基于Spark的电影推荐系统(推荐系统~7)
基于Spark的电影推荐系统(推荐系统~7)
22/100
发布文章
liuge36
第四部分-推荐系统-实时推荐
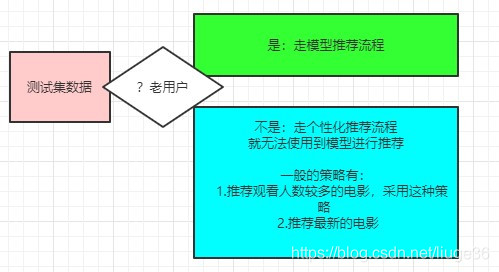
- 本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影。
说明几点
1.数据来源是 testData 测试集的数据。这里面的用户,可能存在于训练集中,也可能是新用户。因此,这里要做处理。
2. SparkStreaming + kakfa
开始Coding
步骤一:在streaming 包下,新建PopularMovies2
package com.csylh.recommend.streaming
import com.csylh.recommend.config.AppConf
import org.apache.spark.sql.SaveMode
/**
* Description: 个性化推荐
*
* @Author: 留歌36
* @Date: 2019/10/18 17:42
*/
object PopularMovies2 extends AppConf{
def main(args: Array[String]): Unit = {
val movieRatingCount = spark.sql("select count(*) c, movieid from trainingdata group by movieid order by c")
// 前5部进行推荐
val Top5Movies = movieRatingCount.limit(5)
Top5Movies.registerTempTable("top5")
val top5DF = spark.sql("select a.title from movies a join top5 b on a.movieid=b.movieid")
// 把数据写入到HDFS上
top5DF.write.mode(SaveMode.Overwrite).parquet("/tmp/top5DF")
// 将数据从HDFS加载到Hive数据仓库中去
spark.sql("drop table if exists top5DF")
spark.sql("create table if not exists top5DF(title string) stored as parquet")
spark.sql("load data inpath '/tmp/top5DF' overwrite into table top5DF")
// 最终表里应该是5部推荐电影的名称
}
}
步骤二:在streaming 包下,新建SparkDirectStreamApp
package com.csylh.recommend.streaming
import com.csylh.recommend.config.AppConf
import kafka.serializer.StringDecoder
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Description:
*
* @Author: 留歌36
* @Date: 2019/10/18 16:33
*/
object SparkDirectStreamApp extends AppConf{
def main(args:Array[String]): Unit ={
val ssc = new StreamingContext(sc, Seconds(5))
val topics = "movie_topic".split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list"->"hadoop001:9093,hadoop001:9094,hadoop001:9095",
"auto.offset.reset" -> "largest" //smallest :从头开始 largest:最新
)
// Direct 模式:SparkStreaming 主动去Kafka中pull拉数据
val modelPath = "/tmp/BestModel/0.8521581387523667"
val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
def exist(u: Int): Boolean = {
val trainingdataUserIdList = spark.sql("select distinct(userid) from trainingdata")
.rdd
.map(x => x.getInt(0))
.collect() // RDD[row] ==> RDD[Int]
trainingdataUserIdList.contains(u)
}
// 为没有登录的用户推荐电影的策略:
// 1.推荐观看人数较多的电影,采用这种策略
// 2.推荐最新的电影
val defaultrecresult = spark.sql("select * from top5DF").rdd.toLocalIterator
// 创建SparkStreaming接收kafka消息队列数据的2种方式
// 一种是Direct approache,通过SparkStreaming自己主动去Kafka消息队
// 列中查询还没有接收进来的数据,并把他们拉pull到sparkstreaming中。
val model = MatrixFactorizationModel.load(ssc.sparkContext, modelPath)
val messages = stream.foreachRDD(rdd=> {
val userIdStreamRdd = rdd.map(_._2.split("|")).map(x=>x(1)).map(_.toInt)
val validusers = userIdStreamRdd.filter(userId => exist(userId))
val newusers = userIdStreamRdd.filter(userId => !exist(userId))
// 采用迭代器的方式来避开对象不能序列化的问题。
// 通过对RDD中的每个元素实时产生推荐结果,将结果写入到redis,或者其他高速缓存中,来达到一定的实时性。
// 2个流的处理分成2个sparkstreaming的应用来处理。
val validusersIter = validusers.toLocalIterator
val newusersIter = newusers.toLocalIterator
while (validusersIter.hasNext) {
val u= validusersIter.next
println("userId"+u)
val recresult = model.recommendProducts(u, 5)
val recmoviesid = recresult.map(_.product)
println("我为用户" + u + "【实时】推荐了以下5部电影:")
for (i <- recmoviesid) {
val moviename = spark.sql(s"select title from movies where movieId=$i").first().getString(0)
println(moviename)
}
}
while (newusersIter.hasNext) {
println("*新用户你好*以下电影为您推荐below movies are recommended for you :")
for (i <- defaultrecresult) {
println(i.getString(0))
}
}
})
ssc.start()
