B树、B-树、B+树、B*树介绍,和B+树更适合做文件索引的原因
今天看数据库,书中提到:由于索引是采用 B 树结构存储的,所以对应的索引项并不会被删除,经过一段时间的增删改操作后,数据库中就会出现大量的存储碎片, 这和磁盘碎片、内存碎片产生原理是类似的,这些存储碎片不仅占用了存储空间,而且降低了数据库运行的速度。如果发现索引中存在过多的存储碎片的话就要进行 “碎片整理”了,最方便的“碎片整理” 手段就是重建索引, 重建索引会将先前创建的索引删除然后重新创建索引,主流数据库管理系统都提供了重建索引的功能,比如 REINDEX、REBUILD 等,如果使用的数据库管理系统没有提供重建索引的功能,可以首先用DROP INDEX语句删除索引,然后用ALTER TABLE 语句重新创建索引。
对B树的概念比较陌生,网上一搜才知道,原来是 binary search tree(二叉搜索树),贴上全文!
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
3.非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:

B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字;
如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:

但B树在经过多次插入与删除后,有可能导致不同的结构:

右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;
实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
B-树
B-tree,即B树,而不要读成B减树,它是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2,
M];
3.除根结点以外的非叶子结点的儿子数为[M/2,
M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1],
K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1],
P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],
K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
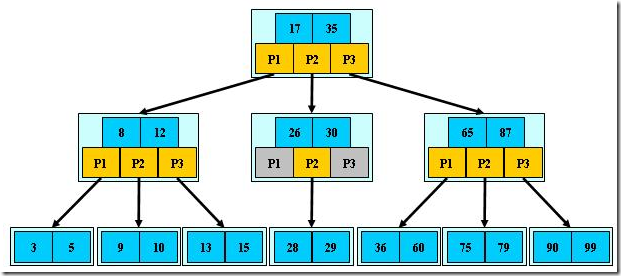
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能为:
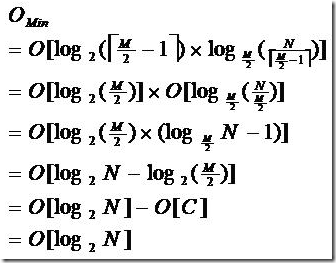
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i],
K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
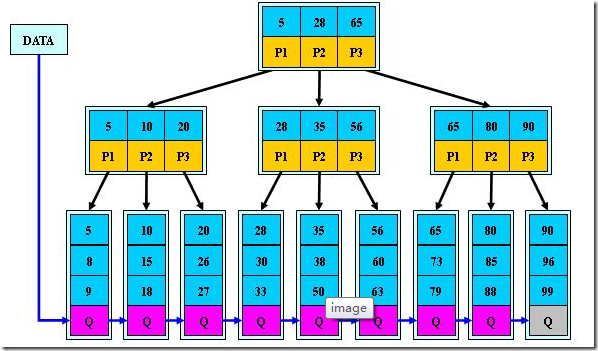
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
原因:
(2)增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
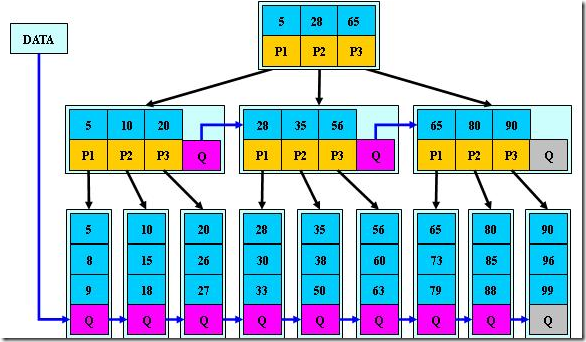
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
它更适合文件索引系统;
相对于B树,(1)B+树空间利用率更高,因为B+树的内部节点只是作为索引使用,而不像B-树那样每个节点都需要存储硬盘指针。
(2)增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
B树、B-树、B+树、B*树介绍,和B+树更适合做文件索引的原因的更多相关文章
- 树:BST、AVL、红黑树、B树、B+树
我们这个专题介绍的动态查找树主要有: 二叉查找树(BST),平衡二叉查找树(AVL),红黑树(RBT),B~/B+树(B-tree).这四种树都具备下面几个优势: (1) 都是动态结构.在删除,插入操 ...
- 为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
B树: B+树 1) B+-tree的磁盘读写代价更低 B+-tree的内部结点并没有指向关键字具体信息的指针.因此其内部结点相对B 树更小.如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所 ...
- 树链剖分的一种妙用与一类树链修改单点查询问题的时间复杂度优化——2018ACM陕西邀请赛J题
题目描述 有一棵树,每个结点有一个灯(初始均是关着的).每个灯能对该位置和相邻结点贡献1的亮度.现有两种操作: (1)将一条链上的灯状态翻转,开变关.关变开: (2)查询一个结点的亮度. 数据规模:\ ...
