可分离滤波器设计高斯滤波 CUDA程序优化, 实验记录
环境:RTX2060 ,1920X1080p ,循环10次, kernal_size=8
一 、测试前128个线程拷贝到dst数据的性能 ,只测试行卷积, block=(128+2r)X1
1. 使用中间128个线程拷贝 : (36.37+37.11+36.32)/3 = 36.6 GB
2. 改为前128个线程拷贝出数据: (38.89+39.53+39.74)/3 = 39.39GB
实验结果:使用前128个线程拷贝会快10.7%
二 、 测试const 变量对性能的影响 ,只测试行卷积 block =(128+2r)X1
1. radius 为局部变量(函数传入) 40.1 GB
2. radius 为__constant__ 变量 , 40.2GB
实验结果 __constant__ 和 局部变量 的性能实际上差不多
三、 测试block 线程数对性能的影响, 只测试行卷积
1. block = (64+2r)X1 37.10GB
2. block = (128+2r)X1 40.33GB
3. block = (256+2r)X1 37.75GB
4. block = (512+2r)X1 28.31GB
5. block = (128)X1 37.3GB
6. block=(320+2r)X1 34.26GB
7. block=320X1 39GB
8.block=160X1 38.57GB
9.block=(160+2r)X1 39.04GB
10 block=(640+2r)X1 30.34GB
11 block=640X1 27.96GB
实验结果 : block并不是越大越好, 选择 block = (128+2r)X1 可能好一点吧~
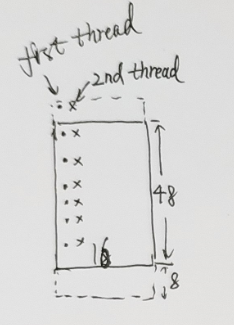
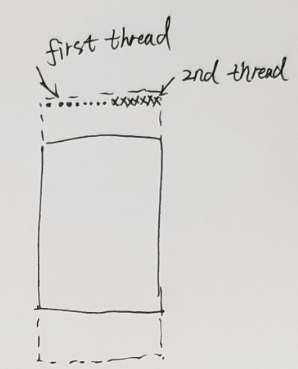
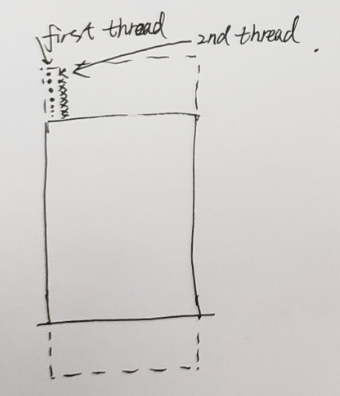
四、列卷积时候, 测试连续copy 和 跳步copy性能,只测试列卷积,行卷积注释掉
1. 跳步copy :45.11GB
2. 行连续copy:36.98GB
3 列连续copy:47.31GB
下图分别是1,2,3的拷贝过程示意图
实验结果: 使用第三种拷贝方式会加速4.9%
五、 使用单列拷贝 ,只测试列卷积
1. block=(128+2r)X1 18.89GB
实验结果: 使用单列进行计算会很慢
六 、 测试IMUL对性能的影响
1. 无IMUL 28.30GB
2. IMUL 28.38GB
实验结果 IMUL对实验结果无影响
七 、测试float4 对性能的影响,只测试行卷积
1. 无float4
2. float4
八 、列卷积时候, 测试连续计算 和 跳步计算性能,行卷积没有注释
连续计算 23.7GB
跳步计算 28.7 GB
实验结果: 跳步计算要快一些
可分离滤波器设计高斯滤波 CUDA程序优化, 实验记录的更多相关文章
- opencv 源码分析 CUDA可分离滤波器设计 ( 发现OpenCV的cuda真TM慢 )
1. 主函数 void SeparableLinearFilter::apply(InputArray _src, OutputArray _dst, Stream& _stream) { G ...
- 学习 opencv---(7) 线性邻域滤波专场:方框滤波,均值滤波,高斯滤波
本篇文章中,我们一起仔细探讨了OpenCV图像处理技术中比较热门的图像滤波操作.图像滤波系列文章浅墨准备花两次更新的时间来讲,此为上篇,为大家剖析了"方框滤波","均值滤 ...
