相克军_Oracle体系_随堂笔记005-Database buffer cache
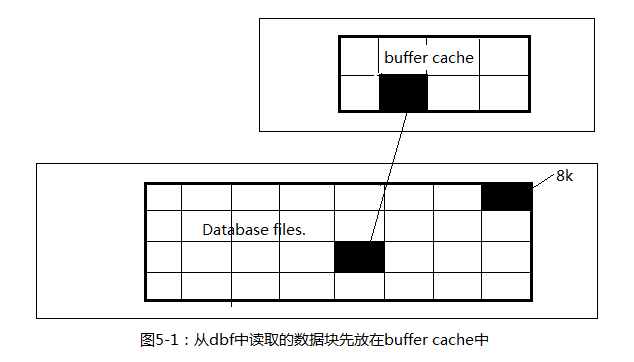

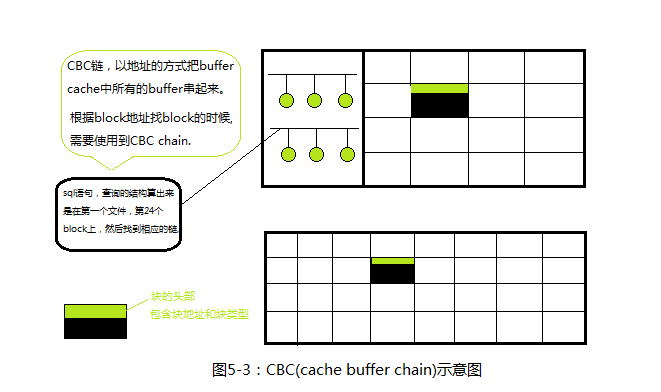

SQL> show parameter writer NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_writer_processes integer 1
SQL> alter system set db_writer_processes = 2 scope=spfile;
--DBWn数量一般设定是服务器核心数/8.
alter system set db_cache_size=200m scope=both;
设置顺序:
sga_max_size
sga_target
db_cache_size
在OLTP系统中,buffer cache的大小一般设置为sga_max_size的2/3.
DB_CACHE_SIZE = SGA_MAX_SIZE/2 ~ SGA_MAX_SIZE*2/3
使用advice来确认buffer cache的大小
根据语句查询buffer cache该设置多大合适。减少I/O(物理读次数)
平日注意收集积累一些常用的语句》。
buffer header:
SQL> desc x$bh state:0~8
0,free
1,XCUR
2,SCUR
3,CR
4,READ 从block写入buffer的那个过程
5,MREC
6,IREC
7,write
8,pi SQL> select distinct state from x$bh;
非RAC环境下,current永远等于xcur。
RAC下,有scur
cr块被构造后被读出,就马上没意义了。。马上就可以被覆盖了。。
要修改一个块,只能修改current块。
Q:查看一个对象占用了多少不同状态的buffer?
select
o.object_name,
decode(state,0,'free',1,'xcur',2,'scur',3,'cr',4,'read',5,'mrec',
6,'irec',7,'write',8,'pi') state,
count(*) blocks
from x$bh b, dba_objects o
where b.obj = o.data_object_id
and o.object_name = 'T2'
group by o.object_name, state
order by blocks desc
alter system flush buffer_cache;
select distinct object_name, dbarfil, dbablk from x$bh a, dba_objects b
where a.obj=b.object_id and object_name='T2';
select object_name, dbarfil, dbablk from x$bh a, dba_objects b
where a.obj=b.object_id and object_name='T2';
select
o.object_name,
decode(state,0,'free',1,'xcur',2,'scur',3,'cr',4,'read',5,'mrec',
6,'irec',7,'write',8,'pi') state,
count(*) blocks
from x$bh b, dba_objects o
where b.obj = o.data_object_id and state<>0
group by o.object_name, state
order by blocks asc;
select
obj object,
dbarfil file#,
dbablk block#,
tch touches
from x$bh
where tch>10
order by
tch asc;
select object_name, dbarfil, dbablk from x$bh a, dba_objects b
where a.obj=b.object_id and dbarfil=1 and dbablk=287
select sum(blocks) from dba_data_files;
select decode(state,0,'FREE',1,decode(lrba_seq,0,'AVAILABLE','BEING USED'),3,'BEING USED', state) "BLOCK STATUS",count(*)
from x$bh
group by decode(state,0,'FREE',1,decode(lrba_seq,0,'AVAILABLE','BEING USED'),3,'BEING USED',state);
BLOCK STATUS COUNT(*)
select sum(pct_bufgets) "Percent"
from (select rank() over (order by buffer_gets desc) as rank_bufgets, to_char(100 * ratio_to_report(buffer_gets) over(),'999.99')pct_bufgets from v$sqlarea)
where rank_bufgets < 11;
select disk_reads, substr(sql_text,1,4000)
from v$sqlarea
order by disk_reads asc;
iostat 1 10
vmstat 1 10
mpstat 1 10
mpstat -P 0 1
mpstat -P 1 1
top
free
相克军_Oracle体系_随堂笔记005-Database buffer cache的更多相关文章
- 相克军_Oracle体系_随堂笔记002-基础
1.常见的Oracle生产库环境: 图2-1可以说是标准的生产库环境,处处体现了冗余,有效防止了单点故障.这就是HA(高可用) 而且冗在某种条件下还可以去掉,平常实现同时运行提供服务,如果一台坏掉,另 ...
