[Spark] 05 - Spark SQL
关于Spark SQL (Structured Query Language),首先会想到一个问题:Apache Hive vs Apache Spark SQL – 13 Amazing Differences
Hive has been known to be the component of Big data ecosystem where legacy mappers and reducers are needed to process data from HDFS whereas Spark SQL is known to be the component of Apache Spark API which has made processing on Big data ecosystem a lot easier and real-time.
原理解析
Ref: https://www.bilibili.com/video/av27076260/?p=9
小比较:
Hive: SQL --> map/reduce,Hive on Spark 就是把map/reduce直接换为Spark。
Spark SQL: SQL integrated in Spark;可直接读取Hive的保存的文件,兼容Hive。
架构图:
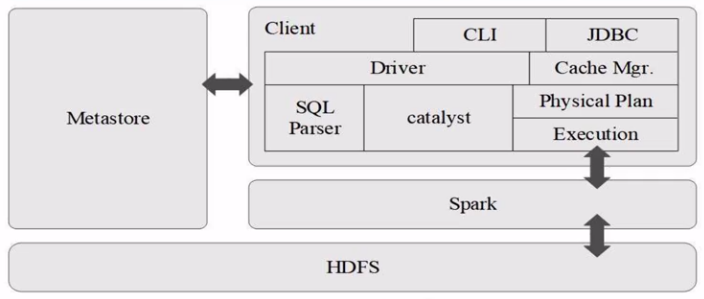
转化过程:
Catalyst's general tree transformation framework
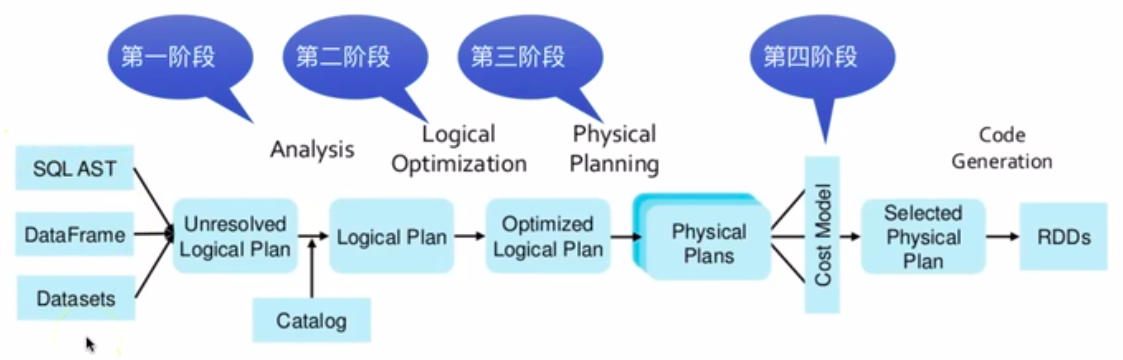
(一)SQL Parser 转化为 Abstract Syntax Tree。
(二)逻辑最佳化,只保留需要的部分:
Parquet格式时,将字符串透过字典编码压缩成整数,缩小资料量;
RDBMS时,将筛选推到资料源端。
(三)可执行的物理计划,并产生 JVM bytecode。
智能选择 “Broadcast Join” or "Shuffle Join" 来减少网络流量
低阶优化,减少比较消耗的物件。
优化示例:
def add_demographics(events):
u = sqlCtx.table("users")
events.join(u, events.user_id) == u.user_id).withColumn("city", zipToCity(df.zip)) events = add_demographics(sqlCtx.load("/data/events", "parquet"))
training_data = events.where(events.city == "New York").select(events.timestamp).collect()
抽象语法树:
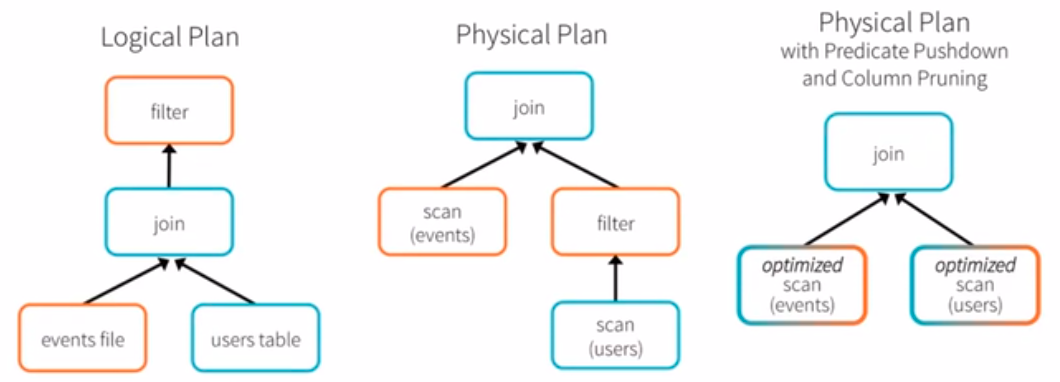
Spark SQL DataFrame
Dataframe作为新的数据结构,可以操作更为细粒度。(能看到RDD内部的结构化信息)
Spark SQL编程使用的是:SparkSession 接口,类似之前的SparkContext 的地位。
“关系型数据库” 与 "机器学习" 的结合。
基本概念
一、SparkSession
PySpark交互环境下,会自动生成 SparkSession 和 SparkContext。
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
二、DataFrame
读取文件
/usr/local/spark/examples/src/main/resources/ 文件夹下有实例文件以供实验。
df = spark.read.text("people.txt")
df = spark.read.format("text").load("people.txt") # 等价的方式
df = spark.read.json("people.json")
df = spark.read.parquet("people.parquet")
df.show()
从HDFS中读取文件。
from pyspark.sql import SQLContext
sc = SparkContext()
sqlcontext = SQLContext(sc)
#format后面为告诉程序读取csv格式,load后面为hdfs地址,hdfs后面跟着hadoop的名字,然后文件目录(这块有点懵,如果报错,跟着报错查修)
data = sqlcontext.read.format("com.databricks.spark.csv").\
options(header="true",inferschema="true").\
load("hdfs://cdsw1.richstone.com/test1/5min.csv")
data.show(5)
result = data.groupBy("type").count().orderBy("count")
result.show()
保存文件
注意,最后 newpeople.json 是目录,有点意思。
peopleDF = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("json").save("file:///usr/local/spark/mycode/sparksql/newpeople.json")
除了如上的json,还支持 text, parquet 格式 的文件。
三、常用操作
df.printSchema() # 模式信息
df.select(df["name",df["age"]+1]).show() # age列的value都加1