- 滤波器——BoxBlur均值滤波及其快速实现
个人博客地址:滤波器--BoxBlur均值滤波及其快速实现 动机:卷积核.滤波器.卷积.相关 在数字图像处理的语境里,图像一般是二维或三维的矩阵,卷积核(kernel)和滤波器(filter)通常指代 ...
- matlab做gaussian高斯滤波
原文链接:https://blog.csdn.net/humanking7/article/details/46826105 核心提示 在Matlab中高斯滤波非常方便,主要涉及到下面两个函数: 函数 ...
- CUDA性能优化----warp深度解析
本文转自:http://blog.163.com/wujiaxing009@126/blog/static/71988399201701224540201/ 1.引言 CUDA性能优化----sp, ...
- SIFT四部曲之——高斯滤波
本文为原创作品,未经本人同意,禁止转载 欢迎关注我的博客:http://blog.csdn.net/hit2015spring和http://www.cnblogs.com/xujianqing/ 或 ...
- 一步步做程序优化-讲一个用于OpenACC优化的程序(转载)
一步步做程序优化[1]讲一个用于OpenACC优化的程序 分析下A,B,C为三个矩阵,A为m*n维,B为n*k维,C为m*k维,用A和B来计算C,计算方法是:C = alpha*A*B + beta* ...
- Java 程序优化 (读书笔记)
--From : JAVA程序性能优化 (葛一鸣,清华大学出版社,2012/10第一版) 1. java性能调优概述 1.1 性能概述 程序性能: 执行速度,内存分配,启动时间, 负载承受能力. 性能 ...
- Atitit 图像处理 平滑 也称 模糊, 归一化块滤波、高斯滤波、中值滤波、双边滤波)
Atitit 图像处理 平滑 也称 模糊, 归一化块滤波.高斯滤波.中值滤波.双边滤波) 是一项简单且使用频率很高的图像处理方法 用途 去噪 去雾 各种线性滤波器对图像进行平滑处理,相关OpenC ...
随机推荐
- Centos 7配置nginx反向代理负载均衡集群
一,实验介绍 利用三台centos7虚拟机搭建简单的nginx反向代理负载集群, 三台虚拟机地址及功能介绍 192.168.2.76 nginx负载均衡器 192.168.2.82 web ...
- java web开发及Servlet常用的代码
日志 1.使用门面模式的slfj,并结合log4j,logback. 2.info.debug.error,要写清楚. 3.使用占位符,如下: log.info("用户id为: {} &qu ...
- 电商ERP系统——商品SKU与库存设计
面试题经常问道,如何设计库存,哪些库存呢?分类属性的库存:不同颜色 不同尺码的属性的库存,这时候需要针对具体的SKU商品创建表. 总体思路 1.商品关联商品类别,商品类别关联多个商品属性,其中指定某几 ...
- java 异步操作
/** * 异步删除 * * @param keys */ public void asycExecute(String keys) { ExecutorService executor = Exec ...
- Centos7安装Redis5.0.5并加入Systemd服务
1. 安装gcc-c++, tcl yum install gcc-c++ tcl 2. 解压缩, 编译, 测试 tar zxvf redis-5.0.5.tar.gz make make test ...
- Java基础 throws 提示调用方法时要注意处理相关异常
JDK :OpenJDK-11 OS :CentOS 7.6.1810 IDE :Eclipse 2019‑03 typesetting :Markdown code ...
- AnnotatedElementUtils.findMergedAnnotation作用
// 在element上查询annotationType类型注解 // 将查询出的多个annotationType类型注解属性合并到查询的第一个注解中 // # 多个相同注解合并 org.spring ...
- Oracle系列四 单行函数查询语句
单行函数 操作数据对象 接受参数返回一个结果 只对一行进行变换 每行返回一个结果 可以转换数据类型 可以嵌套 参数可以是一列或一个值 包含:字符,数值,日期,转换,通用 字符函数 1.大小写控制函数: ...
- Linux_CentOS下搭建Nodejs 生产环境-以及nodejs进程管理器pm2的使用
nodejs安装:https://www.cnblogs.com/loaderman/p/11596661.html nodejs 进程管理器 pm2 的使用 PM2 是一款非常优秀的 Node 进程 ...
- 002-maven开发Java脚手架archrtype【如无定制开发,请直接看3.3使用】
一.概述 项目基础构建需要:项目结构,spring框架,orm,连接池,数据库,单元测试等等. 上述即使复用:001-脚手架发展,基础代码结构+mybatis代码生成,基础代码结构,也需要修改成自己单 ...