- 相克军_Oracle体系_随堂笔记001-概述
一.Oracle官方支持 1.在线官方文档 http://docs.oracle.com/ 2.metalink.oracle.com,如今已经改成:http://support.oracle.com ...
- 相克军_Oracle体系_随堂笔记003-体系概述
1.进程结构图 对Oracle生产库来讲,服务器进程(可以简单理解是前台进程)的数量远远大于后台进程.因为一个用户进程对应了一个服务器进程. 而且后台进程一般出问题几率不大,所以学习重点也是服务器进程 ...
- 相克军_Oracle体系_随堂笔记004-shared pool
本章主要阐述SGA中的shared pool. Shared pool { 1.free 2.library cache(缓存sql语句及其执行计划) 3.row cache(数据字典缓存) } ...
- 相克军_Oracle体系_随堂笔记006-日志原理
简单来说,学习Oracle数据库就两个目标: 保证数据库数据的一致性: 提高数据库的性能(这个和日志没关系). 日志的功能: 只是保证数据库数据的一致性: 1.Oracle日志原理 ...
- 相克军_Oracle体系_随堂笔记007-PGA
实际工作中,Oracle中有两个很重要:Server Process 和 PGA. PGA内存作用和构成 1.PGA作用 2.PGA构成 1)private SQL area 2)Sess ...
- 相克军_Oracle体系_随堂笔记008-存储结构
控制文件.数据文件.日志文件 放在存储上. 参数文件:数据库启动时读取,并不关闭,但是启动过后丢了也没事.一般放在服务器上. $ORACLE_HOME/dbs下 备份文件{ 控制 ...
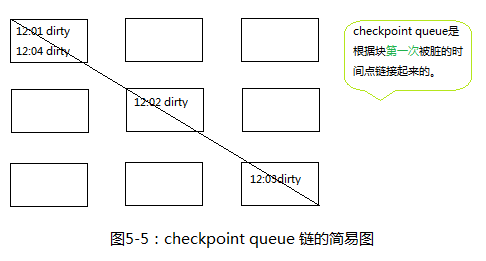
- 相克军_Oracle体系_随堂笔记009-检查点队列
1.检查点队列 checkpoint queue RBA 日志块地址 redo block address LRBA 第一次被脏的地址 HRBA 最近一次被脏的地址 on disk rba 重做日志( ...
- 相克军_Oracle体系_随堂笔记010-SCN
1.SCN的意义?system change number 时间 先后.新旧 select dbms_flashback.get_system_change_number, SCN_TO ...
随机推荐
- >hibernate初认识
一.什么是hibernate 1.hibernate是java领域的一款开源的ORM框架技术 2.hibernate对JDBC进行了非常轻量级的封装(使用了反射机制+配置或注解) 二.hibernat ...
- 下载apk文件浏览器会直接打开并显示乱码的问题
今天同事反映他的apk文件在自己的老项目中下载有问题:下载apk文件浏览器会直接打开并显示乱码,在别的项目中就没有问题. 后分析response的content-type发现,老项目的类型是text/ ...
- jquery的each
each()方法能使DOM循环结构简洁,不容易出错.each()函数封装了十分强大的循环功能,使用也很方便,它可以循环一维数组.多维数组.DOM, JSON 等等在javaScript开发过程中使用$ ...
- GIT的认识
说实话,在听到小伙伴们都说赶紧做作业的时候很茫然,连一点头绪都没有,根本不知道从何入手,但不能因为不会就不去做,于是还是拿起手机,找到小伙伴商量着做着,虽然等的过程很焦急,但还是注册成功了.而开始写对 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- 飞流直下的精彩 -- 淘宝UWP中瀑布流列表的实现
在淘宝UWP中,搜索结果列表是用户了解宝贝的重要一环,其中的图片效果对吸引用户点击搜索结果,查看宝贝详情有比较大的影响.为此手机淘宝特意在搜索结果列表上采用了2种表现方式:一种就是普通的列表模式,而另 ...
- 作业三: 代码规范、代码复审、PSP
分) 对于是否需要有代码规范,请考虑下列论点并反驳/支持: 这些规范都是官僚制度下产生的浪费大家的编程时间.影响人们开发效率, 浪费时间的东西. 我是个艺术家,手艺人,我有自己的规范和原则. 规范不能 ...
- Hibernate 延迟加载原理
如何简单的理解延迟加载?开发中常见的org.hibernate.LazyInitializationException no session错误又是怎么产生的?下面通过一个简单的例子来解析一下 ...
- 干货!表达式树解析"框架"(3)
最新设计请移步 轻量级表达式树解析框架Faller http://www.cnblogs.com/blqw/p/Faller.html 这应该是年前最后一篇了,接下来的时间就要陪陪老婆孩子了 关于表达 ...
- .NET 的 Debug 和 Release build 对执行速度的影响
这篇文章发布于我的 github 博客:原文 在真正开始讨论之前先定义一下 Scope. 本文讨论的范围限于执行速度,内存占用什么的不在评估的范围之内. 本文不讨论算法:编译器带来的优化基本上属于底层 ...