Spark1——介绍
1、Spark是什么
Spark是一个用来实现快速而通用的集群计算的平台。
2、Spark是一个大一统的软件栈
Spark项目包含多个紧密集成的组件。首先Spark的核心是一个对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。
Spark的个组件如下图所示:
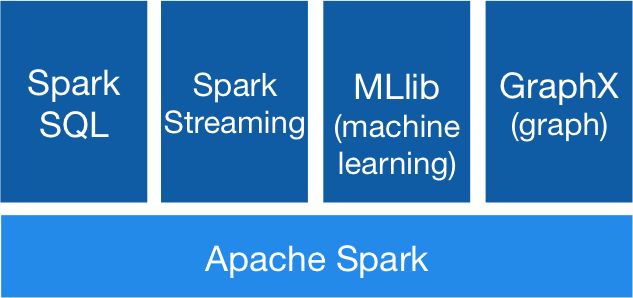
- Apache Spark 也就是Spark的核心部分,也称为Spark Core,这个部分实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互模块,还包含了对弹性分布式数据集(RDD)的API定义。
- Spark SQL是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者HQL来查询数据。
- Spark Streaming 是Spark提供的对实时数据进行流式计算的组件。比如生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是消息流
- MLlib这是一个包含了常见机器学习功能的程序库,包括分类、回归、聚类、协同过滤等
- GraphX是用来操作图的程序库,可以进行并行的图计算。
3、Spark的核心概念
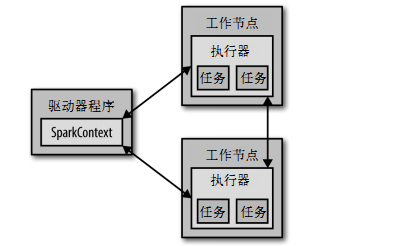
从上层来看,每个Spark应用都由一个驱动器程序来发起集群上的并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接,当Spark shell启动时已自动创建了一个SparkContext对象。
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, ))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
这里的sc变量,就是自动创建的SparkContext对象。通过它就可以来创建RDD,调用sc.textFile()来创建一个代表文件各行文本的RDD。
通过RDD我们就可以在这些行上进行各种操作,通常驱动器程序要管理多个执行器节点。比如,如果我们在集群上运行输出操作,那么不同的节点就会统计文件不同部分的行数。
4、初始化SparlContext
一旦完成了应用与Spark的连接,接下来就需要在程序中导入Spark包并创建SparkContext.我们可以通过先创建一个SparkConf对象来配置应用,然后基于这个SparkConf来创建一个Sparktext对象。
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
这里创建了SparkContext的最基础的方法,只需要传递两个参数:
- 应用名:这里使用的是"wordcount ",当连接到一个集群的时候,这个值可以帮助我们在集群管理器的用户界面中找到你的应用,这是这个程序运行后的集群管理器的截图

- 集群URL:告诉Spark如何连接到集群上,这里使用的是local,这个特殊的值可以让Spark运行在单机单线程上而无需连接到集群上
Spark1——介绍的更多相关文章
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- spark1.4.1 启动过程
今天稍微没那么忙了,趁着这个时间,准备把spark的启动过程总结一下(),分享给大家.现在使用的spark1.4.1版本 当然前提是你已经把spark环境搭建好了. 1.我们启动spark的时候一般会 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- spark1.2.0安装
standalone 安装SCALA 下载.解压.加入环境变量 安装spark1.2.0 下载.解压.加入环境变量 tar zxvf spark--bin-.tgz export SPARK_HOME ...
- DIP开放计算平台介绍
随着平台业务的发展,依赖于Portal(Web)构建的服务架构已逐渐不能满足现有的一些复杂需求(如:使用Hive SQL无法完成计算逻辑),而且对于一些具备编程能力的程序员或数据分析师而言,能够自主控 ...
- spark1.3.1使用基础教程
spark可以通过交互式命令行及编程两种方式来进行调用: 前者支持scala与python 后者支持scala.python与java 本文参考https://spark.apache.org/doc ...
- 安装spark1.3.1单机环境
本文介绍安装spark单机环境的方法,可用于测试及开发.主要分成以下4部分: (1)环境准备 (2)安装scala (3)安装spark (4)验证安装情况 1.环境准备 (1)配套软件版本要求:Sp ...
- Spark1.0.0 学习路径
2014-05-30 Spark1.0.0 Relaease 经过11次RC后最终公布.尽管还有不少bug,还是非常令人振奋. 作为一个骨灰级的老IT,经过非常成一段时间的消沉,再次被点燃 ...
- Spark1.3.0安装
之前在用Hadoop写ML算法的时候就隐约感觉Hadoop实在是不适合ML这些比较复杂的算法.记得当时写完kmeans后,发现每个job完成后都需要将结果放在HDFS中,然后下次迭代的时候再从文件中读 ...
随机推荐
- Design Principles (设计原则)
这是我在2018年4月写的英语演讲稿,可惜没人听得懂(实际上就没几个人在听). 文章的内容是我从此前做过的项目中总结出来的经验,从我们的寝室铃声入手,介绍了可扩展性.兼容性与可复用性等概念,最后提出良 ...
- web项目超时方案
1. 场景描述 平台使用的Greenplum(内核是postgresql8.2)集群存储大数据量数据(每天一个表大概3亿),因为数据量比较大,所以在使用上有些限制,一是操作限制:二是不限制,但是到一定 ...
- CAD2014学习笔记-图纸布局和打印输出
基于 虎课网huke88.com CAD教程 图纸设计规范:施工图 封面设计:地点.名称.设计人 目录设计:施工图编号.名称.意义.对应页数.注释.图号序号:包括平面.立面.大样图.施工图 设计说明/ ...
- 星际旅行(欧拉路,欧拉回路)(20190718 NOIP模拟测试5)
瞎搞了一个ans+=du*(du-1)/2 wa20分,好桑心(话外音:居然还有二十分,出题人太周到了) 还是判欧拉路 题解没太仔细想,感觉还是kx的思路明白 具体就是:因为每条边要走两遍,可以把一条 ...
- linux 定时任务 crontabs 安装及使用方法
boom 安装 crontab yum install crontabs centos7 自带了我没有手动去装 启动/关闭 service crond start // 启动服务 service cr ...
- 【题解】搬书-C++
搬书 Description 陈老师桌上的书有三堆,每一堆都有厚厚的一叠,你想逗一下陈老师,于是你设计一个最累的方式给他,让他把书 拿下来给同学们.若告诉你这三堆分别有i,j,k本书,以及每堆从下到上 ...
- C# 与 JS 之间传值在 cshtml页面中
@{ string It = "sss"; ; } @functions{ string Mod = "ajssaioi"; public string Itm ...
- matlab考试重点详解
此帖是根据期末考试复习重点补充完成, 由于使用word编辑引用图片和链接略有不便, 所以开此贴供复习及学习使用.侵删 复习要点 第一章 Matlab的基本概念,名称的来源,基本功能,帮助的使用方法 1 ...
- Excel催化剂开源第9波-VSTO开发图片插入功能,图片带事件
图片插入功能,这个是Excel插件的一大刚需,但目前在VBA接口里开发,如果用Shapes.AddPicture方法插入的图片,没法对其添加事件,且图片插入后需等比例调整纵横比例特别麻烦,特别是对于插 ...
- HDFS的HA(高可用)
HDFS的HA(高可用) 概述 (1)实现高可用最关键的策略是[消除单点故障].HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA. (2)Hadoop2.0 之 ...