ssc.awaitTermination()
}
}
步骤三:将创建的项目进行打包上传到服务器
mvn clean package -Dmaven.test.skip=true
步骤四:先编写个性化推荐代码 shell 执行脚本
[root@hadoop001 ml]# vim PopularMovies2.sh
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit \
--class com.csylh.recommend.streaming.PopularMovies2 \
--master spark://hadoop001:7077 \
--name PopularMovies2 \
--driver-memory 10g \
--executor-memory 5g \
/root/data/ml/movie-recommend-1.0.jar
步骤五:执行sh PopularMovies2.sh
确保:
[root@hadoop001 ml]# spark-sql
19/10/20 22:59:28 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark master: local[*], Application Id: local-1571583574311
spark-sql> show tables;
default links false
default movies false
default ratings false
default tags false
default testdata false
default top5df false
default trainingdata false
default trainingdataasc false
default trainingdatadesc false
Time taken: 2.232 seconds, Fetched 9 row(s)
spark-sql> select * from top5df;
Follow the Bitch (1996)
Radio Inside (1994)
Faces of Schlock (2005)
Mág (1988)
"Son of Monte Cristo
Time taken: 1.8 seconds, Fetched 5 row(s)
spark-sql>
步骤六:再编写model实时推荐代码 shell 执行脚本
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit \
--class com.csylh.recommend.streaming.SparkDirectStreamApp \
--master spark://hadoop001:7077 \
--name SparkDirectStreamApp \
--driver-memory 10g \
--executor-memory 5g \
--total-executor-cores 10 \
--jars /root/app/kafka_2.11-1.1.1/libs/kafka-clients-1.1.1.jar \
--packages "mysql:mysql-connector-java:5.1.38,org.apache.spark:spark-streaming-kafka-0-8_2.11:2.4.2" \
/root/data/ml/movie-recommend-1.0.jar
步骤七:sh SparkDirectStreamApp.sh
// TODO...
有任何问题,欢迎留言一起交流~~
更多文章:基于Spark的电影推荐系统:https://blog.csdn.net/liuge36/column/info/29285
第四部分-推荐系统-实时推荐
本模块基于第4节得到的模型,开始为用户做实时推荐,推荐用户最有可能喜爱的5部电影。
说明几点
1.数据来源是 testData 测试集的数据。这里面的用户,可能存在于训练集中,也可能是新用户。因此,这里要做处理。
2. SparkStreaming + kakfa
在这里插入图片描述
开始Coding
步骤一:在streaming 包下,新建PopularMovies2
package com.csylh.recommend.streaming
import com.csylh.recommend.config.AppConf
import org.apache.spark.sql.SaveMode
/**
Description: 个性化推荐
@Author: 留歌36
@Date: 2019/10/18 17:42
/
object PopularMovies2 extends AppConf{
def main(args: Array[String]): Unit = {
val movieRatingCount = spark.sql("select count() c, movieid from trainingdata group by movieid order by c")
// 前5部进行推荐
val Top5Movies = movieRatingCount.limit(5)Top5Movies.registerTempTable("top5") val top5DF = spark.sql("select a.title from movies a join top5 b on a.movieid=b.movieid") // 把数据写入到HDFS上
top5DF.write.mode(SaveMode.Overwrite).parquet("/tmp/top5DF") // 将数据从HDFS加载到Hive数据仓库中去
spark.sql("drop table if exists top5DF")
spark.sql("create table if not exists top5DF(title string) stored as parquet")
spark.sql("load data inpath '/tmp/top5DF' overwrite into table top5DF") // 最终表里应该是5部推荐电影的名称
}
}
步骤二:在streaming 包下,新建SparkDirectStreamApp
package com.csylh.recommend.streaming
import com.csylh.recommend.config.AppConf
import kafka.serializer.StringDecoder
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
Description:
@Author: 留歌36
@Date: 2019/10/18 16:33
*/
object SparkDirectStreamApp extends AppConf{
def main(args:Array[String]): Unit ={
val ssc = new StreamingContext(sc, Seconds(5))val topics = "movie_topic".split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list"->"hadoop001:9093,hadoop001:9094,hadoop001:9095",
"auto.offset.reset" -> "largest" //smallest :从头开始 largest:最新
)
// Direct 模式:SparkStreaming 主动去Kafka中pull拉数据
val modelPath = "/tmp/BestModel/0.8521581387523667"
