kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)
一、准备三台服务器,配置好主机名和ip地址
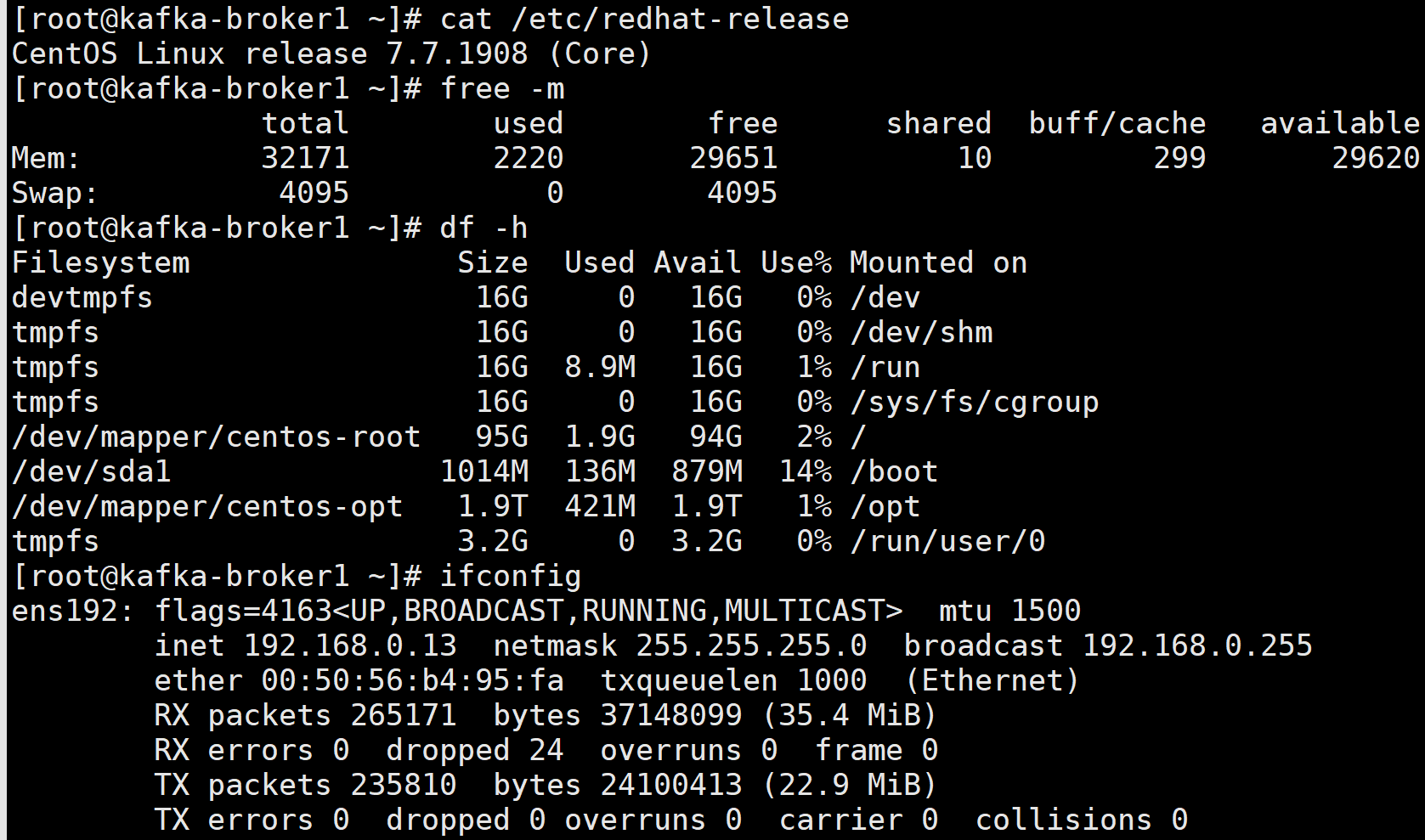

二、服务器初始化:包括安装常用命令工具,修改系统时区,校对系统时间,关闭selinux,关闭firewalld,修改主机名,修改系统文件描述符,优化内核参数,优化数据盘挂载参数
1、安装常用命令工具
yum install vim net-tools bash-completion wget unzip ntp bzip2 epel-release -y
2、修改系统时区,校对系统时间
timedatectl set-timezone Asia/Shanghai
ntpdate pool.ntp.org
3、关闭selinux
vim /etc/selinux/config
SELINUX=disabled
4、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
5、修改主机名
vim /etc/hostname
kafka-broker1
6、修改系统文件描述符大小
vim /etc/security/limits.conf
最后添加:
* soft nofile 655360
* hard nofile 655360
* soft nproc 655360
* hard nproc 655360
* soft memlock unlimited
* hard memlock unlimited
7.优化内核参数
vim /etc/sysctl.conf
最后添加:
vm.max_map_count = 655360
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_max_syn_backlog = 8192
