Storm初识(1)
在Storm集群中,有两类节点:主节点 master node 和工作节点 worker nodes。
主节点运行着一个叫做Nimbus的守护进程。这个守护进程负责在集群中分发代码,为工作节点分配任务,并监控故障。
Supervisor守护进程作为拓扑的一部分运行在工作节点上。一个Storm拓扑结构在不同的机器上运行着众多的工作节点。
因为Storm在Zookeeper或本地磁盘上维持所有的集群状态,守护进程可以是无状态的而且失效或重启时不会影响整个系统的健康。
- Nimbus: 责资源分配和任务调度
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程
- Work:运行具体处理组件逻辑的进程
- Task: worker中每一个spout/bolt的线程称为一个task
Hadoop 与 Storm 比较
- 数据来源:Hadoop 处理的是HDFS上TB级别的数据(历史数据),Storm 是处理的是实时新增的某一笔数据(实时数据),处理一些简单的业务逻辑;
- 处理过程:Hadoop 是分 map 阶段到 reduce 阶段,Storm 是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT);
- 是否结束:Hadoop 最后是要结束的,Storm 是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始,(SPOUT一直循环nextTuple()方法,BOLT当有接受到消息就调用execute(Tuple input)方法);
- 处理速度:Hadoop 是以处理HDFS上TB级别数据为目的,处理速度慢,Storm 是只要处理新增的某一笔数据即可,可以做到很快;
- 适用场景:Hadoop 是在要处理批量数据时用的,不讲究时效性,Storm 是要处理某一新增数据时用的,要讲时效性;
Storm的设计思想
Storm是对流Stream的抽象,流是一个不间断的无界的连续tuple,注意Storm在建模事件流时,把流中的事件抽象为tuple即元组。
Storm将流中元素抽象为Tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,并且该value可以是基本类型,字符类型,字节数组等,当然也可以是其他可序列化的类型。
Storm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头称为Spout。
有了源头即spout也就是有了stream,那么该如何处理stream内的tuple呢。将流的状态转换称为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口)再将spout中流出的tuple导向特定的bolt,然后bolt对导入的流做处理后再导向其他bolt。
以上处理过程统称为Topology即拓扑。拓扑是storm中最高层次的一个抽象概念,它可以被提交到storm集群执行,一个拓扑就是一个流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt(这就意味着不需要我们手工拉管道,只要预先订阅,spout就会将流发到适当bolt上)。
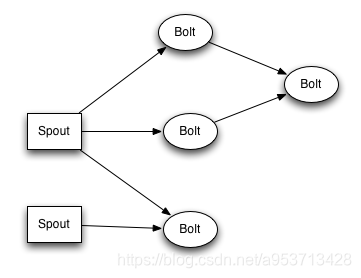
拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
Storm的基础概念
- Topology : 相当于一个业务流程项目,相当于hadoop中MapperReduce中的job
- Stream:消息流,是一个没有边界的tuple序列,这些tuples会被以一种分布式的方式并行地创建和处理
- tuple:就是数据的单位,需要每一个需要处理的数据的封装在tuple中
- Spouts 消息源,是消息生产者,他会从一个外部源读取数据并向topology里面面发出消息:tuple
- Bolts 消息处理者,所有的消息处理逻辑被封装在bolts里面,处理输入的数据流并产生新的输出数据流,可执行过滤,聚合,查询数据库等操作
- Task 每一个Spout和Bolt会被当作很多task在整个集群里面执行,每一个task对应到一个线程
- Stream groupings 消息分发策略,定义一个Topology的其中一步是定义每个tuple接受什么样的流作为输入,stream grouping就是用来定义一个stream应该如何分配给Bolts们
tream groupings(消息分发策略)
定义一个topology的其中一步是定义每个bolt接收什么样的流作为输入。stream grouping就是用来定义一个stream应该如何分配数据给bolts上面的多个tasks。
Storm里面有7种类型的stream grouping:
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts里的一个task, 而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
Storm集群安装
官方集群安装的参考文档:
http://storm.apache.org/releases/1.2.2/Setting-up-a-Storm-cluster.html
大致内容如下:
Storm集群依赖于zookeeper做配置中心,所以安装之前确保zookeeper已经安装并正常启动。
1.去官网下载最新的 storm:http://storm.apache.org/index.html
2.解压:tar -zxvf apache-storm-1.2.2.tar.gz storm
3.修改配置文件:
conf/storm.yaml
#zookeeper配置中心
storm.zookeeper.servers:
- "hadoopmaster"
- "hadoopslaver1"
- "hadoopslaver2"
#主节点的候选节点
nimbus.seeds: ["hadoopmaster"]
#集群所需要的运行时数据存放目录
storm.local.dir: "usr/local/storm/data"
#工作节点运行时的端口
supervisor.slots.ports:
- 6700
- 6701
- 6702
#主节点默认机器
nimbus.host: "hadoopmaster"
#指定nimbus启动JVM最大可用内存大小