val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)def exist(u: Int): Boolean = {
val trainingdataUserIdList = spark.sql("select distinct(userid) from trainingdata")
.rdd
.map(x => x.getInt(0))
.collect() // RDD[row] ==> RDD[Int]trainingdataUserIdList.contains(u)
}
// 为没有登录的用户推荐电影的策略:
// 1.推荐观看人数较多的电影,采用这种策略
// 2.推荐最新的电影
val defaultrecresult = spark.sql("select * from top5DF").rdd.toLocalIterator// 创建SparkStreaming接收kafka消息队列数据的2种方式
// 一种是Direct approache,通过SparkStreaming自己主动去Kafka消息队
// 列中查询还没有接收进来的数据,并把他们拉pull到sparkstreaming中。val model = MatrixFactorizationModel.load(ssc.sparkContext, modelPath)
val messages = stream.foreachRDD(rdd=> {val userIdStreamRdd = rdd.map(_._2.split("|")).map(x=>x(1)).map(_.toInt) val validusers = userIdStreamRdd.filter(userId => exist(userId))
val newusers = userIdStreamRdd.filter(userId => !exist(userId)) // 采用迭代器的方式来避开对象不能序列化的问题。
// 通过对RDD中的每个元素实时产生推荐结果,将结果写入到redis,或者其他高速缓存中,来达到一定的实时性。
// 2个流的处理分成2个sparkstreaming的应用来处理。
val validusersIter = validusers.toLocalIterator
val newusersIter = newusers.toLocalIterator while (validusersIter.hasNext) {
val u= validusersIter.next
println("userId"+u)
val recresult = model.recommendProducts(u, 5)
val recmoviesid = recresult.map(_.product)
println("我为用户" + u + "【实时】推荐了以下5部电影:")
for (i <- recmoviesid) {
val moviename = spark.sql(s"select title from movies where movieId=$i").first().getString(0)
println(moviename)
}
} while (newusersIter.hasNext) {
println("*新用户你好*以下电影为您推荐below movies are recommended for you :")
for (i <- defaultrecresult) {
println(i.getString(0))
}
}
})
ssc.start()
ssc.awaitTermination()
}
}
步骤三:将创建的项目进行打包上传到服务器
mvn clean package -Dmaven.test.skip=true
步骤四:先编写个性化推荐代码 shell 执行脚本
[root@hadoop001 ml]# vim PopularMovies2.sh
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit
--class com.csylh.recommend.streaming.PopularMovies2
--master spark://hadoop001:7077
--name PopularMovies2
--driver-memory 10g
--executor-memory 5g
/root/data/ml/movie-recommend-1.0.jar
步骤五:执行sh PopularMovies2.sh
确保:
[root@hadoop001 ml]# spark-sql
19/10/20 22:59:28 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark master: local[*], Application Id: local-1571583574311
spark-sql> show tables;
default links false
default movies false
default ratings false
default tags false
default testdata false
default top5df false
default trainingdata false
default trainingdataasc false
default trainingdatadesc false
Time taken: 2.232 seconds, Fetched 9 row(s)
spark-sql> select * from top5df;
Follow the Bitch (1996)
Radio Inside (1994)
Faces of Schlock (2005)
Mág (1988)
"Son of Monte Cristo
Time taken: 1.8 seconds, Fetched 5 row(s)
spark-sql>
步骤六:再编写model实时推荐代码 shell 执行脚本
export HADOOP_CONF_DIR=/root/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
$SPARK_HOME/bin/spark-submit
--class com.csylh.recommend.streaming.SparkDirectStreamApp
--master spark://hadoop001:7077
--name SparkDirectStreamApp
--driver-memory 10g
--executor-memory 5g
--total-executor-cores 10
--jars /root/app/kafka_2.11-1.1.1/libs/kafka-clients-1.1.1.jar
--packages "mysql:mysql-connector-java:5.1.38,org.apache.spark:spark-streaming-kafka-0-8_2.11:2.4.2"
/root/data/ml/movie-recommend-1.0.jar
步骤七:sh SparkDirectStreamApp.sh
// TODO…
有任何问题,欢迎留言一起交流~~
更多文章:基于Spark的电影推荐系统:https://blog.csdn.net/liuge36/column/info/29285
Markdown 5232 字数 214 行数 当前行 1, 当前列 0HTML 4908 字数 154 段落
译
基于Spark的电影推荐系统(推荐系统~7)的更多相关文章
- 基于Spark的电影推荐系统(电影网站)
第一部分-电影网站: 软件架构: SpringBoot+Mybatis+JSP 项目描述:主要实现电影网站的展现 和 用户的所有动作的地方 技术选型: 技术 名称 官网 Spring Boot 容器 ...