net.core.netdev_max_backlog = 10000
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
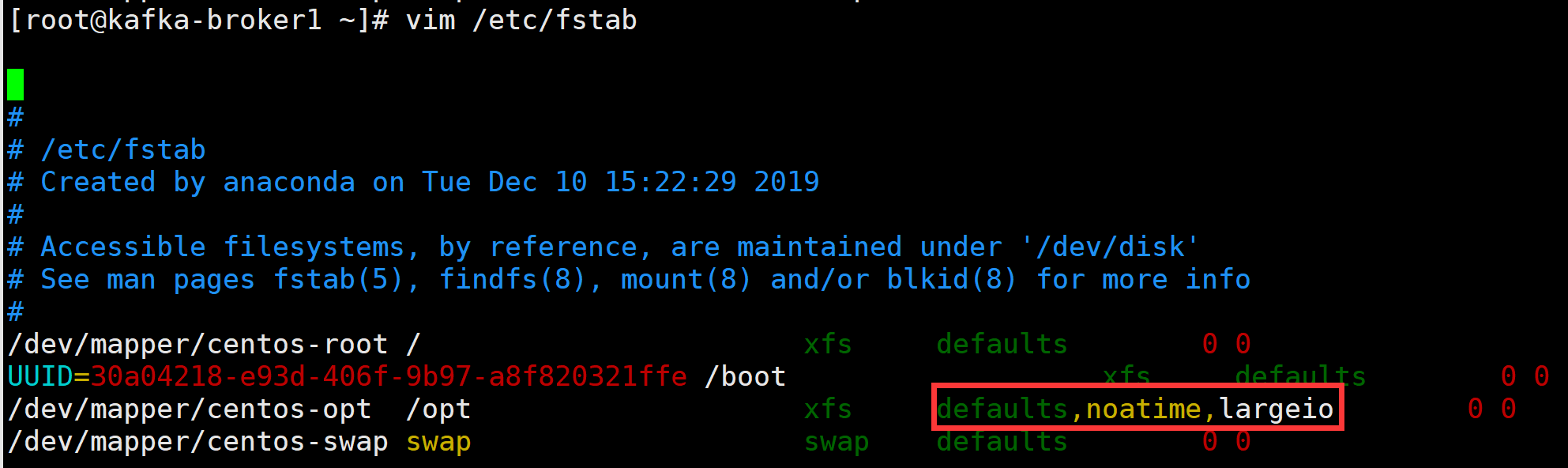
8.优化数据盘挂载参数,我的数据盘挂载在opt下,对应自己数据盘作相应调整
vim /etc/fstab
/dev/mapper/centos-opt /opt xfs defaults,noatime,largeio 0 0
9.重启系统使配置生效
init 6
三、安装zookeeper集群
1.因zookeeper和kafka需要java启动
首先安装jdk1.8环境
yum install java-1.8.0-openjdk-devel.x86_64 -y
2.Kakfa集群需要依赖ZooKeeper存储Broker、Topic等信息,所以我们先安装zookeeper集群
cd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
mv apache-zookeeper-3.5.6 zookeeper-3.5.6
3.修改zookeeper配置文件
cd zookeeper-3.5.6/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:
dataDir=/opt/zookeeper-3.5.6/data
末尾添加集群其他节点信息
server.1=192.168.0.13:2888:3888
server.2=192.168.0.14:2888:3888
server.3=192.168.0.15:2888:3888
4.添加zookeeper数据目录
创建/opt/zookeeper-3.5.6/data目录
mkdir /opt/zookeeper-3.5.6/data
在data目录里创建myid文件,写上该节点id

