HikariCP监控指标介绍和应用
概述
HikariCP提供了一些监控指标,他的监控指标都是基于MicroMeter提供出来的,然后支持Prometheus和Dropwizard。本次我们将讨论一下HikariCp的监控指标有哪些,为什么提供这些指标,以及咱们如何去做监控。
监控指标
就像com.zaxxer.hikari.metrics.PoolStats提供的那样,几个重要的指标都存储在poolState中。
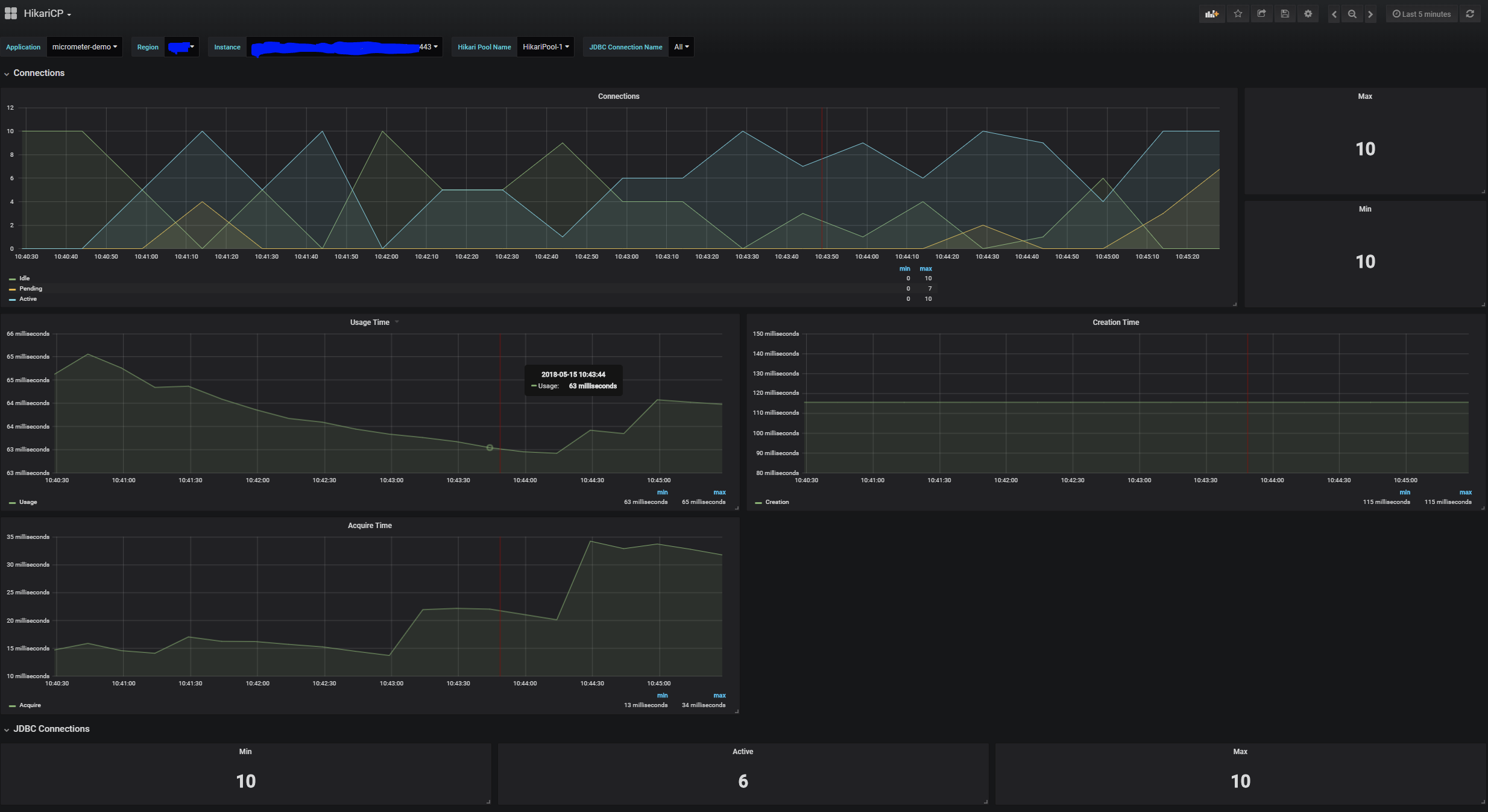
totalConnections
总连接数,包括空闲的连接和使用中的连接。idleConnections 空闲连接数
activeConnections
活跃连接数
totalConnections = activeConnection + idleConnections
pendingThreads
正在等待连接的线程数量。排查性能问题时,这个指标是一个重要的参考指标,如果正在等待连接的线程在相当一段时间内数量较多,可以考虑扩大数据库连接池的size。(即HikariCP的maxPoolSize)maxConnections
最大连接数,统计指标,统计到目前为止连接的最大数量。minConnections
最小连接数,统计指标,统计到目前为止连接的最小数量。usageTime
每个连接使用的时间,当连接被回收的时候会记录此指标:com.zaxxer.hikari.pool.HikariPool#recycleacquireTime
获取每个连接需要等待时间,一个请求获取数据库连接后或者因为超时失败后,会记录此指标。connectionCreateTime
连接创建时间
如何监控
这里拿我们比较熟悉的SpringBoot项目为例,同时使用prometheus和grafana,项目中加入promethues的依赖:
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus:1.3.0'
同时在SpringBoot项目的application.properties配置文件中加入以下参数:
management.endpoints.web.exposure.include=prometheus 暴露prometheus格式化的指标,这样可以被promethues服务器抓取
接下来我们需要启动一个prometheus的服务,https://prometheus.io/download/ 然后更改下peometheus服务的默认配置再启动,追加配置如下:
