Python爬虫-爬取豆瓣图书Top250
豆瓣网站很人性化,对于新手爬虫比较友好,没有如果调低爬取频率,不用担心会被封 IP。但也不要太频繁爬取。
涉及知识点:requests、html、xpath、csv
一、准备工作
需要安装requests、lxml、csv库
爬取目标:https://book.douban.com/top250
二、分析页面源码
打开网址,按下F12,然后查找书名,右键弹出菜单栏 Copy==> Copy Xpath
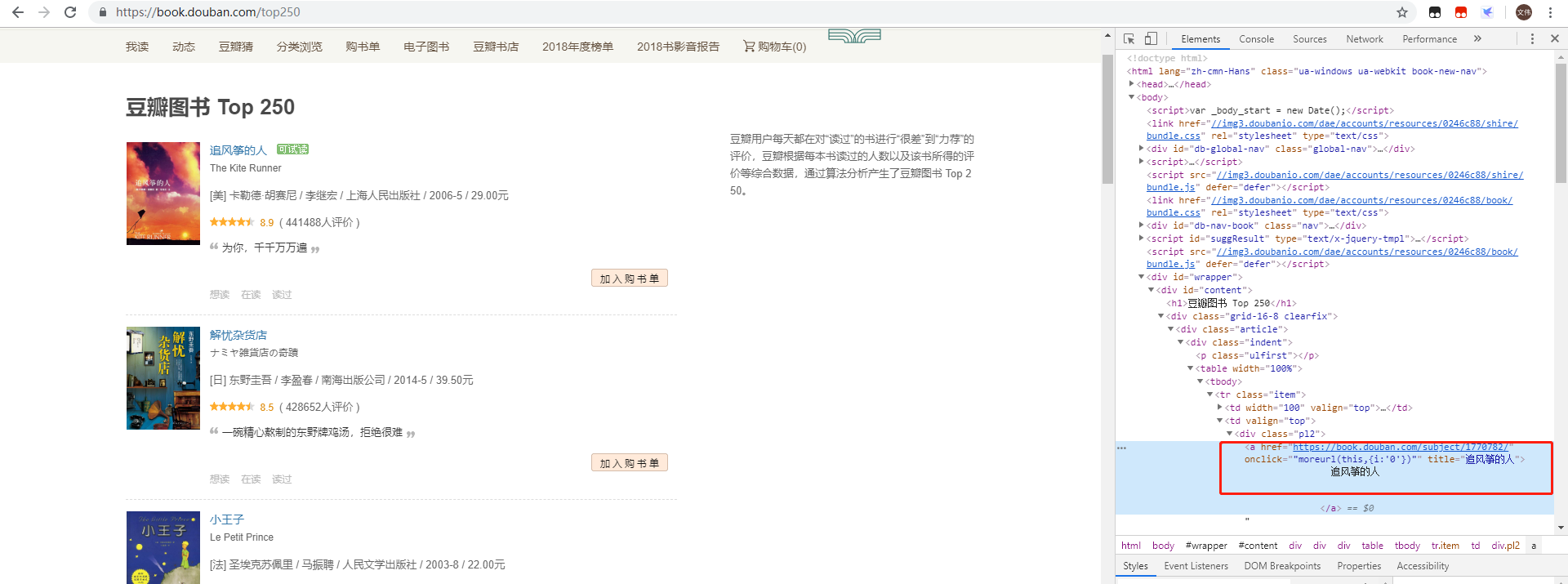
以书名“追风筝的人” 获取书名的xpath是://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
这里需要注意一下,浏览器复制的xpath只能作参考,因为浏览器经常会在自己里面增加多余的tbody标签,我们需要手动把这个标签删除,整理成//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a
同样获取图书的评分、评论人数、简介,结果如下:
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]
//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]
初步代码
import requests
from lxml import etree html = requests.get('https://book.douban.com/top250').text
res = etree.HTML(html)
#因为要获取标题文本,所以xpath表达式要追加/text(),res.xpath返回的是一个列表,且列表中只有一个元素所以追加一个[0]
name = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()
score = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2]/text()')[0].strip()
comment = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[3]/text()')[0].strip()
info = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/p[1]/text()')[0].strip()
print(name,score,comment,info)
执行显示:

这里只是获取第一条图书的信息,获取第二、第三看看

得到xpath:
import requests
from lxml import etree html = requests.get('https://book.douban.com/top250').text
res = etree.HTML(html)
name1 = res.xpath('//*[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a/text()')[0].strip()
name2 = res.xpath('//*[@id="content"]/div/div[1]/div/table[2]/tr/td[2]/div[1]/a/text()')[0].strip()
name3 = res.xpath('//*[@id="content"]/div/div[1]/div/table[3]/tr/td[2]/div[1]/a/text()')[0].strip()
print(name1,name2,name3)
执行显示:

对比他们的xpath,发现只有table序号不一样,我们可以就去掉序号,得到全部关于书名的xpath信息:
import requests
from lxml import etree html = requests.get('https://book.douban.com/top250').text
res = etree.HTML(html)
names = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr/td[2]/div[1]/a/text()')
for name in names:
print(name.strip())
执行结果:太多,这里只展示一部分

对于其他评分、评论人数、简介也同样使用此方法来获取。
到此,根据分析到的信息进行规律对比,写出获取第一页图书信息的代码:
import requests
from lxml import etree html = requests.get('https://book.douban.com/top250').text
res = etree.HTML(html)
trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr')
for tr in trs:
name = tr.xpath('./td[2]/div[1]/a/text()')[0].strip()
score = tr.xpath('./td[2]/div[2]/span[2]/text()')[0].strip()
comment = tr.xpath('./td[2]/div[2]/span[3]/text()')[0].strip()
info = tr.xpath('./td[2]/p[1]/text()')[0].strip()
print(name,score,comment,info)
执行结果展示(内容较多,只展示前部分)

以上只是获取第一页的数据,接下来,我们获取到全部页数的链接,然后进行循环即可
三、获取全部链接地址
查看分析页数对应网页源码:
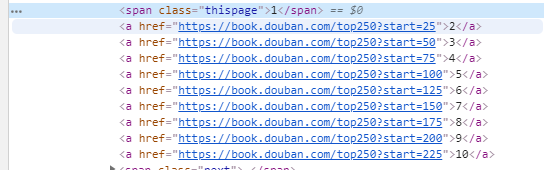
以代码实现
for i in range(10):
url = 'https://book.douban.com/top250?start={}'.format(i * 25)
print(url)
执行结果:正是正确的结果

经过分析,已经获取到全部的页面链接和每一页的数据提取,最后把整体代码进行整理和优化。
完整代码
#-*- coding:utf-8 -*-
"""
-------------------------------------------------
File Name: DoubanBookTop250
Author : zww
Date: 2019/5/13
Change Activity:2019/5/13
-------------------------------------------------
"""
import requests
from lxml import etree #获取每页地址
def getUrl():
for i in range(10):
url = 'https://book.douban.com/top250?start={}'.format(i*25)
urlData(url)
#获取每页数据
def urlData(url):
html = requests.get(url).text
res = etree.HTML(html)
trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr')
for tr in trs:
name = tr.xpath('./td[2]/div/a/text()')[0].strip()
score = tr.xpath('./td[2]/div/span[2]/text()')[0].strip()
comment = tr.xpath('./td[2]/div/span[3]/text()')[0].replace('(','').replace(')','').strip()
info = tr.xpath('./td[2]/p[1]/text()')[0].strip()
print("《{}》--{}分--{}--{}".format(name,score,comment,info)) if __name__ == '__main__':
getUrl()
执行结果:总共250条图书信息,一条不少,由于数据太多,只展示前部分