然后将opt下zookeeper-3.5.6目录上传到其他两个节点上
scp -r zookeeper-3.5.6 192.168.0.14:/opt
scp -r zookeeper-3.5.6 192.168.0.15:/opt
修改其他两个节点data下myid文件内容分别为2和3
5.启动zookeeper服务
三台节点分别启动zookeeper服务
/opt/zookeeper-3.5.6/bin/zkServer.sh start
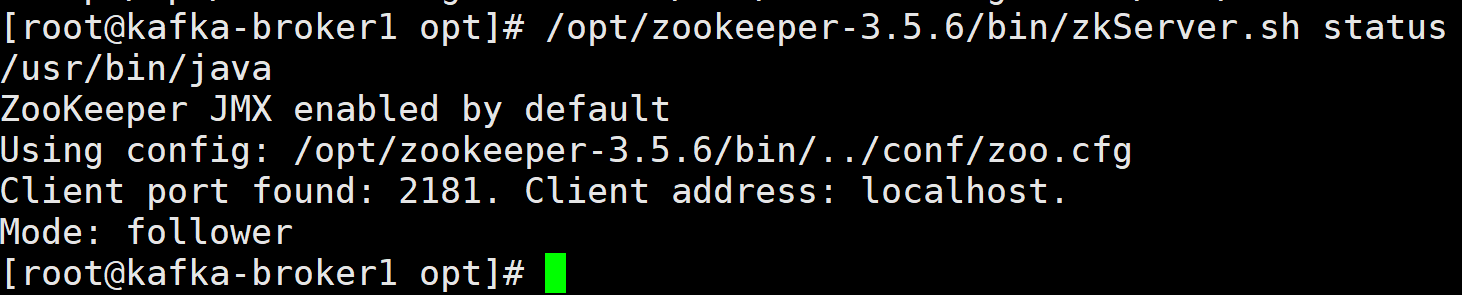
6.查看节点zookeeper状态
/opt/zookeeper-3.5.6/bin/zkServer.sh status
四、安装kafka集群
1.官网下载kafka
cd /opt
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz
tar -zxvf kafka_2.12-2.3.1.tgz
2.修改kafka配置文件
cd kafka_2.12-2.3.1/config
vim server.properties
修改以下参数
broker.id=1
host.name=192.168.0.13
listeners=PLAINTEXT://192.168.0.13:9092
delete.topic.enable=true
log.cleanup.policy=delete
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
auto.create.topics.enable=true
num.network.threads=24
num.io.threads=48
log.dirs=/opt/kafka_2.12-2.3.1/kafka-logs
num.partitions=3