- job_name: 'prometheus-test' # job名称
scrape_interval: 5s # 抓取时间间隔,这里每5s像数据源请求一次
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['127.0.0.1:8080'] # 这里是springBoot项目的地址
接着启动一个grafana的服务,https://grafana.com/get 启动后添加prometheus数据源,制作仪表盘等。
扩展知识
Micrometer
Vendor-neutral application metrics facade(与供应商无关的应用程序指标外观)。我们可以把它类比于日志框架中的slf4j。把promethues类比于logback。应用程序直接依赖Micrometer来暴露指标。Micrometer比较受欢迎,已经作为SpringBoot2.0内置的指标门面库。Dropwizard
一个Java框架,类似于SpringBoot,但国内使用较少。其中有提供metrics相关的功能。Prometheus
一个监控器的实现,基于pull模型,定时像prometheus数据源拉取指标信息。做分析、处理和展示。
HikariCP监控指标介绍和应用的更多相关文章
- 运维监控-Open-Falcon介绍
运维监控-Open-Falcon介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Open-Falcon 介绍 监控系统是整个运维环节,乃至整个产品生命周期中最重要的一环,事 ...
- zabbix监控-基本原理介绍
一.Linux下开源监控系统简单介绍1)cacti:存储数据能力强,报警性能差2)nagios:报警性能差,存储数据仅有简单的一段可以判断是否在合理范围内的数据长度,储存在内存中.比如,连续采样数据存 ...
- Tensorboard教程:监控指标可视化
Tensorflow监控指标可视化 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 强烈推荐Tensorflow实战Google深度学习框架 实验平台: Tensorflow1.4. ...
- MySQL 监控指标
为了排查问题,对数据库的监控是必不可少的,在此介绍下 MySQL 中的常用监控指标. 简介 MySQL 有多个分支版本,常见的有 MySQL.Percona.MariaDB,各个版本所对应的监控项也会 ...
