论文阅读笔记五十八:FoveaBox: Beyond Anchor-based Object Detector(CVPR2019)

论文原址:https://arxiv.org/abs/1904.03797
摘要
FoveaBox属于anchor-free的目标检测网络,FoveaBox直接学习可能存在的图片种可能存在的目标,这期间并不需要anchor作为参考。主要靠两方面实现:(1)产生类别敏感的语义map用于表示目标物存在的可能性。(2)在每个可能存在目标物的位置生成与类别无关的边界框。目标边框的尺寸与对应输入图片的特征金字塔的表示相关。
介绍
目标检测主要包含两个任务:定位及识别,输入一张图片,检测系统需要判断是否有预定义类别的目标物,如果有,就返回他的空间位置以及内容。为了增加系统的定位功能,滑动窗已经沿用了很多年。基于anchor的方法一般趋向框的空间(包括尺寸,大小,位置等)划分为格子,并增强对应目标的格子来进行定位。对于双阶段检测来说,Anchors是回归标准,以及用于预测proposals的候选框。对于单阶段检测来说是最终的边框。Anchor也可以看作是覆盖所有可能存在目标物的像素的特征共享的滑动窗机制。
anchor存在以下几点缺点:(I)anchor引入了大量的超参数。为了得到一个较好的召回率,需要参考由数据集/测试集计算得到的统计分布设置。(II)对于一个数据集设计的anchor可能不适用于另一个数据集,普适性低。(III)anchor一般会产生较多的候选框,而这里就存在着前景/背景数目不平衡问题。
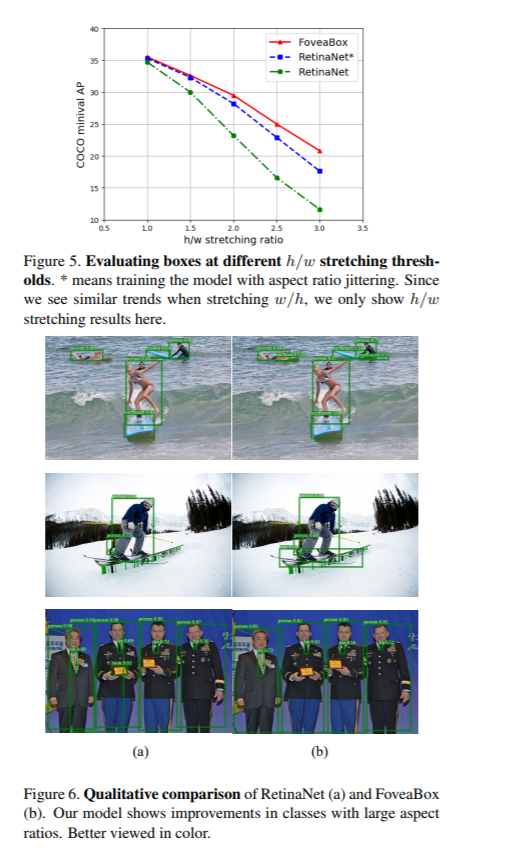
提高anchor普适性的一个做法是改变anchor,使其灵活可变。借鉴人类的视觉系统,人文可以直接通过视觉信息识别出物体的位置及类别,而不需要一些繁琐的预定义的框。本文的FoveaBox的灵感来自人样的Fovea。视野(目标物)中心具有最高的视觉敏感度。FoveaBox预测可能存在目标物中心位置的同时预测有效位置的边框。由于特征金字塔表示,可以通过在不同层次的特征上检测出不同尺寸大小的目标物。由于FoveaBox不依赖于预定义的anchor,因此,对于数据集的边框分布更具鲁棒性。
FoveaBox
FoveaBox是一个网络,由backbone及两个任务明确的子网络组成。backbone负责得到整幅图像的卷积特征。第一个分支网络在backbone的输出特征上进行像素级分类。第二个分支用于边界框的预测。