zookeeper.connect=192.168.0.13:2181,192.168.0.14:2181,192.168.0.15:2181
3.优化调整kafka jvm堆内存大小
vim /opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh
export KAFKA_HEAP_OPTS="-Xmx5G -Xms5G"
4.开启kafka JMX监控
vim /opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh
export JMX_PORT="9999"

4.其他两台节点按照上面步骤同步安装kafka
5.三台节点分别启动kafka
/opt/kafka_2.12-2.3.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.3.1/config/server.properties
五、安装kafka-manager,方便管理kafka
1.下载kafka-manager源码
cd /opt
wget https://github.com/yahoo/kafka-manager/archive/2.0.0.2.zip
mv 2.0.0.2.zip kafka-manager-2.0.0.2.zip
2.解压zip包
unzip kafka-manager-2.0.0.2.zip
cd kafka-manager-2.0.0.2
3.yum安装sbt(因为kafka-manager需要sbt编译)
curl https://bintray.com/sbt/rpm/rpm > /etc/yum.repos.d/bintray-sbt-rpm.repo
yum install sbt -y
4.编译kafka-manager
./sbt clean dist
可能要等好几个小时。
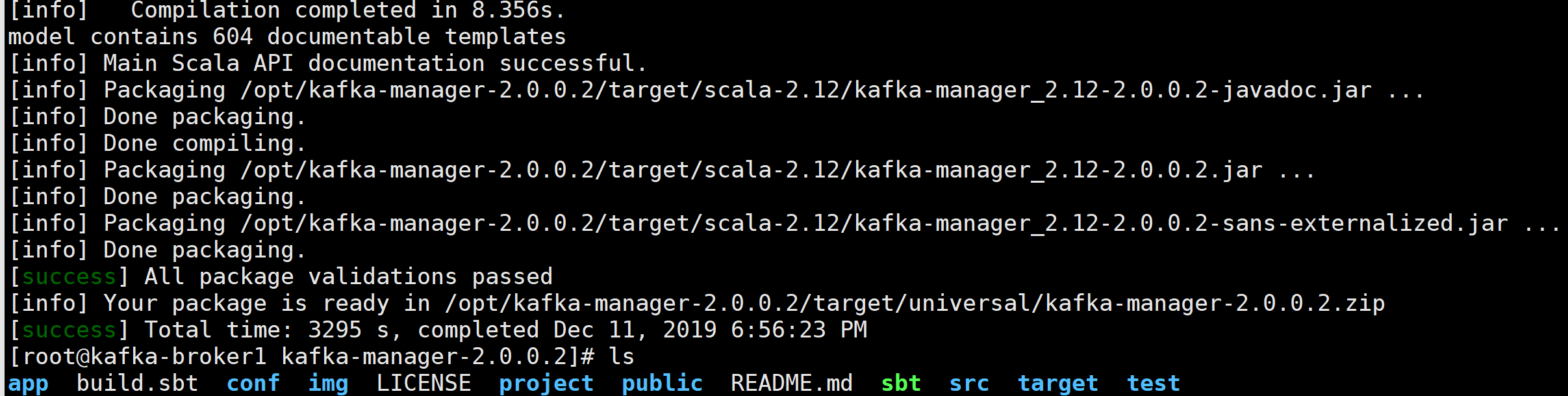
