Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一、urlopen的url参数 Agent
url不仅可以是一个字符串,例如:https://baike.baidu.com/。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为urlopen的参数使用,
代码:
from urllib import request if __name__ == "__main__":
req = request.Request("https://baike.baidu.com//")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
运行之后,结果就不做展示了。
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl()方法、info()方法、getcode()方法。
geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功。
下面更新代码,进行下面的测试:
from urllib import request if __name__=="__main__":
re=request.Request("http://baike.baidu.com")
response=request.urlopen(re)
print("geturl打印信息:%s"%(response.geturl()))
print('**********************************************')
print("info打印信息:%s"%(response.info()))
print('**********************************************')
print("getcode打印信息:%s"%(response.getcode()))

二、urlopen的data参数
我们可以使用data参数,向服务器发送数据。根据HTTP规范,GET用于信息获取,POST是向服务器提交数据的一种请求,再换句话说:
从客户端向服务器提交数据使用POST;
从服务器获得数据到客户端使用GET(GET也可以提交,暂不考虑)。
如果没有设置urlopen()函数的data参数,HTTP请求采用GET方式,也就是我们从服务器获取信息,如果我们设置data参数,HTTP请求采用POST方式,也就是我们向服务器传递数据。
data参数有自己的格式,它是一个基于application/x-www.form-urlencoded的格式,具体格式我们不用了解, 因为我们可以使用urllib.parse.urlencode()函数将字符串自动转换成上面所说的格式。
三、发送data实例
遇到一些问题,我也暂时使用有道翻译,以后有好的方法更新这部分关于百度百科的爬取。
向有道翻译发送数据,得到网页反馈:
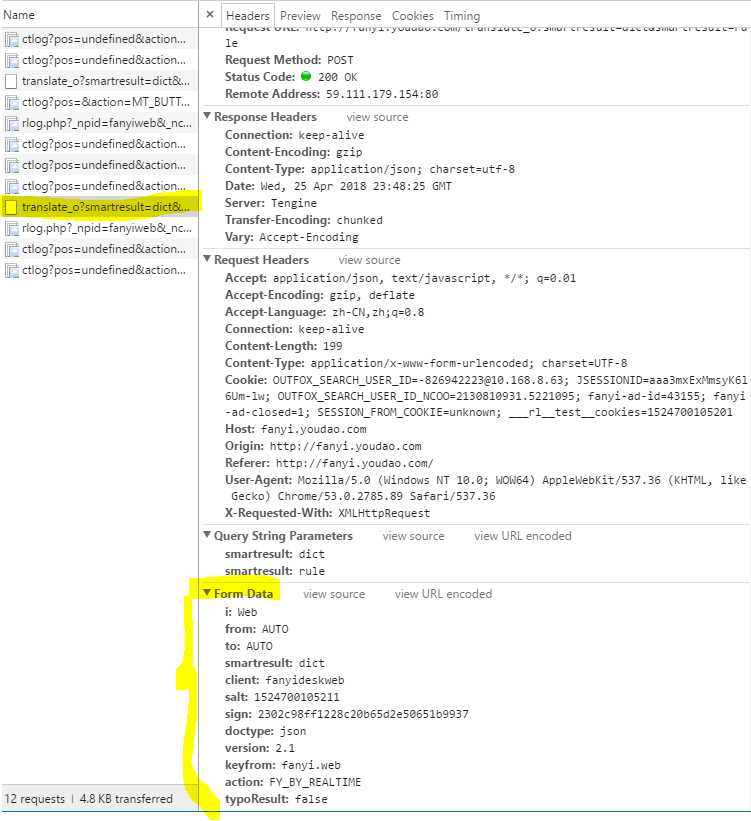
1.打开界面
2.鼠标右键检查元素
3.选择网络/network
4.在搜索输入框 输入查找内容,“network”界面出现了大量内容。
5.得到下方内容:
编写新程序:
from urllib import request
from urllib import parse
import json if __name__ == "__main__":
Request_URL = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
Form_Data = {}
Form_Data['i'] = 'Web'
Form_Data['from'] = 'AUTO'
Form_Data['to'] = 'AUTO'
Form_Data['smartresult'] = 'dict'
Form_Data['client'] = 'fanyideskweb'
Form_Data['salt'] = ''
Form_Data['sign'] = 'c8c86253bcfb23d8405ab58cc0d2b5fa'
Form_Data['doctype'] = 'json'
Form_Data['xmlVersion'] = '2.1'
Form_Data['keyfrom'] = 'fanyi.web'
Form_Data['action'] = 'FY_BY_CLICKBUTTON'
data = parse.urlencode(Form_Data).encode('utf-8')
response = request.urlopen(Request_URL,data)
html = response.read().decode('utf-8')
translate_results = json.loads(html)
translate_results = translate_results['translateResult'][0][0]['tgt']
print("翻译的结果是:%s" % translate_results)
报错:
RESTART: C:\Users\DELL\AppData\Local\Programs\Python\Python36\urllib_test01.py
Traceback (most recent call last):
File "C:\Users\DELL\AppData\Local\Programs\Python\Python36\urllib_test01.py", line 23, in <module>
translate_results = translate_results['translateResult'][0][0]['tgt']
KeyError: 'translateResult'
这是因为data['salt']是时间戳,data['sign']是时间戳和翻译内容加密后生成的,因为不知道网站的加密方法,
在这里选择调整uri和data,并根据http://bbs.fishc.com/thread-98973-1-1.html这里的帖子做出调整:
import os,urllib.request
import urllib.parse
import json
a = 5
while a > 0:
txt = input('输入要翻译的内容:')
if txt == '':
break else:
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&sessionFrom=https://www.baidu.com/link'
data = {
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':'',
'sign':'c8c86253bcfb23d8405ab58cc0d2b5fa',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_CL1CKBUTTON',
'typoResult':'false'} data['i'] = 'Web' data = urllib.parse.urlencode(data).encode('utf - 8')
wy = urllib.request.urlopen(url,data)
html = wy.read().decode('utf - 8')
print(html) ta = json.loads(html)
print('翻译结果: %s '% (ta['translateResult'][0][0]['tgt']))
a = a - 1
结果为:

JSON是一种轻量级的数据交换格式,我们需要在爬取到的内容中找到JSON格式的数据,再将得到的JSON格式的翻译结果进行解析。
总而言之,这部分的内容我终于结束了,debug太耗费时间了!
Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息的更多相关文章
- 【Python3 爬虫】02_利用urllib.urlopen向百度翻译发送数据并返回结果
上一节进行了网页的简单抓取,接下来我们详细的了解一下两个重要的参数url与data urlopen详解 urllib.request.urlopen(url, data=None, [timeout, ...
- Python3爬虫(1)_使用Urllib进行网络爬取
网络爬虫 又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫 ...
- (未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境: 火狐浏览器 pycharm2017.3.3 python3.5 1.url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个Request对象,这就需要我 ...
- [C#参考]利用Socket连续发送数据
这个例子只是一个简单的连续发送数据,接收数据的DEMO.因为最近做一个项目,要求robot连续的通过Socket传回自己的当前的位置坐标,然后客户端接收到坐标信息,在本地绘制地图,实时显示robot的 ...
- 利用urllib.urlopen向有道翻译发送数据获得翻译结果
from urllib import request,parseimport requests, sys,ssl,json ssl._create_default_https_context = ss ...
- Python3爬虫一之(urllib库)
urllib库是python3的内置HTTP请求库. ython2中urllib分为 urllib2.urllib两个库来发送请求,但是在python3中只有一个urllib库,方便了许多. urll ...
- 我的第一个爬虫程序:利用Python抓取网页上的信息
题外话 我第一次听说Python是在大二的时候,那个时候C语言都没有学好,于是就没有心思学其他的编程语言.现在,我的毕业设计要用到爬虫技术,在网上搜索了一下,Python语言在爬虫技术这方面获得一致好 ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
- python3爬虫-通过selenium登陆拉钩,爬取职位信息
from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from se ...
随机推荐
- C语言入门-字符串
还是要继续学习,每天给自己打气. 字符数组 char word[] = {'H','e','l','l','o'}; 这不是c语言的字符串,不能用字符串的方式做计算 一.字符串 char word[] ...
- 从React-Native坑中爬出,我记下了这些
吐槽 如果React-Native是个人,我估计已经想要打死他了... 上一篇文章 当React开发者初次走进React-Native的世界 前言 最近因为业务需要,做了一些关于React-Nativ ...
- 基于hash和pushState的网页前端路由实现
客户端路由 对于客户端(通常为浏览器)来说,路由的映射函数通常是进行一些DOM的显示和隐藏操作.这样,当访问不同的路径的时候,会显示不同的页面组件.客户端路由最常见的有以下两种实现方案:* 基于Has ...
- 微人事 star 数超 10k,如何打造一个 star 数超 10k 的开源项目
看了下,微人事(https://github.com/lenve/vhr)项目 star 数超 10k 啦,松哥第一个 star 数过万的开源项目就这样诞生了. 两年前差不多就是现在这个时候,松哥所在 ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 自学导航页(待续ing)
1 博客导航1.1 linuxlinux全线教程–提供了linux教程,服务器管理教程,BSD教程,还有编程语言(C/Java/Python/Perl),以及网络等全栈学习教程 1.2 存储技术NoS ...
- 用 Sphinx 搭建博客时,如何自定义插件?
之前有不少同学看过我的个人博客(http://python-online.cn),也根据我写的教程完成了自己个人站点的搭建. 点此:使用 Python 30分钟 教你快速搭建一个博客 为防有的同学不清 ...
- Linux之shell基础
Shell基础 一.shell概述 1) shell是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用shell来启动.挂起.停止甚至是编写一些程序 ...
- DJango配置mysql数据库以及数据库迁移
DJango配置mysql数据库以及数据库迁移 一.Django 配置MySQL数据库 在settings.py中配置 import pymysql # 配置MySQL pymysql.install ...
- (19)ASP.NET Core EF创建模型(包含属性和排除属性、主键、生成的值)
1.什么是Fluent API? EF中内嵌的约定将POCO类映射到表.但是,有时您无法或不想遵守这些约定,需要将实体映射到约定指示外的其他对象,所以Fluent API和注解都是一种方法,这两种方法 ...