- 基于Spark的电影推荐系统(实战简介)
写在前面 一直不知道这个专栏该如何开始写,思来想去,还是暂时把自己对这个项目的一些想法 和大家分享 的形式来展现.有什么问题,欢迎大家一起留言讨论. 这个项目的源代码是在https://github. ...
- 基于Spark的电影推荐系统(推荐系统~2)
第四部分-推荐系统-数据ETL 本模块完成数据清洗,并将清洗后的数据load到Hive数据表里面去 前置准备: spark +hive vim $SPARK_HOME/conf/hive-site.x ...
- 基于Spark的电影推荐系统(推荐系统~4)
第四部分-推荐系统-模型训练 本模块基于第3节 数据加工得到的训练集和测试集数据 做模型训练,最后得到一系列的模型,进而做 预测. 训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型 说 ...
- 基于Spark的电影推荐系统(推荐系统~1)
第四部分-推荐系统-项目介绍 行业背景: 快速:Apache Spark以内存计算为核心 通用 :一站式解决各个问题,ADHOC SQL查询,流计算,数据挖掘,图计算 完整的生态圈 只要掌握Spark ...
- 基于Spark的电影推荐系统
数据文件: u.data(userid itemid rating timestamp) u.item(主要使用 movieid movietitle) 数据操作 把u.data导入RDD, t ...
- 基于Mahout的电影推荐系统
基于Mahout的电影推荐系统 1.Mahout 简介 Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域 ...
- 基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统. 代码移植自https://github.com/chengstone/movie_recommender. 原作者用了tf1.0实现了这个基于movie ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
随机推荐
- Java生鲜电商平台-IntelliJ IDEA 最新注册码,亲测可用
2019年IntelliJ IDEA 最新注册码(截止到2020年3月11日) 操作步骤: 第一步: 修改 hosts 文件 ~~~ 在hosts文件中,添加以下映射关系: 0.0.0.0 acco ...
- PHP fread 文件系统函数
定义和用法 fread - 读取文件(可安全用于二进制文件) 版本支持 PHP4 PHP5 PHP7 支持 支持 支持 语法 fread ( resource $handle , int $lengt ...
- docker挡板程序实现启动多个实例进程
启动服务: docker-compose restart
- xwiki 知识管理系统
搭建一个知识管理平台, 用于知识库管理/规范管理, 可以作wiki, 可以将word/excel等导入进去, 支持全文搜索, 可以记周报, 会议纪要. 现在有很多文档管理系统, 比如阿里的语雀.腾讯的 ...
- 中文代码之Django官方入门:建立模型
参考编写你的第一个 Django 应用,第 2 部分 创建项目后,首先用中文命名应用: $ python3 manage.py startapp 投票 之后在models.py建立模型,其他各种相关配 ...
- Mysql8.0主从复制搭建,shardingsphere+springboot+mybatis读写分离
1.安装mysql8.0 首先需要在192.167.3.171上安装JDK. 下载mysql安装包,https://dev.mysql.com/downloads/,找到以下页面下载. 下载后放到li ...
- 图Lasso求逆协方差矩阵(Graphical Lasso for inverse covariance matrix)
图Lasso求逆协方差矩阵(Graphical Lasso for inverse covariance matrix) 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/ka ...
- nginx代理ambassador出现426错误
现在ambassador文档啃得差不多了.进入实战阶段. 一开始,就偶遇426错误. 网络结构大致如下: 浏览器访问nginx, nginx代理到k8s内的ambassador, ambassador ...
- axios+vue实现动态渲染员工数据+数据是对象
<style> table{ width: 600px; margin: 0 auto; text-align: center; border-collapse: collapse; /* ...
- tomcat快速入门
简介 Tomcat 是什么 Tomcat 是由 Apache 开发的一个 Servlet 容器,实现了对 Servlet 和 JSP 的支持,并提供了作为Web服务器的一些特有功能,如Tomcat管理 ...