- LOJ2269 [SDOI2017] 切树游戏 【FWT】【动态DP】【树链剖分】【线段树】
题目分析: 好题.本来是一道好的非套路题,但是不凑巧的是当年有一位国家集训队员正好介绍了这个算法. 首先考虑静态的情况.这个的DP方程非常容易写出来. 接着可以注意到对于异或结果的计数可以看成一个FW ...
- 有趣的线段树模板合集(线段树,最短/长路,单调栈,线段树合并,线段树分裂,树上差分,Tarjan-LCA,势能线段树,李超线段树)
线段树分裂 以某个键值为中点将线段树分裂成左右两部分,应该类似Treap的分裂吧(我菜不会Treap).一般应用于区间排序. 方法很简单,就是把分裂之后的两棵树的重复的\(\log\)个节点新建出来, ...
- 【bzoj4771】七彩树 树链的并+STL-set+DFS序+可持久化线段树
题目描述 给定一棵n个点的有根树,编号依次为1到n,其中1号点是根节点.每个节点都被染上了某一种颜色,其中第i个节点的颜色为c[i].如果c[i]=c[j],那么我们认为点i和点j拥有相同的颜色.定义 ...
- 表达式树练习实践:C# 五类运算符的表达式树表达
目录 表达式树练习实践:C# 运算符 一,算术运算符 + 与 Add() - 与 Subtract() 乘除.取模 自增自减 二,关系运算符 ==.!=.>.<.>=.<= 三 ...
- B+树比B树更适合实际应用中操作系统的文件索引和数据库索引
B+树比B树更适合实际应用中操作系统的文件索引和数据库索引 为什么选择B+树作为数据库索引结构? 背景 首先,来谈谈B树.为什么要使用B树?我们需要明白以下两个事实: [事实1]不同容量的存储器, ...
- 《机器学习Python实现_10_10_集成学习_xgboost_原理介绍及回归树的简单实现》
一.简介 xgboost在集成学习中占有重要的一席之位,通常在各大竞赛中作为杀器使用,同时它在工业落地上也很方便,目前针对大数据领域也有各种分布式实现版本,比如xgboost4j-spark,xgbo ...
随机推荐
- vs2017 + miniUI + dapper 添加、修改、删除、查询操作
A.数据库表引用先前建立的company 公司信息表. B.建立文件: views > Home > Company.cshtml(新建文件) ,代码如下(直接复制即可) @{ Layou ...
- 【Tair】淘宝分布式NOSQL框架:Tair
Tair是淘宝的一个开源项目,它是一个分布式的key/value结构数据的解决方案. 一.基本组成 作为一个分布式系统,Tair由一个中心控制节点(config server)和一系列的服务节点(da ...
- 清理TIME_WAIT
cat >> /etc/sysctl.conf << EOFnet.ipv4.tcp_tw_reuse=1net.ipv4.tcp_tw_recycle=1net.ipv4.t ...
- List 的属性与方法整理
List<T> 类与 ArrayList 类比较类似.它实现了 IList<T> 泛型接口,长度可以动态增加. 可以使用 Add 或 AddRange 方法将项添加到 List ...
- python获取主机名和用户名
import socketimport getpassuser_name = getpass.getuser() # 获取当前用户名hostname = socket.gethostname() # ...
- JSP&&EL&&JSTL
JSP = JAVA + HTML + JSP自身的东西 JSP的脚本 <%! %> :翻译成Servlet中的成员内容. 定义变量,方法,类. -- ...
- Java编程思想读书笔记_第8章
覆盖私有方法 class Father { private void f() { System.out.println("Father::f()"); } public stati ...
- from scipy import spatial 出现 from .qhull import * ImportError: DLL load failed: The specified module could not be found. 错误
错误描述: 本人机器window8.1 64位,python2.7. Traceback (most recent call last): File "C:/Users/Hamid/Docu ...
- P1823 音乐会的等待
题目描述 N个人正在排队进入一个音乐会.人们等得很无聊,于是他们开始转来转去,想在队伍里寻找自己的熟人.队列中任意两个人A和B,如果他们是相邻或他们之间没有人比A或B高,那么他们是可以互相看得见的. ...
- switch-case用法
1.switch-case 一般的用它来做值匹配的. //匹配 就是全等. /* 语法: switch(表达式){ case 值1: 表达式的值和 值1匹配上了,需要执行的代码; break; cas ...