类似的功能,现总结两个方案. 方案一 方案 ...
- 如何打造千万级Feed流系统
from:https://www.cnblogs.com/taozi32/p/9711413.html 在互联网领域,尤其现在的移动互联网时代,Feed流产品是非常常见的,比如我们每天都会用到的朋友圈 ...
- feed流拉取,读扩散,究竟是啥?
from:https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=2651961214&idx=1&sn=5e80ad6f2 ...
- 常用Feed流架构实现
业务中很多需求都会用到类似feed流的架构. 例如 微信朋友圈 微博 动态 1对N消息. 一般feed流的架构实现有下面几种. 假如现在的业务场景是微博,然后当前的数据情况是: 用户A关注了用户B和C ...
- Feed流系统设计-总纲
https://mp.weixin.qq.com/s/ccxM2thPbzg5vDWgGVJ5vQ 作者:少强 简介 差不多十年前,随着功能机的淘汰和智能机的普及,互联网开始进入移动互联网时代,最具代 ...
- 数据人看Feed流-架构实践
背景 Feed流:可以理解为信息流,解决的是信息生产者与信息消费者之间的信息传递问题.我们常见的Feed流场景有:1 手淘,微淘提供给消费者的首页商品信息,用户关注店铺的新消息等2 微信朋友圈,及时获 ...
- Feed 流系统杂谈
什么是 Feed 流 Feed 流是社交和资讯类应用中常见的一种形态, 比如微博知乎的关注页.微信的订阅号和朋友圈等.Feed 流源于 RSS 订阅, 用户将自己感兴趣的网站的 RSS 地址登记到 R ...
- Feed流系统重构-架构篇
重构,于我而言,很大的快乐在于能够解决问题. 第一次重构是重构一个c#版本的彩票算奖系统.当时的算奖系统在开奖后,算奖经常超时,导致用户经常投诉.接到重构的任务,既兴奋又紧张,花了两天时间,除了吃饭睡 ...
- 从小白到架构师(4): Feed 流系统实战
「从小白到架构师」系列努力以浅显易懂.图文并茂的方式向各位读者朋友介绍 WEB 服务端从单体架构到今天的大型分布式系统.微服务架构的演进历程.读了三篇万字长文之后各位想必已经累了(主要是我写累了), ...
随机推荐
- jQuery 源码分析(十九) DOM遍历模块详解
jQuery的DOM遍历模块对DOM模型的原生属性parentNode.childNodes.firstChild.lastChild.previousSibling.nextSibling进行了封装 ...
- Java设计模式:Flyweight(享元)模式
概念定义 享元(Flyweight)模式运用共享技术高效地支持大量细粒度对象的复用. 当系统中存在大量相似或相同的对象时,有可能会造成内存溢出等问题.享元模式尝试重用现有的同类对象,如果未找到匹配的对 ...
- WEB-INF文件夹作用
WEB-INF是Java的WEB应用的安全目录,客户端无法访问,只能通过服务端访问,从而实现了代码的安全.在WEB-INF中主要是系统运行的配置信息和环境 主要有classes.config.lib文 ...
- MySQL学习——存储引擎
MySQL学习——存储引擎 摘要:本文主要学习了MySQL数据库的存储引擎. 什么是存储引擎 数据库存储引擎是数据库底层软件组件,数据库管理系统使用数据引擎进行创建.查询.更新和删除数据操作.不同的存 ...
- Redis缓存系列
一.缓存雪崩 缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了, ...
- vscode 设置代码格式化缩进为2个空格
打开文件——>首选——>设置 输入搜索 tabsize 按照下图设置即可,然后打开 注意:如果不将Detect Indentation 勾选取消 以前用tab创建的忘记依然为4个空格
- 第三方库Mantle的源码解析
Mantle是一个用于简化Cocoa或Cocoa Touch程序中model层的第三方库.通常我们的应该中都会定义大量的model来表示各种数据结构,而这些model的初始化和编码解码都需要写大量的代 ...
- Vue实战狗尾草博客管理平台第五章
本章主要内容如下: 静态资源服务器的配置.学会如何使用静态资源服务器引入静态资源.并给大家推荐一个免费可使用的oss服务器~ 页面的开发由于近期做出的更改较大.就放在下一篇中. 静态资源服务器 静态资 ...
- java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x8E' for column 'name' at row 1
我的错误案例: ,这个后台插不进去,就姓名那栏的中文编码问题. 遇到这个错误,应该是创建表的时候没有设置好编码,这个错误不用多想,我也试过在更改表那里设置编码,但还是不行,还是有残留 直接drop t ...
- python爬虫(2)——urllib、get和post请求、异常处理、浏览器伪装
urllib基础 urlretrieve() urlretrieve(网址,本地文件存储地址) 直接下载网页到本地 import urllib.request #urlretrieve(网址,本地文件 ...