FPN for backbone
FPN通过利用top-down结构及侧连接结构来构建单尺寸输入的多尺寸金字塔特征。金字塔的每一层都可以检测不同尺寸大小的目标。本文搭建了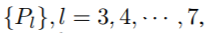 金字塔,l代表金字塔的某一层级,每层的输出通道数都为256
金字塔,l代表金字塔的某一层级,每层的输出通道数都为256
Scale Assignment
由于不同物体存在较大的尺寸变化,预测得到的边框的值不是固定的。相对的,本文特征金字塔的层级,将目标物的尺寸划分为几个格子。P3到P7,每层都有自己对应的基础区域32^2~512^2,对于Pl层种的basic-area大小Sl如下
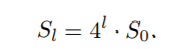
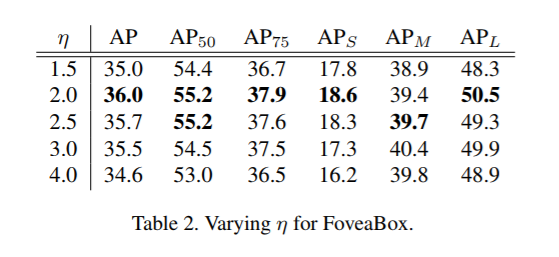
参考基于Resnet Faster R-CNN中用C4作为signel scale,本文将S0设置为16,特征金字塔中每层只学习目标物的一部分特征表示。对于l层的特征金字塔其目标物尺寸的有效范围如下,其中下式中的eta人为设置的用于控制每层的尺寸范围。不在范围内的目标在训练时被忽略,值得注意的是同一个目标可能会在不同的层中检测到。
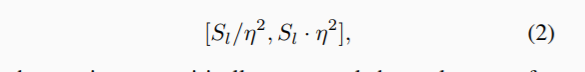
Object Fovea
每个金字塔heatmaps的输出为K(类别数)通道,大小为HxW,如下图所示,每个通道都是一个二值mask表示是否为某一个类别。

给定一个ground truth框(x1,y1,x2,y2),首先基于stride 2^l将其映射至对应的l层。
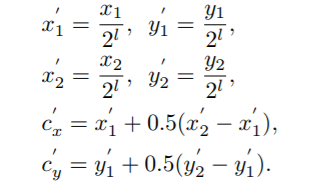
位于score map上的positive 区域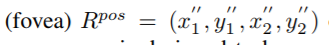 相比原来做了一些缩放处理,如下图3所示,等式如下,
相比原来做了一些缩放处理,如下图3所示,等式如下,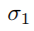 为缩放因子。落入该区域的ceil标记对应类别。通过引入另一个缩放因子