看到Your package is ready in /opt/kafka-manager-2.0.0.2/target/universal/kafka-manager-2.0.0.2.zip代表编译成功了。
5.然后将编译好的zip包拷贝到/opt下,并删除原来kafka-manager-2.0.0.2文件夹
cp /opt/kafka-manager-2.0.0.2/target/universal/kafka-manager-2.0.0.2.zip /opt
rm -rf kafka-manager-2.0.0.2
unzip kafka-manager-2.0.0.2.zip
cd kafka-manager-2.0.0.2
6. 修改kafka-manager配置
vim conf/application.conf
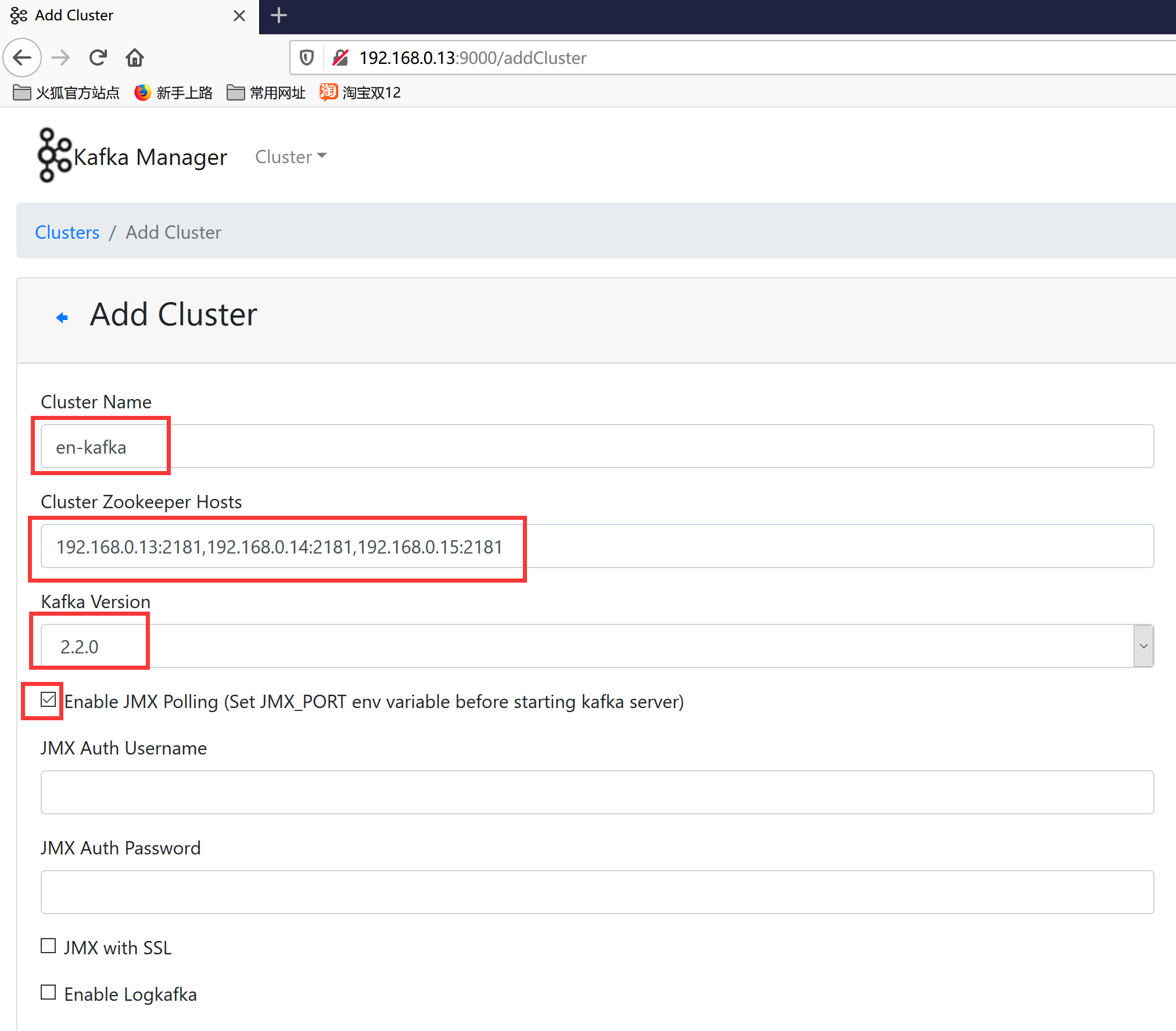
kafka-manager.zkhosts="192.168.0.13:2181,192.168.0.14:2181,192.168.0.15:2181"
7.启动kafka-manager
nohup /opt/kafka-manager-2.0.0.2/bin/kafka-manager &>>/dev/null &
8.用浏览器访问http://192.168.0.13:9000/,添加集群
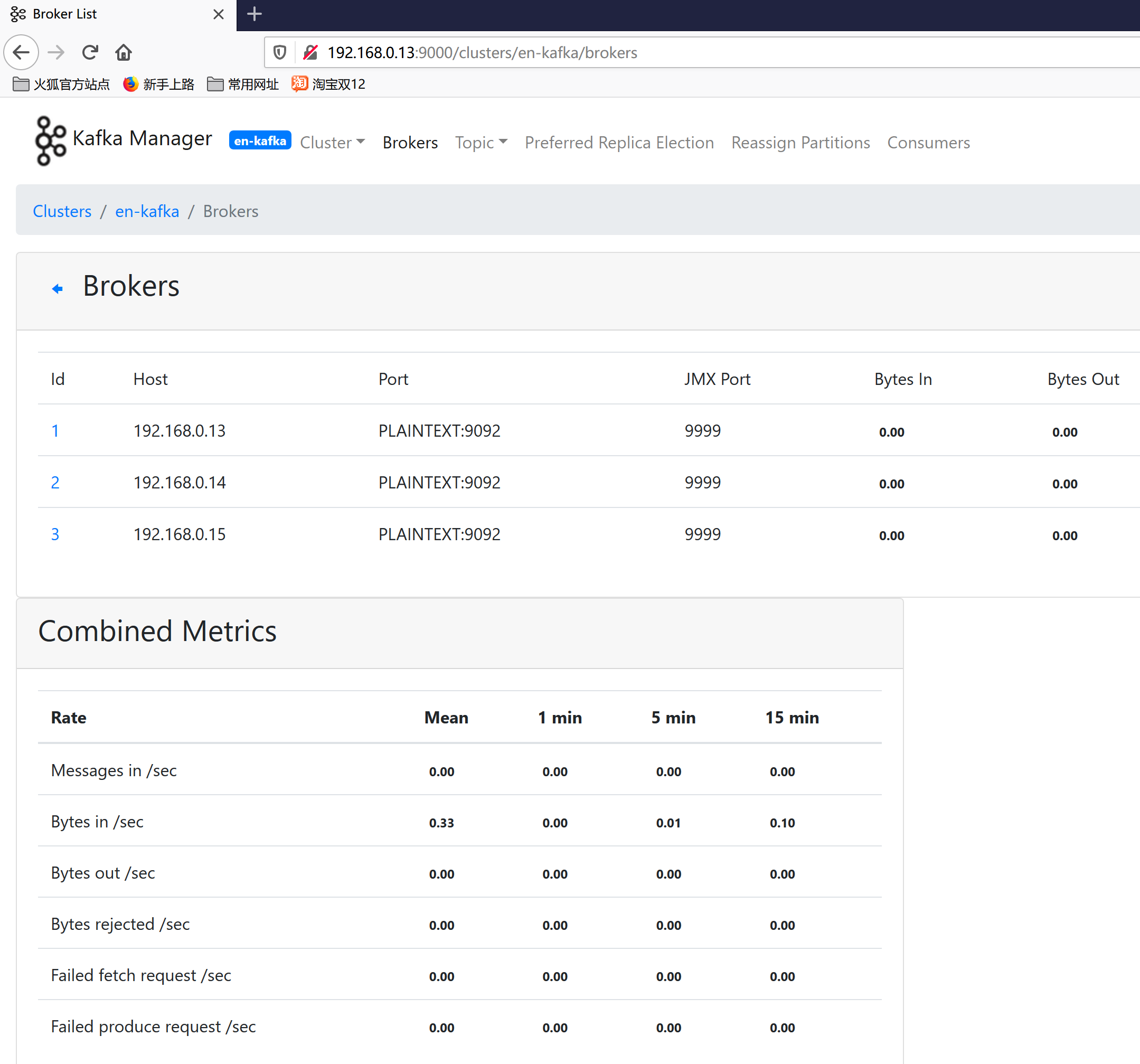
9.添加成功
kafka2.3.1+zookeeper3.5.6+kafka-manager2.0.0.2集群部署(centos7.7)的更多相关文章
- kafka单机版的安装、集群部署 及使用
1.安装kafka(单机版) 1.1上传 kafka_2.11-2.0.0.tgz 到 /root/Downloads 1.2解压 tar 包 tar -zxvf kafka_2.11-2.0.0.t ...