df.filter(df["age"]>20).show()
df.groupBy("age").count().show()
df.sort(df["age"]).desc()).show()
df.sort(df["age"]).desc().df["name"].asc()).show() # 轻松实现 "二次排序"
RDD转换为DataFrame
一、利用"反射"机制推断RDD模式
使用反射来推断包含特定对象类型的RDD的模式(schema)。适用于写spark程序的同时,已经知道了模式,使用反射可以使得代码简洁。
结合样本的名字,通过反射读取,作为列的名字。
这个RDD可以隐式转化为一个SchemaRDD,然后注册为一个表。表可以在后续的sql语句中使用。
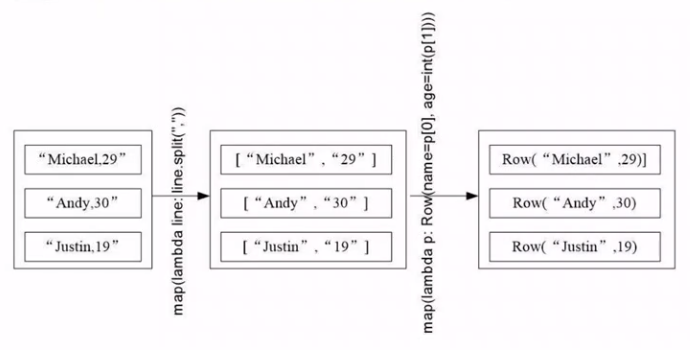
第一步、转化为Row形式的RDD格式
from pyspark.sql import Row
people = spark.sparkContext.textFile("..."). \
... map(lambda line: line.split(",")). \
... map(lambda p: Row(name=p[0], age=int(p[1])))
这里转换为了Row对象。
第二步、RDD格式 转换为 DataFrame
这里只是通过DataFrame的sql比较方便的查询了下数据而已。
注意理解:people是rdd,经过一次转变df后,又变回rdd,完成一次 “反射” 过程。
schemaPeople = spark.createDataFrame(people)
# 必须注册为临时表才能供下面的查询使用
schemaPeople.createOrReplaceTempView("people")
personDF = spark.sql("select name, age from people where age > 20")
# 再转化回RDD形式,而df的一行也就是p,其中包含name, age两个元素
personsRDD = personsDF.rdd.map(lambda p: "Name: " + p.name + "," + "Age: " + str(p.age))
personsRDD.foreach(print)
Output:
Name: Michael,Age: 29
Name: Andy,Age: 30
二、用编程方式去定义RDD模式
当无法提前获知数据结构时。
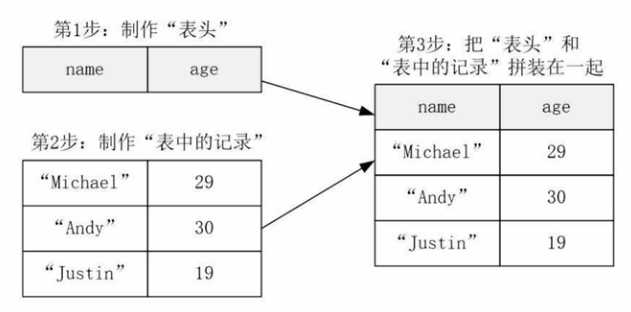
Jeff: 数据文件中没有说明“数据类型”,只是全都是字符串。而“反射”方案中的rdd是含有类型的。
from pyspark.sql.types import *
from pyspark.sql import Row # 生成"表头"
schemaString = "name age"
fields = [ StructField(field_name, StringType(), True) for field_name in schemaString.split(" ") ]
schema = StructType(fields) # 生成"记录"
lines = spark.sparkContext.textFile("file:/// ... people.txt")
parts = lines.map(lambda x: x.split(","))
people = parts.map(lambda p: Row(p[0], p[1].strip()))
#--------------------------------------------------------------
# 拼接“表头”和“记录”
schemaPeople = spark.createDataFrame(people, schema) schemaPeople.createOrReplaceTempView("people")
results = spark.sql("SELECT name,age FROM people")
results.show()
连接数据库
一、启动MySQL并创建数据
启动数据库。
service mysql start
mysql -u root -p
创建数据。
create database spark;
use spark; create table student (id int(4), name char(20), gender char(4), age int(4)); insert into student values(1, 'Xueqian', 'F', 23)
insert into student values(2, 'Weiliang', 'M', 24) select * from student
Spark调用MySQL,需安装JDBC驱动程序:mysql-connector-java-5.1.40.tar.gz
二、连接数据库

做个查询,测试一下连接。
>>> use spark;
>>> select * from student;
三、插入记录
(1) 设置“表头”

(2) 设置“记录”

转变为Row的形式
rowRDD = studentRDD.map(lambda p: Row(int(p[].strip()), p[].strip(), p[].strip(), int(p[].strip())))
(3) 拼接“表头”和“记录”
studentDF = spark.createDataFrame(rowRDD, schema)
(4) 写入数据库
DataFrame形式的数据 写入 数据库。
prop = {}
prop['user'] = 'root'