为缩放因子。落入该区域的ceil标记对应类别。通过引入另一个缩放因子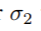 按等式(4)得到
按等式(4)得到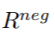 ,negative区域为除去Rneg的整个feature map。如果一个单元没有被assign,在训练时,则将其忽略。由于positive区域占较小的比例,因此,该分支使用Focal Loss。
,negative区域为除去Rneg的整个feature map。如果一个单元没有被assign,在训练时,则将其忽略。由于positive区域占较小的比例,因此,该分支使用Focal Loss。
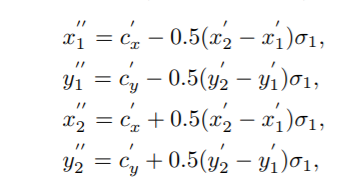
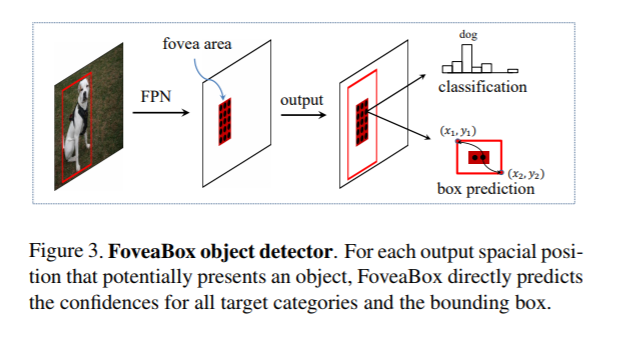
预测边框
模型只编码目标物体存在的概率。为了定位,需要预测每个实例可能存在的位置。每个ground truth box的位置按如下方式定义。
G=(x1,y1,x2,y2),本文目标:找到一种变换将feature maps中(x,y)单元的网络位置输出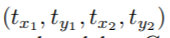 映射到ground truth box G中,
映射到ground truth box G中,

上面函数首先将位置(x,y)映射至输入图片,然后计算映射后的坐标于G之间的偏差。最后通过Log-space进行处理。仍基于L1 loss对Lbox进行训练。最后,在输出feature maps上的每个positive ceil(x,y)上产生框的边界。
优化策略

Inference
首先设置0.05滤掉confidence低于此值的预测结果,每个预测层中选测分数前100的结果。对于每个类别使用基于0.5的阈值进行NMS处理。最终每张图片得到100个预测结果。
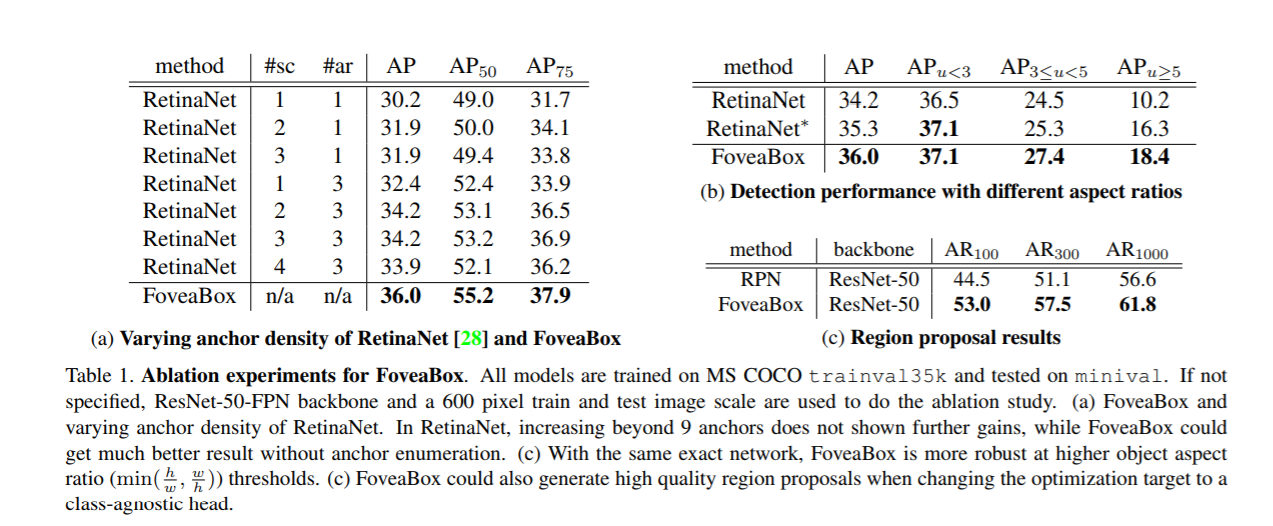
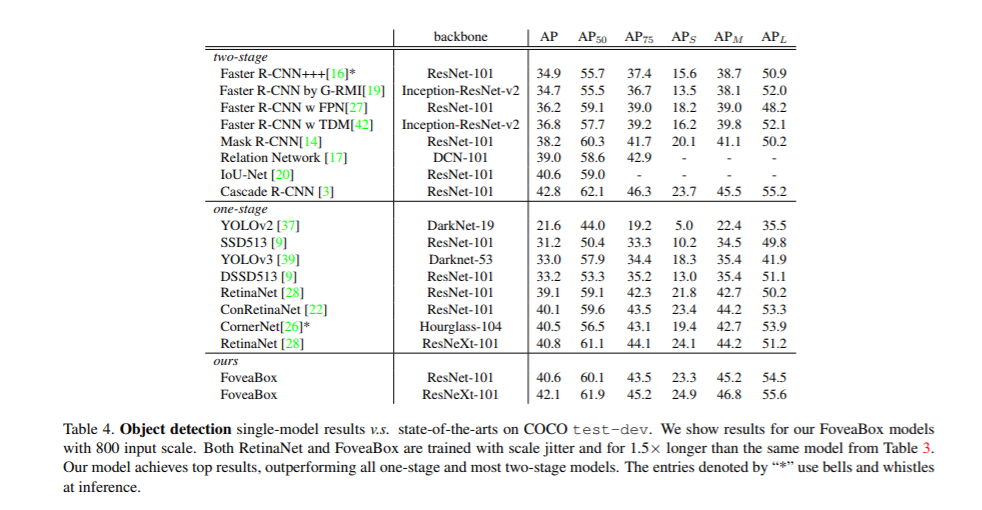
实验



Reference
[1] M. F. Bear, B. W. Connors, and M. A. Paradiso. Neuroscience, volume 2. Lippincott Williams & Wilkins, 2007.
