K-Means 聚类分析学习笔记
在之前分享的链家二手房数据分析的练习中用到了 K-Means 聚类分析方法,所以就顺道一起复习一下 K-Means 的基础知识好了。
K-Means 聚类分析可将样本分为若干个集群,它的核心思想就是使某集群的数据点与其对应的中心之间的距离最小。所以 K-Means 聚类分析通常会假设已知集群的中心或者至少已知集群的数目。
当观测对象包含缺失值时,那么在 K-Means 聚类分析的过程中会把该观测对象除外。
比如说,对于一个有 p 个变量 n 个观察值的矩阵 X 而言,我们可以指定一个 K * P 的矩阵为初始中心,或者直接在矩阵 X 中选取 K * P 个中心。
K-Means 聚类分析包含两个重要的过程。第一个是选取初始中心,第二个是根据中心归类分组。
>> 选取初始中心
若假设将样本分为 K 个集群,那么:
- 将前 K 个观测值设为集群中心
- 遍历其余观测值。若该观测值与其最近的中心点的距离大于任意两个相隔最近的中心的距离,则新的观测值替代这两个原中心中距离较近的中心成为新的集群中心。说的一头雾水的吧……还是看看图吧。
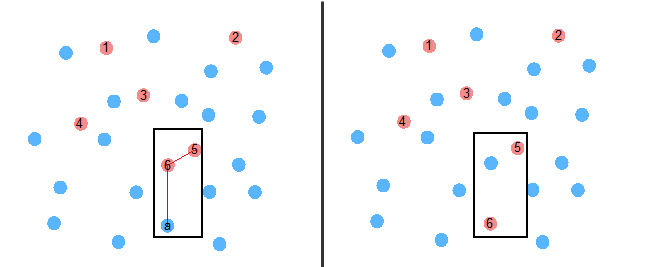
比如说,某个样本具有 6 个初始中心。当循环比较至点 a 时,可以发现点 a 到中心 6 的距离大于中心 6 与中心 5 之间的距离,于是点 a 取代离它较近的中心 6 成为新的中心。
>> 归类观测值
利用欧式距离将每个观测值归入到离它最近的集群中。

比如说将观测值 i 归入到集群 k 中,那么观测值 i 和集群 k 的距离校正值为:
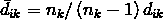
观测值和其他集群(集群 j )的距离校正值为:
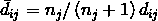
如果观测值与集群 j 的距离校正值是相较于其他集群而言最小,且小于该观测值目前所处的集群 k 的距离,那么将观测值 i 归入集群 j,并且更新每个集群的中心为其群内所有观测值的均值。
不断重复以上步骤,直至迭代次数达到上线或者两次更新中心后的集群内平方和之差小于阈值。
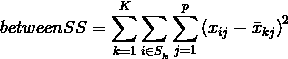
K-Means 聚类分析学习笔记的更多相关文章
- R与数据分析旧笔记(十五) 基于有代表性的点的技术:K中心聚类法
基于有代表性的点的技术:K中心聚类法 基于有代表性的点的技术:K中心聚类法 算法步骤 随机选择k个点作为"中心点" 计算剩余的点到这个k中心点的距离,每个点被分配到最近的中心点组成 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- Python实现kMeans(k均值聚类)
Python实现kMeans(k均值聚类) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=> ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 第十篇:K均值聚类(KMeans)
前言 本文讲解如何使用R语言进行 KMeans 均值聚类分析,并以一个关于人口出生率死亡率的实例演示具体分析步骤. 聚类分析总体流程 1. 载入并了解数据集:2. 调用聚类函数进行聚类:3. 查看聚类 ...
- K均值聚类的失效性分析
K均值聚类是一种应用广泛的聚类技术,特别是它不依赖于任何对数据所做的假设,比如说,给定一个数据集合及对应的类数目,就可以运用K均值方法,通过最小化均方误差,来进行聚类分析. 因此,K均值实际上是一个最 ...
随机推荐
- vue中路由拦截无限循环的情况
router.beforeEach(async (to, from, next) => { if (token) { if (whiteList.indexOf(to.path) != -1) ...
- 浅谈华为验厂对MES系统的要求
众所周知,华为对供应商在管理.防错.品控.追溯等方面的要求都非常严格.在华为验厂时,对供应商的信息系统,尤其是MES系统的评估也是有非常具体的要求.那么我们今天就来谈谈华为验厂时,对MES系统有哪些具 ...
- VUE+ElementUI 搭建后台项目(一)
前言 之前有些过移动端的项目搭建的文章,感觉不写个pc端管理系统老感觉少了点什么,最近公司项目比较多,恰巧要做一个申报系统的后台管理系统,鉴于对vue技术栈比较熟悉,所以考虑还是使用vue技术栈来做: ...
- Spring项目配置多数据源
项目中有用到多数据源,并进行动态切换,使用的是阿里的druid.看网上有一篇大致一样的就偷偷懒 import java.sql.SQLFeatureNotSupportedException; imp ...
- windows10删除多出的oem分区
某次windows升级后,磁盘管理里新出现一个500多M的OEM分区 其实系统里本来就有一个OEM分区是第一个分区,大小499M,可能因为这个分区太小,系统就又新建一个 因为在windows10分区后 ...
- Shell 编程 编辑工具 awk
本篇主要写一些shell脚本编辑工具awk的使用. 概述 awk是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理. awk倾向于将一 ...
- nginx日志设置
环境:nginx1.16.1 (1)日志类型:access_log(访问日志) error_log(错误日志)rewrite_log 访问日志:通过访问日志我们可以得到用户的IP地址.浏览器的信息,请 ...
- Nginx 高级配置--关于favicon.ico
Nginx 高级配置--关于favicon.ico 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.浏览器会默认帮咱们访问官网的图标 1>.浏览器访问网站"htt ...
- 2019徐州网络赛H :function (min25筛)
题意:f(i)=i的幂次之和. 求(N+1-i)*f(i)之和. 思路:可以推论得对于一个素数p^k,其贡献是ans=(N+1)[N/(P^k)]+P^k(1+2+3...N/(P^k)); 我们分两 ...
- WindowChrome
"chrome"一词在设计术语中是"框架"的意思,即浏览器的除了网页之外的部分. https://www.cnblogs.com/dino623/p/Cus ...