prop['password'] = ''
prop['driver'] = "com.mysql.jdbc.Driver"
# 构建好参数后
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)
(5) 查看效果

End.
[Spark] 05 - Spark SQL的更多相关文章
- [Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子
[Spark][Python][DataFrame][SQL]Spark对DataFrame直接执行SQL处理的例子 $cat people.json {"name":" ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark Shell启动时遇到<console>:14: error: not found: value spark import spark.implicits._ <console>:14: error: not found: value spark import spark.sql错误的解决办法(图文详解)
不多说,直接上干货! 最近,开始,进一步学习spark的最新版本.由原来经常使用的spark-1.6.1,现在来使用spark-2.2.0-bin-hadoop2.6.tgz. 前期博客 Spark ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Hive on Spark和Spark sql on Hive,你能分的清楚么
摘要:结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序. 本文分享自华为云社区<Hive on Spark和Spark sql o ...
- [Spark][Python]spark 从 avro 文件获取 Dataframe 的例子
[Spark][Python]spark 从 avro 文件获取 Dataframe 的例子 从如下地址获取文件: https://github.com/databricks/spark-avro/r ...
- [Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子:
[Spark][Python]Spark 访问 mysql , 生成 dataframe 的例子: mydf001=sqlContext.read.format("jdbc").o ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
随机推荐
- php安装mongo扩展(linux)
1.首先下载php的mongodb扩展 从http://pecl.php.net/package/mongodb这个网址下载mongodb的扩展源码包 2.解压安装包 tar zxf mongodb- ...
- Laravel框架内实现api文档:markdown转为html
前后端分离的工作模式于今是非常流行了,前后端工作的对接,就离开不了API文档的辅助. 根据自己以往的工作经历,以及了解的一些资讯,API文档的建立,无非以下几种方式: 1. word文档模板 2. 第 ...
- POST提交数据方式
application/x-www-form-urlencoded 这应该是最常见的 POST 提交数据的方式了.浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 app ...
- HDU 2516
题意略. 思路: 典型的斐波那契博弈,这里说一下结论: 如果先手面对的n不是斐波那契数,那么先手必胜:否则后手胜. 详见代码: #include<bits/stdc++.h> using ...
- c# timestamp转换datetime
一.Codes class Program { static void Main(string[] args) { ); } public static DateTime UnixTimeStampT ...
- Salesforce LWC学习(五) LDS & Wire Service 实现和后台数据交互 & meta xml配置
之前的几节都是基于前台变量进行相关的操作和学习,我们在项目中不可避免的需要获取数据以及进行DML操作.之前的内容中也有提到wire注解,今天就详细的介绍一下对数据进行查询以及DML操作以及Wire S ...
- SpringMVC中的generator
引言 今天在做一个原生的spring项目的时候碰到一个非常好用的代码自动生成器,叫做generator,主要是运用于mybatis中的代码生成,它可以生成mapper的映射xml,model中的实体类 ...
- JOBDU 1108 堆栈的使用
之所以把这道题目贴出来的原因,是因为真的有几个地方要注意的 题目1108:堆栈的使用 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:10763 解决:3119 题目描述: 堆栈是一种基本的 ...
- CodeForces Round #498 div3
A: 题目没读, 啥也不会的室友帮我写的. #include<bits/stdc++.h> using namespace std; #define Fopen freopen(" ...
- FZU Tic-Tac-Toe -.- FZU邀请赛 FZU 2283
Problem L Tic-Tac-Toe Accept: 94 Submit: 184Time Limit: 1000 mSec Memory Limit : 262144 KB Pr ...