[2] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Softnms–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, pages 5561–5569, 2017.
[3] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. arXiv preprint arXiv:1712.00726, 2017.
[4] H.-Y. Chen et al. Tensorflow–a system for large-scale machine learning. In OSDI, volume 16, pages 265–283, 2016
论文阅读笔记五十八:FoveaBox: Beyond Anchor-based Object Detector(CVPR2019)的更多相关文章
- 论文阅读笔记五十一:CenterNet: Keypoint Triplets for Object Detection(CVPR2019)
论文链接:https://arxiv.org/abs/1904.08189 github:https://github.com/Duankaiwen/CenterNet 摘要 目标检测中,基于关键点的 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- 论文阅读笔记五十六:(ExtremeNet)Bottom-up Object Detection by Grouping Extreme and Center Points(CVPR2019)
论文原址:https://arxiv.org/abs/1901.08043 github: https://github.com/xingyizhou/ExtremeNet 摘要 本文利用一个关键点检 ...
- 论文阅读笔记五十五:DenseBox: Unifying Landmark Localization with End to End Object Detection(CVPR2015)
论文原址:https://arxiv.org/abs/1509.04874 github:https://github.com/CaptainEven/DenseBox 摘要 本文先提出了一个问题:如 ...
- 论文阅读笔记五十四:Gradient Harmonized Single-stage Detector(CVPR2019)
论文原址:https://arxiv.org/pdf/1811.05181.pdf github:https://github.com/libuyu/GHM_Detection 摘要 尽管单阶段的检测 ...
- 论文阅读笔记五十二:CornerNet-Lite: Efficient Keypoint Based Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.08900.pdf github:https://github.com/princeton-vl/CornerNet-Lite 摘要 基 ...
- 论文阅读笔记五十:CornerNet: Detecting Objects as Paired Keypoints(ECCV2018)
论文原址:https://arxiv.org/pdf/1808.01244.pdf github:https://github.com/princeton-vl/CornerNet 摘要 本文提出了目 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
随机推荐
- Vue indent eslint缩进webstorm冲突解决
参考教程 官方回复 ESlint设置 rules: { 'no-multiple-empty-lines': [1, {max: 3}], // 控制允许的最多的空行数量 'vue/script-in ...
- Win10安装 oracle11g 出现INS-13001环境不满足最低要求解决方法
Win10安装 oracle11g 出现INS-13001环境不满足最低要求 首先,打开你的解压后的database文件夹,找到stage,然后cvu,找到cvu_prereq.xml文件,用note ...
- ARC082E ConvexScore(神奇思路)
这题就是拼拼凑凑就出来了. 可能看英文题面容易题意杀(小写大写 \(n,N\)),这里复述一遍:对于每个构成凸多边形的点集(每个点恰好都是凸多边形的顶点,必须是严格的凸多边形,内角严格小于 180 度 ...
- 手把手教你使用gogs搭建git私有仓库
本来想在 Github 上建一个私仓,但是发现只能设置 3 个贡献者. 国内的码云也只能设置 5 个. 无意间看到了使用 gogs 可以搭建私服,正好手头有空闲的服务器,于是开干! https://g ...
- 物联网架构成长之路(31)-EMQ基于HTTP权限验证
看过之前的文章就知道,我之前是通过搞插件,或者通过里面的MongoDB来进行EMQ的鉴权登录和权限验证.但是前段时间发现,还是通过HTTP WebHook 方式来调用鉴权接口比较适合实际使用.还是实现 ...
- spring 注解aop调用invoke()
public static void main(String[] args) { ClassPathXmlApplicationContext context = new ClassPathXmlAp ...
- div+css画一个小猪佩奇
用DIV+CSS画一个小猪佩奇,挺可爱的,嘻嘻. HTML部分(全是DIV) <!-- 小猪佩奇整体容器 --> <div class="pig_container&quo ...
- Lucene的全文检索学习
Lucene的官方网站(Apache的顶级项目):http://lucene.apache.org/ 1.什么是Lucene? Lucene 是 apache 软件基金会的一个子项目,由 Doug C ...
- 用openresty(Lua)写一个获取YouTube直播状态的接口
文章原发布于:https://www.chenxublog.com/2019/08/29/openresty-get-youtube-live-api.html 之前在QQ机器人上面加了个虚拟主播开播 ...
- 剑指 Offer——1. 二维数组中的查找
题目描述 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数 ...