work.childopts: "-Xms1024"
以上为主要配置项,配置完成以后保存,记得创建数据目录data。
然后分发给其余的几台工作主机:
scp -r storm hadoop@hadoopslaver:/usr/local/
4.配置环境变量:
export STORM_HOME=/usr/local/storm
export PATH=.:$STORM_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$PATHc
别忘了同步到其他节点。
6.我们可以启动集群:
启动主节点:
cd storm/bin
nohup storm nimbus&
启动UI界面:
nohup storm ui&
启动工作节点,两台机器分别执行:
cd storm/bin
nohup storm supervisor&
注意:bin/storm命令 有一些可用参数,上面的storm后面的命令即为他的参数项,不知道参数是什么,你输入storm命令就会有提示。
上面已经启动了UI界面,UI界面默认的端口号为8080,我们可以查看一下:
hadoopmaster:8080

Storm常用命令
提交任务命令格式:
storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称]
#如下命令表示加载 my_code.jar 中的 com.test.MyTopology 类, 传入arg1 arg2 arg3这三个参数
storm jar my_code.jar com.test.MyTopology arg1 arg2 arg3
杀死任务命令格式 :
storm kill [拓扑名称] -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
#{toponame}为Topology提交到Storm集群时指定的Topology任务名称
storm kill {topoName}
停用任务命令格式:
storm deactivte [拓扑名称]
storm deactivte {topoName}
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
启用任务命令格式 :
storm activate[拓扑名称]
storm activate {topoName}
重新部署任务命令格式 :
storm rebalance [拓扑名称]
storm rebalance {topoName}
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配worker,并重启拓扑。
Storm初识(1)的更多相关文章
- Storm学习笔记 - Storm初识
Storm学习笔记 - Storm初识 1. Strom是什么? Storm是一个开源免费的分布式计算框架,可以实时处理大量的数据流. 2. Storm的特点 高性能,低延迟. 分布式:可解决数据量大 ...
- 初识storm
storm是Twitter开发的一个开源的分布式实时计算系统,可以简单可靠的处理大量的数据流.storm有很多的应用场景,如实时分析,在线机器学习,持续计算,分布式RPC,ETL等等.storm支持水 ...
- 初识中间件Kafka
初识中间件Kafka Author:SimplelWu 什么是消息中间件? 非底层操作系统软件,非业务应用软件,不是直接给最终用户使用的,不能直接给客户带来价值的软件统称为中间件 关注于数据的发送和接 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
随机推荐
- python进阶--字典排序
zip()函数 sorted() 要求对字典中,按值的大小排序 解决方案: 利用zip函数 zip函数介绍: zip函数可以将可迭代对象打包成一个个元组,在python3中返回一个对象,在python ...
- nodejs中文乱码问题
node.js暂时不支持GBK或gb2312,所以编程文件(js)需要修改为utf-8格式. 另外如需要返回html代码,在 writeHead 方法中加入 "charset=utf-8&q ...
- Greenplum高可用真的高吗?
目录 1. 问题描述 2. 解决方案 @ 1. 问题描述 在项目中使用了Greenplum做分析型数据库,Greenplum自身已经提供了高可用方案,Master节点提供Sdanby备用节点,Segm ...
- infiniband 网卡驱动安装
硬件:Mellanox InfiniBand,主要包括 HCA(主机通道适配器)和交换机两部分软件:CentOS 6.4MLNX_OFED_LINUX-2.1-1.0.0-rhel6.4-x86_64 ...
- python实现DFA模拟程序(附java实现代码)
DFA(确定的有穷自动机) 一个确定的有穷自动机M是一个五元组: M=(K,∑,f,S,Z) K是一个有穷集,它的每个元素称为一个状态. ∑是一个有穷字母表,它的每一个元素称为一个输入符号,所以也陈∑ ...
- Junit简单的案例
Calculator: public class Calculator { public double add(double number1, double number2) { return num ...
- BZOJ4152 The Captain(dijkstra+巧妙建图)
BZOJ4152 The Captain 题面很简洁: 给定平面上的n个点,定义(x1,y1)到(x2,y2)的费用为min(|x1-x2|,|y1-y2|),求从1号点走到n号点的最小费用. 很明显 ...
- [记录]FIO测试磁盘iops性能
FIO测试磁盘iops性能 1.SATA和SAS盘原生IOPS如下: 2.RAID磁盘阵列对应的写惩罚级别: 3.计算功能性IOPS公式如下: 功能性 IOPS=(((总原生 IOPS×写 %))/( ...
- python菜鸟入门知识
第二章 入门 2.1 输出 2.1.1print() 输出 print(12+21) print((12+21)*9) print(a) # 注意a不可以加引号 2.2变量 1.变量由字母,数字,下划 ...
- Spring_简单入门(学习笔记1)
Spring是一个分层的JavaSE/EE full-stack(一站式) 轻量级开源框架. 具体介绍参考 一:IoC(Inversion of Control)控制反转,将创建对象实例反转给spri ...