- Kafka server.properties配置,集群部署
server.properties中所有配置参数说明(解释) broker.id =0每一个broker在集群中的唯一表示,要求是正数.当该服务器的IP地址发生改变时,broker.id没有变化,则不 ...
- 消息中间件kafka+zookeeper集群部署、测试与应用
业务系统中,通常会遇到这些场景:A系统向B系统主动推送一个处理请求:A系统向B系统发送一个业务处理请求,因为某些原因(断电.宕机..),B业务系统挂机了,A系统发起的请求处理失败:前端应用并发量过大, ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- kafka集群部署文档(转载)
原文链接:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- ELK5.2+kafka+zookeeper+filebeat集群部署
架构图 考虑到日志系统的可扩展性以及目前的资源(部分功能复用),整个ELK架构如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了file ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
随机推荐
- 附011.Kubernetes-DNS及搭建
一 Kubernetes DNS介绍 1.1 Kubernetes DNS发展 作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,因此需要一个集群范围内的DNS服务来完成从服务名到 ...
- Java基础面试题及答案(五)
Java Web 64. jsp 和 servlet 有什么区别? jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器 ...
- 设置属性节点(setAttribute())
setAttribute():方法将为给定元素节点添加一个新的属性值或是改变它的现有属性值: element.setAttribute(attriibuteName,attributeValue); ...
- python排序算法之一:冒泡排序(及其优化)
相信冒泡排序已经被大家所熟知,今天看了一篇文章,大致是说在面试时end在了冒泡排序上,主要原因是不能给出冒泡排序的优化. 所以,今天就写一下python的冒泡排序算法,以及给出一个相应的优化.OK,前 ...
- 【RN - 基础】之TextInput使用简介
TextInput组件允许用户在应用中通过键盘输入文本信息,其使用方法和Text.Image一样简单,实例代码如下: <TextInput placeholder={'请输入用户名'} styl ...
- SpringBoot写一个登陆注册功能,和期间走的坑
文章目录 前言 1. 首先介绍项目的相关技术和工具: 2. 首先创建项目 3. 项目的结构 3.1实体类: 3.2 Mapper.xml 3.3 mapper.inteface 3.4 Service ...
- PAT(甲级)2019年春季考试
7-1 Sexy Primes 判断素数 一个点没过17/20分 错因:输出i-6写成了输出i,当时写的很乱,可以参考其他人的写法 #include<bits/stdc++.h> usin ...
- 【搞定面试官】try中有return,finally还会执行吗?
本篇文章我们主要探讨 一下如果try {}语句中有return,这种情况下finally语句还会执行吗?其实JVM规范是对这种情况有特殊规定的,那我就先上代码吧! public class Final ...
- 白话OAuth2用户认证及鉴权标准流程
一.OAuth2需求场景 在说明OAuth2需求及使用场景之前,需要先介绍一下OAuth2授权流程中的各种角色: 资源拥有者(User) - 指应用的用户 认证服务器 (Authorization S ...
- 漫谈LiteOS之开发板-串口(基于GD32450i-EVAL)
[摘要] 主要讲解物联网的技术积累,本期我们先带领大家学习漫谈LiteOS之漫谈开发板第一集-串口,本文基于GD32450i-EVAL对串口以及其通信做了一个简要的分析,以及开发过程中遇到的一些技术 ...