把爬取到的数据存储到csv文件中
def write_to_file(content):
#‘a’追加模式,‘utf_8_sig’格式到处csv不乱码
with open('DoubanBookTop250.csv','a',encoding='utf_8_sig',newline='') as f:
fieldnames = ['name','score','comment','info']
#利用csv包的DictWriter函数将字典格式数据存储到csv文件中
w = csv.DictWriter(f,fieldnames=fieldnames)
w.writerow(content)
完整代码
#-*- coding:utf-8 -*-
"""
-------------------------------------------------
File Name: DoubanBookTop250
Author : zww
Date: 2019/5/13
Change Activity:2019/5/13
-------------------------------------------------
"""
import csv
import requests
from lxml import etree #获取每页地址
def getUrl():
for i in range(10):
url = 'https://book.douban.com/top250?start={}'.format(i*25)
for item in urlData(url):
write_to_file(item)
print('成功保存豆瓣图书Top250第{}页的数据!'.format(i+1)) #数据存储到csv
def write_to_file(content):
#‘a’追加模式,‘utf_8_sig’格式到处csv不乱码
with open('DoubanBookTop250.csv','a',encoding='utf_8_sig',newline='') as f:
fieldnames = ['name','score','comment','info']
#利用csv包的DictWriter函数将字典格式数据存储到csv文件中
w = csv.DictWriter(f,fieldnames=fieldnames)
w.writerow(content) #获取每页数据
def urlData(url):
html = requests.get(url).text
res = etree.HTML(html)
trs = res.xpath('//*[@id="content"]/div/div[1]/div/table/tr')
for tr in trs:
yield {
'name':tr.xpath('./td[2]/div/a/text()')[0].strip(),
'score':tr.xpath('./td[2]/div/span[2]/text()')[0].strip(),
'comment':tr.xpath('./td[2]/div/span[3]/text()')[0].replace('(','').replace(')','').strip(),
'info':tr.xpath('./td[2]/p[1]/text()')[0].strip()
}
#print("《{}》--{}分--{}--{}".format(name,score,comment,info)) if __name__ == '__main__':
getUrl()
内容过多,只展示前部分

Python爬虫-爬取豆瓣图书Top250的更多相关文章
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- Python项目之我的第一个爬虫----爬取豆瓣图书网,统计图书数量
今天,花了一个晚上的时间边学边做,搞出了我的第一个爬虫.学习Python有两个月了,期间断断续续,但是始终放弃,今天搞了一个小项目,有种丰收的喜悦.废话不说了,直接附上我的全部代码. # -*- co ...
- 2019-02-01 Python爬虫爬取豆瓣Top250
这几天学了一点爬虫后写了个爬取电影top250的代码,分别用requests库和urllib库,想看看自己能不能搞出个啥东西,虽然很简单但还是小开心. import requests import r ...
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
随机推荐
- YAML_12 批量创建用户,分别设置用户组
with_items标准循环 ansible]# vim add.yml --- - hosts: web2 remote_user: root tasks: - user: ...
- 用es实现模糊搜索
Haystack为Django提供了模块化的搜索.它的特点是统一的,熟悉的API,可以让你在不修改代码的情况下使用不同的搜索后端(比如 Solr, Elasticsearch, Whoosh, Xap ...
- pyy整队 线段树
pyy整队 线段树 问题描述: 众所周知pyy当了班长,服务于民.一天体育课,趁体育老师还没来,pyy让班里n个同学先排好 队.老师不在,同学们开始玩起了手机.站在队伍前端玩手机,前面的人少了,谁都顶 ...
- Launch4j:An error occurred while starting the application.解决方案
长期使用Processing 2.X进行开发,突然有一天Processing 1.5.1打不开了,报错如下: 按[确定]后窗口消失,但是任务管理器中的“javaw.exe”并没有消失..... 试过各 ...
- jmeter非GUI界面常用参数详解
压力测试或者接口自动化测试常常用到的jmeter非GUI参数,以下记录作为以后的参考 讲解:非GUI界面,压测参数讲解(欢迎加入QQ群一起讨论性能测试:537188253) -h 帮助 -n 非GUI ...
- BAT 删除超过xx天的文件
@echo offecho 删除n天前的备分文件和日志forfiles /p "C:\ShareF" /m *.zip /d -7 /c "cmd /c del @pat ...
- Linux中的iptables防火墙策略
0x01 简介 iptables其实不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过iptables这个代理,将用户的安全设定执行到对应的"安全框架"中,这个" ...
- vue中全局filter和局部filter怎么用?
需求: 将价值上加上元单位符号(全局filter) <template> <div> 衣服价格:{{productPrice|formatTime}} </div> ...
- CFD计算过程发散诸多原因分析【转载】
转载自: http://blog.sina.com.cn/s/blog_5fdfa7e601010rkx.html 今天探讨引起CFD计算过程中发散的一些原因.cfd计算是将描述物理问题的偏微分方程转 ...
- mysql使用replace和on duplicate key update区别
实际业务使用中,有时候会遇到插入数据库,但是如果某个属性(比如:主键)存在,就做更新.通常有两种方式:1.replace into 2.on duplicate key update 但是在使用过程 ...