大数据学习——mapreduce案例join算法
需求:
用mapreduce实现
select order.orderid,order.pdtid,pdts.pdt_name,oder.amount
from order
join pdts
on order.pdtid=pdts.pdtid
数据:
orders.txt
Order_0000001,pd001,222.8
Order_0000001,pd005,25.8
Order_0000002,pd005,325.8
Order_0000002,pd003,522.8
Order_0000002,pd004,122.4
Order_0000003,pd001,222.8
Order_0000003,pd001,322.8
pdts.txt
pd001,apple
pd002,banana
pd003,orange
pd004,xiaomi
pd005,meizu
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>MapReduceCases</artifactId>
<packaging>jar</packaging>
<version>1.0</version> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.1.40</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.36</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.mapreduce.CacheFile.MapJoinDistributedCacheFile</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
package cn.itcast.mapreduce.CacheFile; import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap; import org.apache.commons.lang.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MapJoinDistributedCacheFile {
private static final Log log = LogFactory.getLog(MapJoinDistributedCacheFile.class); public static class MapJoinDistributedCacheFileMapper extends Mapper<LongWritable, Text, Text, NullWritable> { FileReader in = null;
BufferedReader reader = null;
HashMap<String, String[]> b_tab = new HashMap<String, String[]>(); @Override
protected void setup(Context context) throws IOException, InterruptedException {
// 此处加载的是产品表的数据
in = new FileReader("pdts.txt");
reader = new BufferedReader(in);
String line = null;
while (StringUtils.isNotBlank((line = reader.readLine()))) {
String[] split = line.split(",");
String[] products = {split[0], split[1]};
b_tab.put(split[0], products);
}
IOUtils.closeStream(reader);
IOUtils.closeStream(in);
} @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] orderFields = line.split(",");
String pdt_id = orderFields[1];
String[] pdtFields = b_tab.get(pdt_id);
String ll = orderFields[0] + "\t" + pdtFields[1] + "\t" + orderFields[1] + "\t" + orderFields[2];
context.write(new Text(ll), NullWritable.get());
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); // job.setJarByClass(MapJoinDistributedCacheFile.class);
//告诉框架,我们的程序所在jar包的位置
job.setJar("/root/MapJoinDistributedCacheFile.jar");
job.setMapperClass(MapJoinDistributedCacheFileMapper.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("/mapjoin/input"));
FileOutputFormat.setOutputPath(job, new Path("/mapjoin/output")); job.setNumReduceTasks(0); // job.addCacheFile(new URI("file:/D:/pdts.txt"));
job.addCacheFile(new URI("hdfs://mini1:9000/cachefile/pdts.txt")); job.waitForCompletion(true);
}
}
创建文件夹上传数据
hadoop fs -mkdir -p /cachefile
hadoop fs -put pdts.txt /cachefile
hadoop fs -mkdir -p /mapjoin/input
hadoop fs -put orders.txt /mapjoin/input
打包并运行

运行
hadoop jar MapJoinDistributedCacheFile.jar cn.itcast.mapreduce.CacheFile.MapJoinDistributedCacheFile
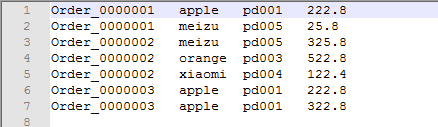
运行结果
大数据学习——mapreduce案例join算法的更多相关文章
- 大数据学习之BigData常用算法和数据结构
大数据学习之BigData常用算法和数据结构 1.Bloom Filter 由一个很长的二进制向量和一系列hash函数组成 优点:可以减少IO操作,省空间 缺点:不支持删除,有 ...
- 大数据学习——mapreduce运营商日志增强
需求 1.对原始json数据进行解析,变成普通文本数据 2.求出每个人评分最高的3部电影 3.求出被评分次数最多的3部电影 数据 https://pan.baidu.com/s/1gPsQXVYSQE ...
- 大数据学习——mapreduce学习topN问题
求每一个订单中成交金额最大的那一笔 top1 数据 Order_0000001,Pdt_01,222.8 Order_0000001,Pdt_05,25.8 Order_0000002,Pdt_05 ...
- 大数据学习——mapreduce共同好友
数据 commonfriends.txt A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I D:A,E,F,L E:B,C,D,M,L F:A,B,C,D,E,O,M G:A,C,D ...
- 大数据学习——mapreduce倒排索引
数据 a.txt hello jerry hello tom b.txt allen tom allen jerry allen hello c.txt hello jerry hello tom 1 ...
- 大数据学习——mapreduce汇总手机号上行流量下行流量总流量
时间戳 手机号 MAC地址 ip 域名 上行流量包个数 下行 上行流量 下行流量 http状态码 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 12 ...
- 大数据学习——mapreduce程序单词统计
项目结构 pom.xml文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns=&q ...
- 大数据学习——MapReduce学习——字符统计WordCount
操作背景 jdk的版本为1.8以上 ubuntu12 hadoop2.5伪分布 安装 Hadoop-Eclipse-Plugin 要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 ...
- 【机器学习实战】第15章 大数据与MapReduce
第15章 大数据与MapReduce 大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力. 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则 ...
随机推荐
- compose 函数实现
总结componse函数实现过程 大致特点 参数均为函数, 返回值也是函数 第一函数接受参数, 其他函数接受的上一个函数的返回值 第一个函数的参数是多元的, 其他函数的一元的 自右向左执行 简单实现 ...
- Python+selenium定位不到元素的问题及解决方案
在操作过程中主要遇到两种阻塞的问题,总结如下: 1.页面中有iframe,定位元素时,需要用switch_to.frame()转换到元素所在的frame上再去定位 2.遇到一种新情况,有些按钮在htm ...
- 495 Teemo Attacking 提莫攻击
在<英雄联盟>的世界中,有一个叫“提莫”的英雄,他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态.现在,给出提莫对艾希的攻击时间序列和提莫攻击的中毒持续时间,你需要输出艾希的中毒 ...
- MySQLDump在使用之前一定要想到的事情 [转载]
转载于:http://blog.itpub.net/29254281/viewspace-1392757/ MySQLDump经常用于迁移数据和备份. 下面创建实验数据,两个数据库和若干表create ...
- eclipse 闪退原因
电脑关机后 重启发现eclipse竟然打不开了,打开出现闪退,原因是: 1.JDK版本不一致,或者你电脑上安装了多个版本: 2.环境变量:安装了其他软件比如:oracle 它自带有一个较低版本的JDK ...
- 013、BOM对象的应用
BOM结构图如下: DOM结构图如下: BOM和DOM BOM,Bowser Object Model浏览器对象模型.提供了访问和操作浏览器各组件的途径或方法. 比如:Navigator对象:浏览器的 ...
- Implicit Animations 默认动画 读书笔记
Implicit Animations 默认动画 读书笔记 Do what I mean, not what I say. Edna Krabappel, The Simpsons Part I ...
- Android(java)学习笔记156:开源框架post和get方式提交数据(qq登录案例)
1. 前面提到Http的get/post方式 . HttpClient方式,实际工作的时候不常用到,因为这些方式编写代码是很麻烦的 2. Android应用会经常使用http协议进行传输,网上会有很 ...
- k8s集群部署之环境介绍与etcd数据库集群部署
角色 IP 组件 配置 master-1 192.168.10.11 kube-apiserver kube-controller-manager kube-scheduler etcd 2c 2g ...
- docker 框架概述
docker的框架 docker 使用传统的client-server架构模式,用户端通过docker client 与docker daemon 建立通信,并将请求发送给后者,而docker后端时 ...