- Elasticsearch 监控指标解析
1.集群监控 集群监控主要包括两个方面的内容,分别是集群健康情况和集群的运行状态. 集群健康状态可以通过以下api获取: http://ip:9200/_cluster/health?pretty 关 ...
- prometheus自定义监控指标——实战
上一节介绍了pushgateway的作用.优劣以及部署使用,本机通过几个实例来重温一下自定义监控指标是如何使用的. 一.监控容器启动时间(shell) 使用prometheus已经两个月了,但从未找到 ...
- idou老师教你学istio2:监控能力介绍
我们知道每个pod内都会有一个Envoy容器,其具备对流入和流出pod的流量进行管理,认证,控制的能力.Mixer则主要负责访问控制和遥测信息收集. 如拓扑图所示,当某个服务被请求时,首先会请求ist ...
- 系统服务监控指标--load、CPU利用率、磁盘剩余空间、磁盘I/O、内存使用情况等
介绍 大型互联网企业的背后,依靠的是成千上万台服务器日夜不停的运转,以支撑其业务的运转.宕机对于互联网企业来说,代价是沉重的,轻则影响用户体验,重则直接影响交易,导致交易下跌,并且给企业声誉造成不可挽 ...
- IT运维监控解决方案介绍
现状 •小公司/ 创业团队< 500台服务器规模 开源方案:Zabbix.Nagios.Cacti- 云服务提供商:监控宝.oneAlert等 •BAT级别> 10万台服务器 投 ...
随机推荐
- 【oracle】ORA-00947: 没有足够的值
insert 时 对应NOT NULL 的列 必须有值
- java之子类对象实例化过程
假设现在有这么一个父类: public class Person{ public Person(){} public String name = "tom"; public int ...
- swoole比php好在哪里
直接套用Swoole官网的介绍: PHP的异步.并行.高性能网络通信引擎,使用纯C语言编写,提供了PHP语言的异步多线程服务器,异步TCP/UDP网络客户端,异步MySQL,异步Redis,数据库连接 ...
- B站弹幕爬取 / jieba分词 - 全站第一的视频弹幕都在说什么?
前言 本次爬取的视频av号为75993929(11月21的b站榜首),讲的是关于动漫革命机,这是一部超魔幻现实主义动漫(滑稽),有兴趣的可以亲身去感受一下这部魔幻大作. 准备工作 B站弹幕的爬取的接口 ...
- go语言的错误处理
1.系统自己抛异常 //go语言抛异常 func test3_1() { l := [5] int {0,1,2,3,4} var index int = 6 fmt.Println(l) l[ind ...
- 【分析工具】阿里巴巴Arthas--线上问题分析利器
目录 1. Arthas是什么 2. Arthas能解决什么问题 3. 快速安装 第一步:下载 第二步:运行 第三步:选择进程 4. 实战使用 5. 总结 本博客转载自阿里开源的 Java 诊断工具 ...
- C# 异步转同步 PushFrame
异步转同步-PushFrame 本文通过PushFrame,实现异步转同步 首先有一个异步方法,如下异步任务延时2秒后,返回一个结果 private static async Task<stri ...
- 我的计划任务 --- 实现市电停电安全关闭群辉,Windows, Linux等设备
有一次突然停电,我的群辉DS218+ 的一块硬盘出现故障了,让我担心我的数据安全,其实我是有UPS, 不是在线式的,然后就想如何实现停电自动关机呢? 经过半天的了解,其实群辉支持telnet协议,于是 ...
- abp去掉AbpUser中的Name,Surname,去掉姓和名分离
abp是国外的框架,默认的框架中的AbpUser表中的Name和Surname是分开的,这不符合国情:可以先去掉 1. 在User类中重写Name和Surname,并设置为私有 2. 在DbConte ...
- oracle产销存的写法
with TEMP as (select sum(MMT.TRANSACTION_QUANTITY) QTY_QC, MMT.INVENTORY_ITEM_ID --,CAH.Legal_Entity ...